语音驱动人脸说话生成框架AVCT来自网易伏羲AI实验室、悉尼科技大学的研究人员推出了从单人音频生成单人说话脸部的框架Audio-Visual Correlation Transformer (AVCT),它能够从单个说话者的音频-视...新技术# AVCT2年前08280
新型图像生成蒸馏模型LinFusion:利用文本提示生成高分辨率的图像新加坡国立大学学习与视觉实验室的研究人员推出新型图像生成模型LinFusion,它能够利用文本提示生成高分辨率的图像。LinFusion的核心在于它采用了一种新颖的线性注意力机制,这使得它在处理大量像...新技术# LinFusion# 蒸馏模型2年前08260
多模态大语言模型LITA:专门设计来处理视频中的时间定位问题英伟达推出多模态大语言模型LITA(Language Instructed Temporal-Localization Assistant),它专门设计来处理视频中的时间定位问题。 GitHub 论文...新技术# LITA# 多模态大语言模型2年前08260
新型视频生成框架ConFiner:结合多个专家模型的能力,以一种高效且无需训练的方式,生成高质量且连贯的视频内容悉尼大学、东南大学、中南大学、上海交通大学、商汤科技研究院和香港科技大学的研究人员推出新型视频生成框架ConFiner,它通过一系列现成的扩散模型专家(diffusion model experts...新技术# ConFiner# 视频生成2年前08250
新型实时一步潜在扩散模型SDXS:在图像生成任务中显著提高效率,同时保持图像质量小米推出新型实时一步潜在扩散模型SDXS,它能够在图像生成任务中显著提高效率,同时保持图像质量。SDXS模型通过模型小型化和减少采样步骤的双重方法,显著降低了模型的延迟,使其能够在低功耗设备上实时生成...新技术# SDXS# 一步潜在扩散模型1年前08250
Meta推出多模态基础模型家族Chameleon:专为理解和生成图像与文本而设计Meta推出多模态基础模型家族Chameleon,它们是专为理解和生成图像与文本而设计,多模态意味着这些模型能够同时处理多种类型的数据,比如图片和文字。例如,你给Chameleon一个描述或者一张图片...新技术# Chameleon# Meta# 多模态基础模型2年前08240
微调模型TCD:提高图像生成的速度和质量来自华南理工、南洋理工、北理工和悉尼大学的研究人员推出TCD(Trajectory Consistency Distillation),这是一种用于加速文生图模型图像生成的微调模型。TCD的目标是提高...新技术# TCD# 微调模型2年前08190
文生视频模型VSTAR:解决现有开源T2V模型难以生成内容动态变化和较长视频的问题来自博世人工智能中心、曼海姆大学、马克斯·普朗克信息学研究所和图宾根大学的研究团队推出VSTAR,这是一种用于生成动态视频的文本到视频(T2V)合成技术。VSTAR的目标是解决现有开源T2V模型难以生...新技术# VSTAR# 文生视频模型2年前08160
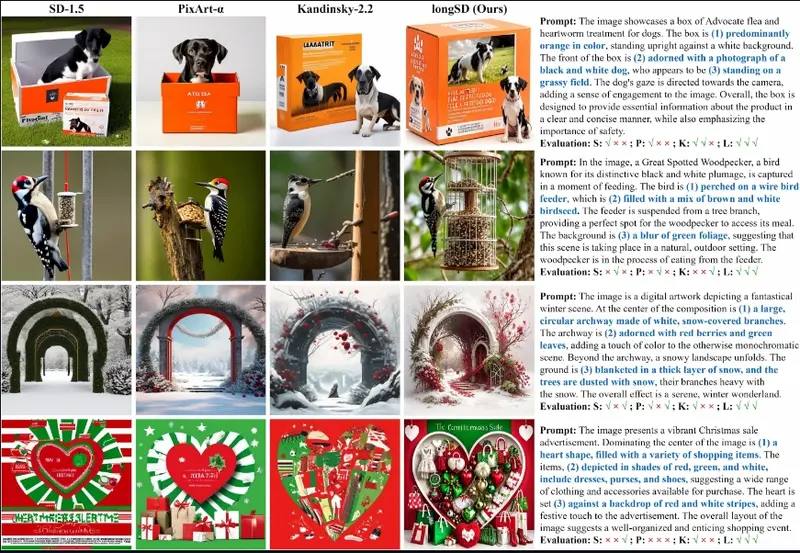
LongAlign:改进文生图模型的长文本对齐文生图模型的快速发展使它们能够从给定的文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法如 CLIP 面临限制,并且将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,香港大学、新加...新技术# LongAlign# 文生图模型# 长文本对齐1年前08140
EmoKnob:允许在语音合成中对任意情感进行细粒度控制的框架哥伦比亚大学的研究人员推出一个允许在语音合成中对任意情感进行细粒度控制的框架EmoKnob,它用于提升语音克隆技术,只需少量示 范样本,允许用户在语音合成中精细控制情感及其强度。简单来说,EmoKno...新技术# EmoKnob# 语音克隆1年前08140
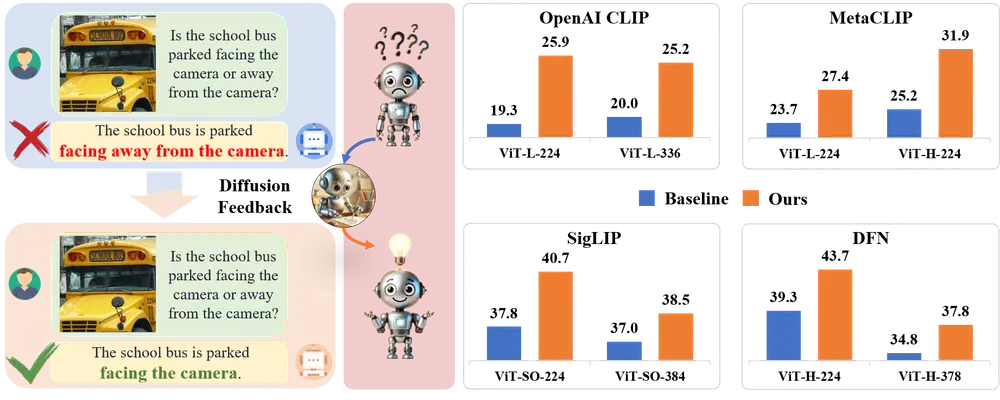
新型AI方法DIVA:使用扩散模型作为 CLIP 视觉辅助中国科学院自动化研究所、中国科学院大学人工智能学院、北京人工智能研究院 和北京交通大学的研究人员推出新型人工智能方法DIVA,它旨在提升一种流行的图像和语言联合预训练模型CLIP的视觉识别能力。CLI...新技术# CLIP 视觉辅助# DIVA2年前08080
新型3D生成算法MicroDreamer:能够在大约20秒内生成高质量的3D模型,而无需任何3D数据来自中国人民大学、清华大学和快手的研究人员推出新型3D生成算法MicroDreamer,它能够在大约20秒内生成高质量的3D模型,而无需任何3D数据。这项技术基于一种称为“基于分数的迭代重建”(Sco...新技术# 3D生成算法# MicroDreamer2年前08080