
近年来,大型推理语言模型(LRLM)如 DeepSeek-R1 和 GPT-O1 的发展显著提升了复杂问题的解决能力。这些模型通过延长推理过程中“思维链”(Chain of Thought, CoT)的生成长度,能够挖掘更多元化的推理路径。然而,这种长链推理也带来了计算效率低下和延迟增加的问题,尤其是在现实世界应用中,过长的推理链不仅浪费资源,还可能引入冗余甚至错误信息,导致结果偏离正确答案。
为了解决这一问题,中国科学院信息工程研究所、中国科学院大学与华为技术有限公司的研究团队提出了一种全新的无训练方法——DEER(Dynamic Early Exit in Reasoning,推理中的动态提前退出)。该方法通过在推理过程中动态识别最佳停止点,实现了效率和准确性的双重提升。
核心思路:动态监控与提前退出
DEER 的核心思想是,在推理过程中实时评估模型对当前试验性答案的置信度,并根据置信度决定是否提前退出推理。这种方法无需额外训练或依赖外部验证模型,完全兼容现有架构,是一种轻量级且高效的解决方案。
工作原理
DEER 通过三个模块协作完成动态提前退出:
推理转换监视器
监控推理过程中的关键转换信号(如特定标记的生成),判断是否进入“思维转换”阶段。答案诱导器
在检测到转换信号时,提示模型生成一个试验性答案。置信度评估器
评估模型对试验性答案的置信度。如果置信度超过预设阈值,则停止推理;否则继续生成后续推理步骤。
为了进一步优化性能,DEER 引入了分支并行解码和动态缓存管理机制,以减少试验性答案生成带来的延迟,同时提高整体推理效率。
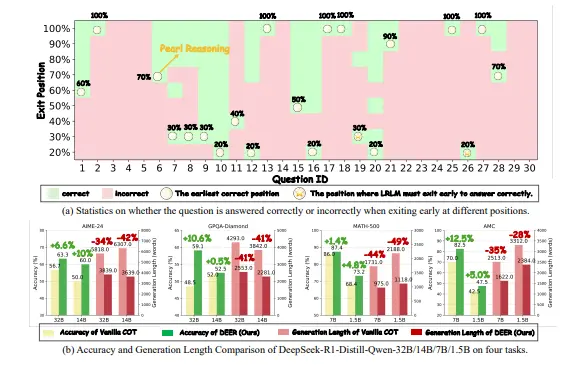
实验验证:显著减少推理长度,提升准确性
研究团队在多个主流推理基准测试和编程任务上验证了 DEER 的有效性。实验涵盖了 MATH-500、AMC 2023、AIME 2024 和 GPQA Diamond 等推理任务,以及 HumanEval 和 BigCodeBench 等编程任务。
主要成果
推理长度大幅缩减
在所有测试中,DEER 将 CoT 长度减少了 31%–43%,同时将准确性提高了 1.7%–5.7%。这表明,模型能够在更短的推理路径中达到更高的精度。编程任务表现尤为突出
在代码生成任务中,DEER 将推理长度减少了 60% 以上,而准确性几乎没有损失,证明了其在多样化任务中的鲁棒性。小模型和简单任务收益更大
对于较小规模的模型和较简单的任务,DEER 提前退出的效果更加显著,纠正了更多的错误响应,展现了强大的适应性。
优势与创新点
相比现有的方法,DEER 具备以下几个显著优势:
无需训练
DEER 是一种无训练方法,完全基于现有模型的能力实现动态退出,避免了额外的训练成本和过拟合风险。无缝集成
方法设计简洁,可直接应用于现有 LRLM 模型(如 DeepSeek-R1),无需对模型架构进行修改。高效平衡性能与效率
通过动态监控模型置信度,DEER 能够在保证准确性的前提下显著减少推理长度,从而提升计算效率。广泛适用性
无论是在数学推理、逻辑推导还是代码生成等任务中,DEER 都展现出了强大的通用性和鲁棒性。
未来展望:进一步优化与扩展
尽管 DEER 已经取得了显著成果,但研究团队指出,仍有改进空间。例如:
探索更精细的置信度评估策略,以进一步提升提前退出的准确性; 扩展到更多样化的任务场景,验证其在跨领域任务中的表现; 结合强化学习等技术,进一步优化推理路径的选择。
此外,DEER 的成功也为未来研究提供了一个重要方向:如何通过动态调整推理过程来最大化模型效率,同时保持甚至提升性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











