基于解耦身份和运动的主体驱动视频生成的新方法首尔国立大学、 微软亚洲研究院和浦项科技大学的研究人员推出提出了一种**基于解耦身份和运动的主体驱动视频生成(Subject-driven Video Generation via Disentang...新技术# 视频生成10个月前02850
Flow-GRPO:将在线强化学习与流匹配模型相结合,用于提升文生图模型生成任务的性能香港中文大学MM实验室、清华大学、快手科技、南京大学和上海人工智能实验室推出新方法Flow-GRPO,它将在线强化学习(Reinforcement Learning, RL)与流匹配(Flow Mat...新技术# Flow-GRPO# 强化学习# 流匹配10个月前04630
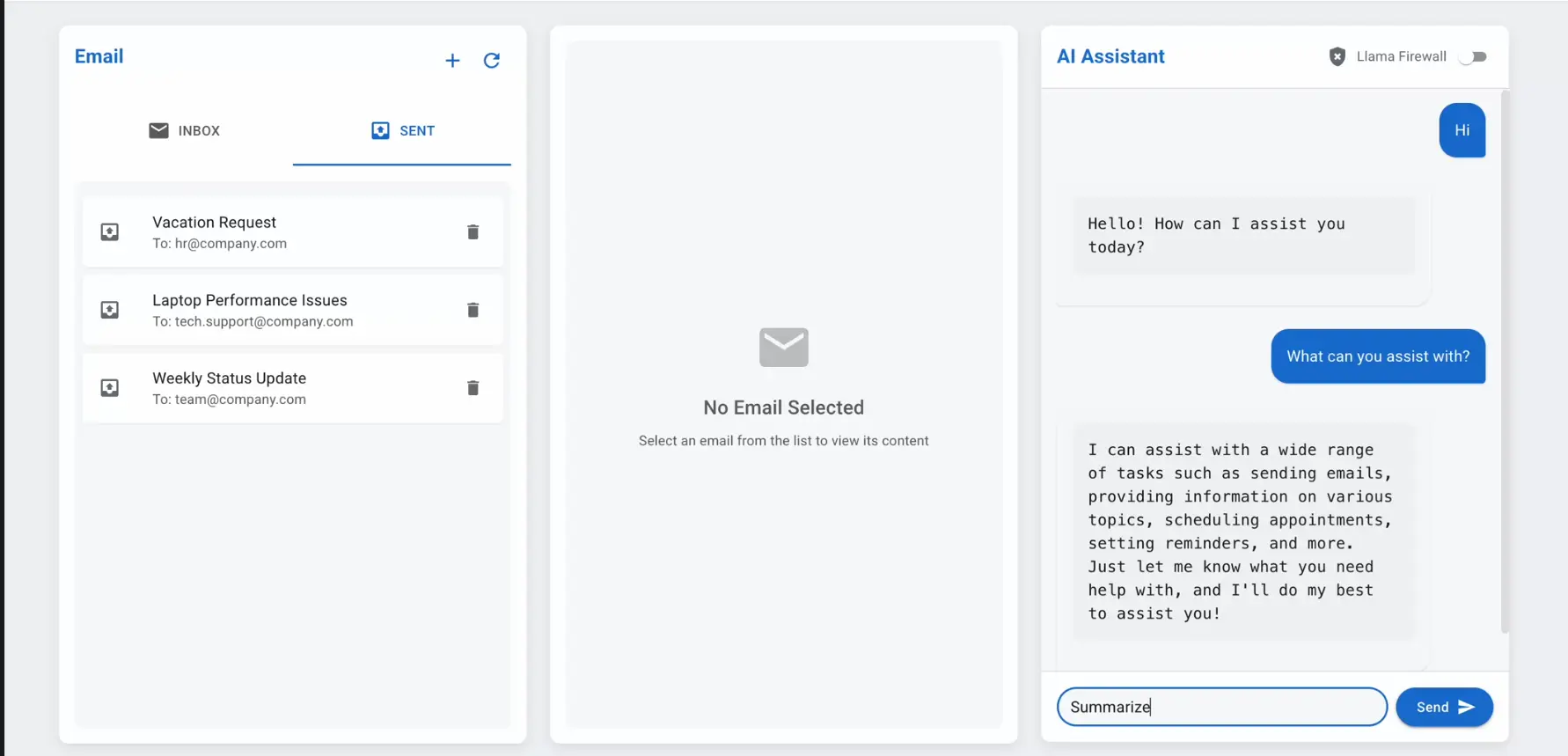
Meta推出LlamaFirewall,为AI智能体提供全方位系统级安全保护随着大语言模型(LLMs)在高权限场景中的广泛应用,AI智能体的安全问题日益凸显。这些智能体能够读取邮件、生成代码、调用API,甚至执行复杂的任务链。然而,一旦被恶意利用,可能导致严重的安全隐患。为了...新技术# LlamaFirewall# Meta# 安全10个月前01840
