MotiF:通过引导模型关注更多运动区域来改善文本对齐和运动生成文本-图像到视频生成(TI2V) 是一项旨在根据文本描述从静态图像生成动态视频的技术。尽管这一领域已经取得了一定进展,但现有方法在生成与文本提示良好对齐的视频时仍面临显著挑战,尤其是在指定运动细节方面...新技术# MotiF# 图生视频1年前03670
无需图像数据的方法Diff-Instruct*(DI*):用于构建符合人类偏好的一步式文生图模型,同时保持生成高度逼真图像的能力北京大学、小红书和卡内基梅隆大学的研究人员推出一种无需图像数据的方法Diff-Instruct*(DI*),用于构建符合人类偏好的一步式文本到图像生成模型,同时保持生成高度逼真图像的能力。研究团队将人...新技术# Diff-Instruct*(DI*)# 一步式文生图模型1年前02890
基于扩散模型的创新框架3DHM:根据单张图片和目标3D动作序列来生成人物动画加州大学伯克利分校的研究人员提出了一种创新的框架——3DHM(3D Human Motion),该框架利用扩散模型从单张图像中根据给定的目标3D运动序列生成高质量的人物动画。这一方法的核心在于解耦人体...新技术# 3DHM# 人物动画1年前02550
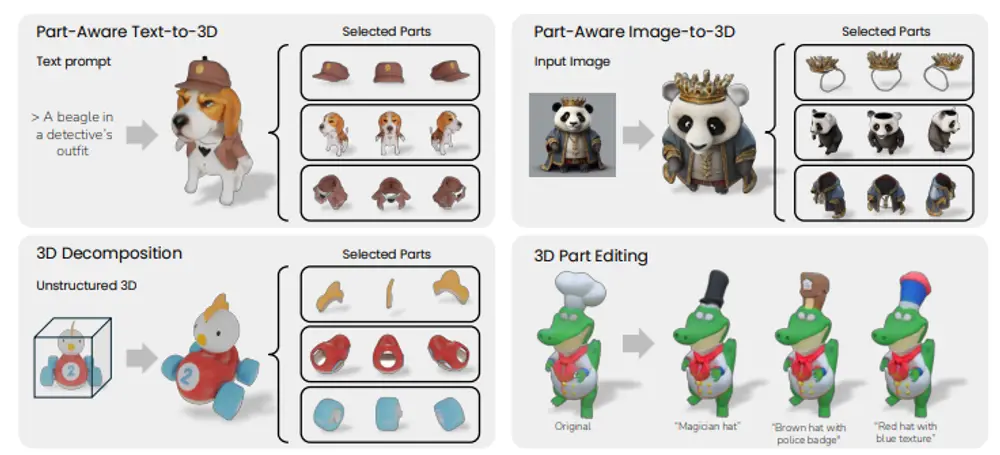
3D对象生成和重建流程PartGen:可以从文本、图像或非结构化3D对象开始,生成由多个有意义部分组成的3D对象近年来,文本到3D生成器和3D扫描仪技术取得了显著进展,能够生成高质量的3D资产。然而,这些资产通常由单一的融合表示组成,例如隐式神经场、高斯混合或网格,缺乏任何有用的结构。这种单一表示方式使得资产难...新技术# 3D对象# PartGen1年前04710
基于图像扩散先验的深度修复模型DepthLab:从单张图像中生成完整的3D场景香港大学、香港科技大学、蚂蚁集团、阿尔托大学和通义实验室的研究人员推出DepthLab ,它是一个基于图像扩散先验的深度修复模型,用于从单张图像中生成完整的3D场景。DepthLab旨在解决深度数据中...新技术# 3D场景# DepthLab# 深度修复模型1年前03180
新型视频变分自编码器VideoVAE+:实现高保真视频编码随着多媒体内容的增长,学习一个鲁棒的视频变分自编码器(VAE)对于减少视频冗余和促进高效视频生成变得越来越重要。直接将图像VAE应用于单个帧可能会导致时间不一致性和次优压缩率,因为缺乏对时间维度的有效...新技术# VideoVAE+1年前02710