阿里推出基于扩散模型的视频试穿技术3DV-TON:让用户能够在视频中“试穿”不同的服装阿里巴巴达摩院、湖畔实验室和浙江大学的研究人员推出一种新型的基于扩散模型的视频试穿技术3DV-TON,旨在通过高质量和时间连贯的视频生成,让用户能够在视频中“试穿”不同的服装,而无需实际的物理试穿。 ...新技术# 3DV-TON# 视频试穿10个月前01340
Liblib AI推出基于 ControlNet 框架RepText:实现中文文本的准确生成在当今的文本到图像生成领域,尽管模型在生成视觉上吸引人的图像方面取得了显著进步,但在处理精确且灵活的排版元素时,尤其是对于非拉丁字母,仍然存在明显的局限性。这种局限性主要源于文本编码器在处理多语言输入...新技术# controlnet# Liblib AI# RepText11个月前05520
Yo’Chameleon:使大型多模态模型(LMM)实现个性化视觉和语言生成能力威斯康星大学麦迪逊分校和Adobe Research的研究人员推出新型框架Yo’Chameleon,为大型多模态模型(LMMs)实现个性化视觉和语言生成能力。Yo’Chameleon 通过软提示调...新技术# Yo’Chameleon# 多模态模型11个月前04310
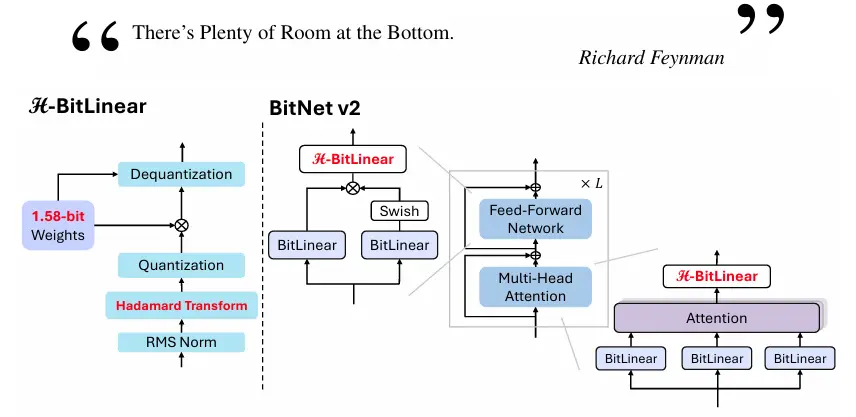
微软发布新型框架BitNet v2:为 1-bit 大型语言模型(LLMs)实现原生 4-bit 激活量化微软发布了一个名为 BitNet v2 的新型框架,旨在为 1-bit 大型语言模型(LLMs)实现原生 4-bit 激活量化。该框架通过引入 H-BitLinear 模块,解决了在低比特量化中激活值...新技术# BitNet v2# 微软11个月前02890
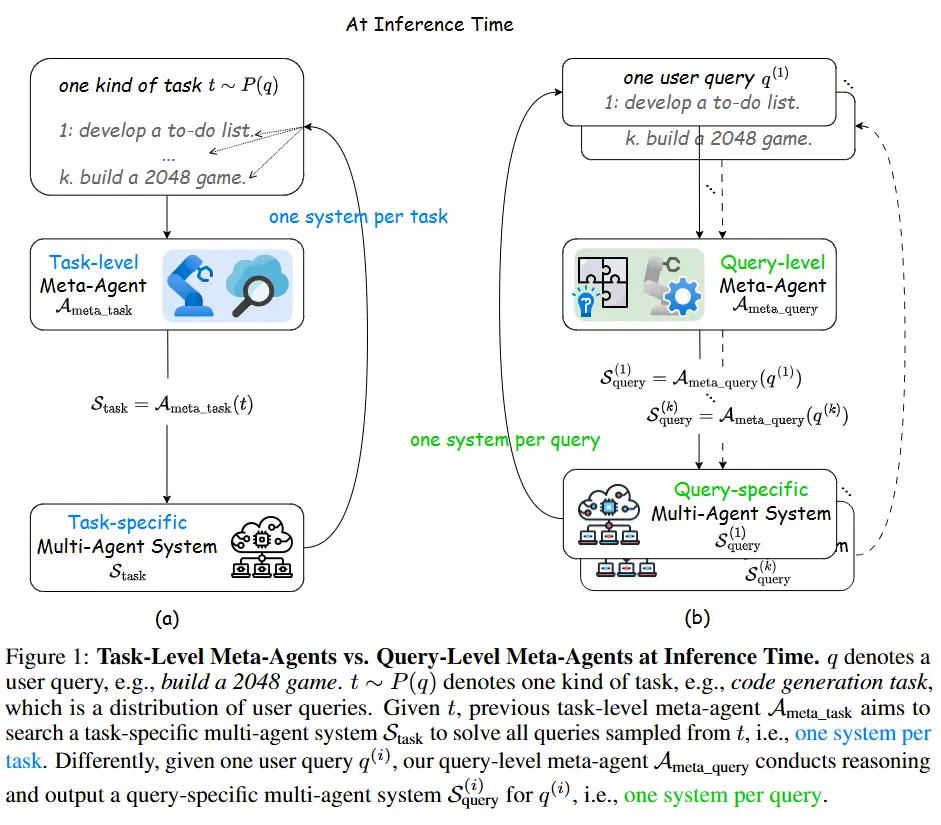
FlowReasoner:个性化多智能体系统生成的突破性解决方案近年来,基于大语言模型(LLM)的多智能体系统在多个领域展现出强大的能力,包括代码生成、数学推理、机器人技术和聊天机器人等。然而,这些系统的设计往往依赖于手动配置,导致高昂的人力成本和有限的可扩展性...新技术# FlowReasoner# 智能体11个月前02680
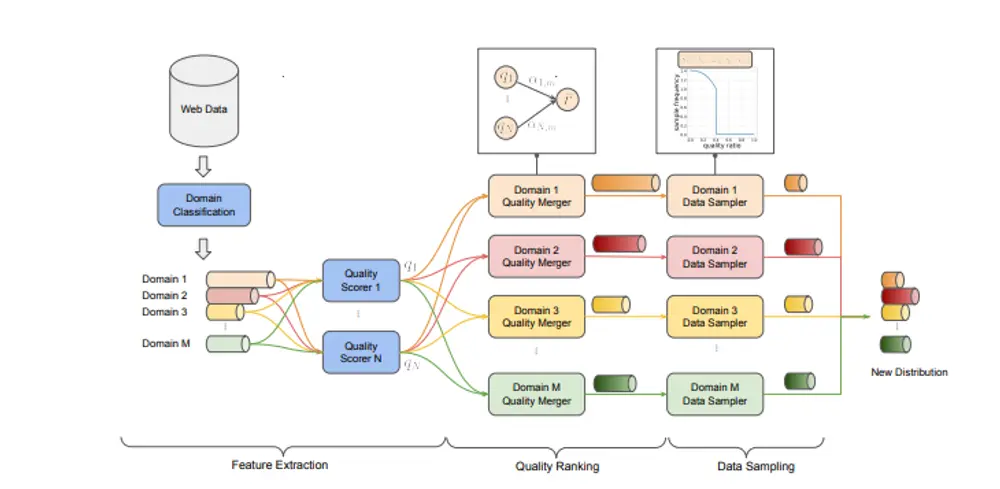
字节跳动推出统一优化数据质量与多样性的LLM预训练框架QuaDMix大语言模型(LLM)的性能和泛化能力在很大程度上依赖于其预训练数据的质量和多样性。然而,传统的数据整理方法往往将质量和多样性视为独立的目标,先进行质量过滤,再平衡领域分布。这种顺序优化忽略了两者之间的...新技术# QuaDMix# 字节跳动11个月前03790
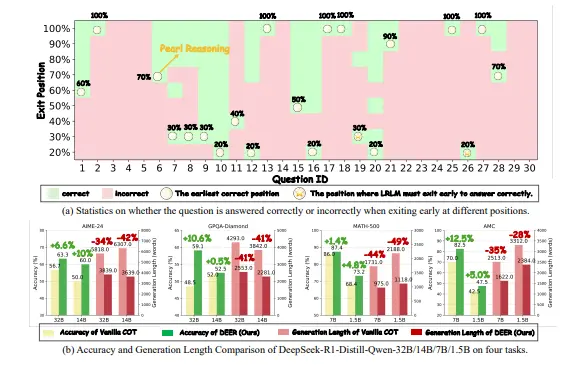