蒸馏解码DD:用于加速自回归(AR)模型在图像和文本生成任务中的采样步骤自回归(AR)模型在文本和图像生成方面取得了显著的进展,但其逐令牌生成的过程导致了速度上的局限性。为了克服这一问题,清华大学和微软研究院的研究人员提出了一项雄心勃勃的任务:能否将预训练的AR模型调整为...新技术# 自回归模型# 蒸馏解码1年前02580
前馈单图像人体重建框架IDOL:能够从单张图片中快速创建出高保真度、可动画化的3D全身人物形象南京大学、中国科学院深圳先进技术研究院、清华大学、腾讯和深圳理工大学的研究人员共同推出了IDOL(Image-based Detailed and Optimized Avatar),这是一个具有快速...新技术# IDOL1年前02790
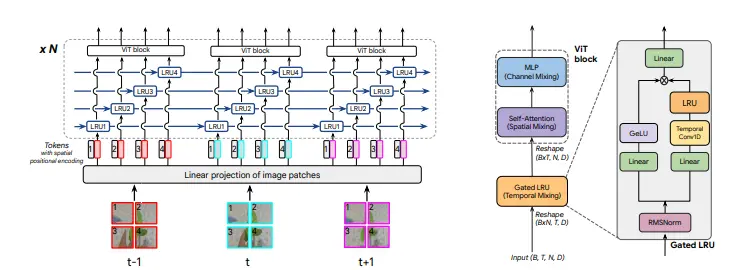
新型视频建模架构TRecViT:结合了时间序列处理和空间特征提取的优势,以提高视频理解任务的性能Google DeepMind发布一种新型的视频建模架构TRecViT(Temporal Recurrent Video Transformer)。这个架构是一种混合模型,它结合了时间序列处理和空间特...新技术# TRecViT# 视频建模架构1年前03290
类卷积局部注意力策略CLEAR:提升FLUX模型在高分辨率图像生成任务中的效率在图像生成领域,DiT(Diffusion Transformer)架构凭借其卓越的表现成为前沿技术。然而,该架构的核心——用于建模令牌间关系的注意力机制,由于其计算复杂度为二次方,导致在处理高分辨率...新技术# CLEAR# FLUX模型1年前03640
并行自回归视觉生成方法PAR:通过并行生成视觉标记来加速图像和视频的生成过程,同时确保生成质量自回归模型在视觉生成领域表现出色,但其逐个预测token的顺序过程导致了推理速度较慢。为了解决这一问题,香港大学、字节跳动和北京大学的研究人员提出了一种简单而有效的并行自回归视觉生成方法——PAR(P...新技术# PAR1年前03340
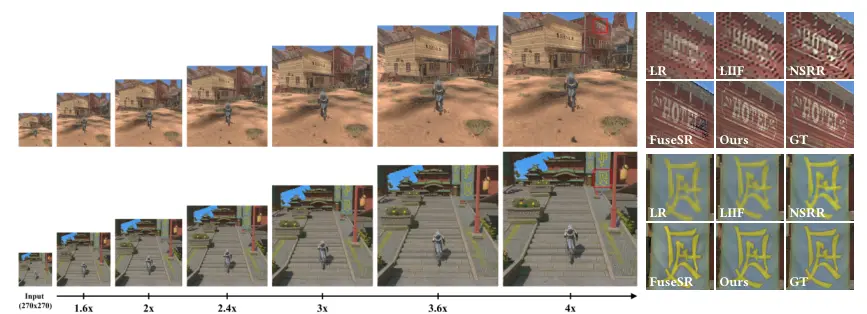
超分辨率渲染新技术框架DFASRR:实现任意比例的超分辨率渲染,以实时生成高清晰度图像南京大学计算机软件新技术国家重点实验室的研究人员介绍了一种名为“DFASRR(Deep Fourier-based Arbitrary-scale Super-resolution for Real...新技术# DFASRR# 超分辨率渲染1年前04040