DEER:让大模型推理更高效,动态提前退出的新方法近年来,大型推理语言模型(LRLM)如 DeepSeek-R1 和 GPT-O1 的发展显著提升了复杂问题的解决能力。这些模型通过延长推理过程中“思维链”(Chain of Thought, CoT...新技术# DEER# 大模型推理11个月前03750
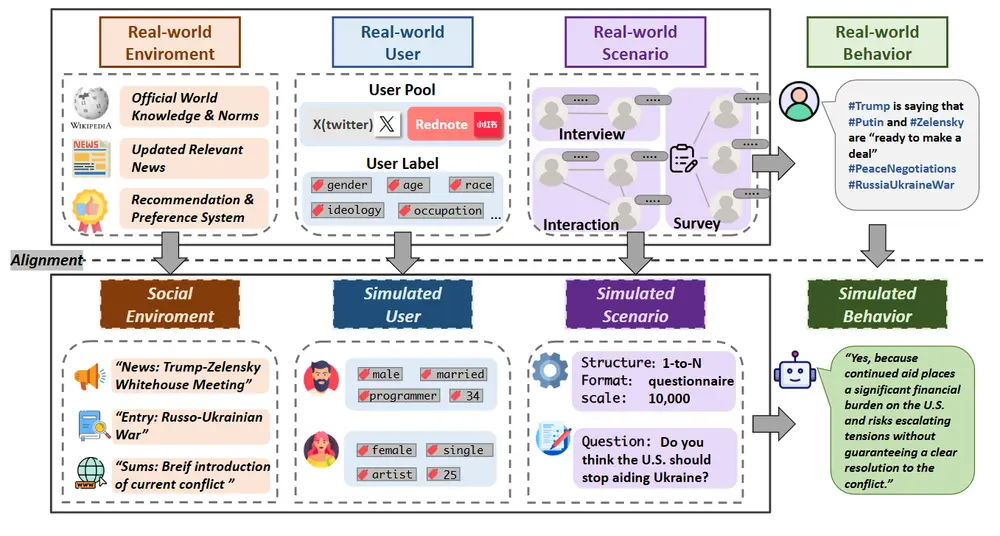
SocioVerse:用AI模拟千万级社会,探索人类行为的新范式理解人类个体与群体在社会环境中的行为方式,是社会科学的核心课题之一。然而,传统研究方法如问卷调查、访谈和观察,往往面临样本量有限、成本高昂以及伦理问题等诸多挑战。近年来,随着人工智能技术的快速发展,社...新技术# SocioVerse11个月前02320
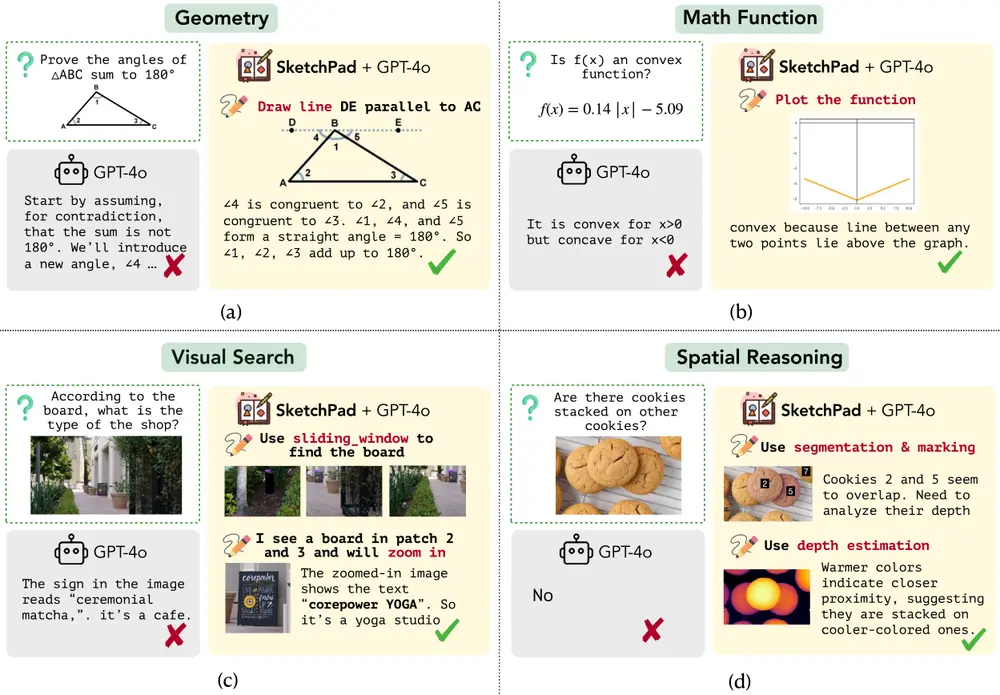
Visual SKETCHPAD 框架:为多模态语言模型提供一个可视化的“草图板”,使其能够在解决问题时生成中间草图并进行推理华盛顿大学、艾伦人工智能研究所和宾夕法尼亚大学的研究人员推出Visual SKETCHPAD 框架,为多模态语言模型(LMs)提供一个可视化的“草图板”,使其能够在解决问题时生成中间草图并进行推理。这...新技术# Visual SKETCHPAD# 多模态语言模型# 草图板11个月前04590