字节跳动推出基于修正流Transformer 架构的新型图像和视频生成模型家族Goku香港大学和字节跳动的研究人员推出新型图像和视频生成模型家族Goku,它基于修正流Transformer 架构,实现了行业领先的图像和视频联合生成性能。Goku 的目标是通过高质量的视觉内容生成,推动媒...视频模型# Goku# 字节跳动# 视频生成1年前05080
字节跳动推出新型身份保持视频生成方法EchoVideo字节跳动推出新型身份保持视频生成方法EchoVideo ,旨在通过多模态特征融合解决传统方法中存在的“复制粘贴”现象和身份相似度低的问题。该方法能够生成高质量、连贯且一致的视频内容,同时保持人物的身份...新技术# EchoVideo# 视频生成1年前02580
新型视频生成框架GS-DiT:通过伪4D高斯场实现对视频内容的精确4D控制香港中文大学多媒体实验室、博智感知交互研究中心和Avolution AI的研究人员推出新型视频生成框架GS-DiT,旨在通过伪4D高斯场实现对视频内容的精确4D控制。GS-DiT通过构建伪4D高斯场并...新技术# GS-DiT# 视频生成1年前03690
新型3D感知视频扩散方法DaS:实现对视频生成过程的多样化和精确控制香港科技大学、浙江大学、香港大学、南洋理工大学、武汉大学和德克萨斯农工大学的研究人员推出新型3D感知视频扩散方法“Diffusion as Shader(DaS)”,旨在实现对视频生成过程的多样化和精...新技术# DaS# 视频生成1年前03160
基于扩散模型的人类视频生成框架AnchorCrafter:用于创建高保真度的主播风格产品推广视频。自动生成锚点风格的产品推广视频在在线商务、广告和消费者互动中展现出巨大的潜力。然而,尽管姿态引导的人类视频生成技术取得了显著进展,这一任务仍然充满挑战。特别是将人-物交互(Human-Object I...新技术# AnchorCrafter# 视频生成1年前03100
Free^2Guide:无梯度框架提升文本到视频(T2V)生成中的文本对齐扩散模型在文本到图像(T2I)和文本到视频(T2V)合成等生成任务中取得了显著成果。然而,在T2V生成中,实现准确的文本对齐仍然是一个具有挑战性的问题,尤其是在处理帧间复杂的时序依赖性时。现有的基于强...新技术# Free^2Guide# 视频生成1年前03150
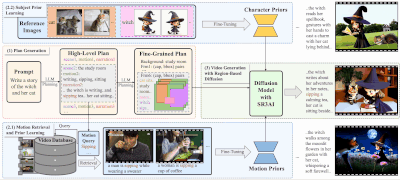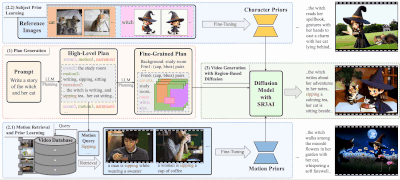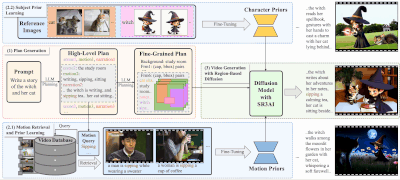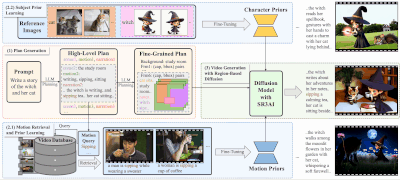
新型故事视频生成框架DreamRunner:根据文本脚本生成长篇、多动作、多场景的视频,适用于CogVideoX模型故事讲述视频生成(SVG)是一项旨在从文本脚本创建长时间、多动作、多场景视频的任务。这种技术在媒体和娱乐领域的内容创作中具有巨大潜力,但同时也面临着诸多挑战,包括但不限于: 物体需要展示一系列精细、复...新技术# DreamRunner# 视频生成1年前03440
统一的控制视频生成方法AnimateAnything:实现对视频内容的精确和一致性的操控,包括相机轨迹、文本提示和用户运动注释等多种条件视频生成是一个复杂而多样的任务,涉及多个条件的控制,如摄像机轨迹、文本提示和用户运动注释。现有的方法通常只能在特定条件下生成视频,缺乏灵活性和一致性。为了解决这些问题,浙江大学 CAD&CG ...新技术# AnimateAnything# 视频生成1年前03520
可控图像到视频生成框架SG-I2V:用于在图像到视频的生成过程中实现对象和相机运动的控制图像到视频生成技术已经取得了显著的进步,能够生成高度逼真的视频。然而,调整生成视频中的特定元素,如物体运动或相机移动,通常需要繁琐的试错过程,例如使用不同的随机种子重新生成视频。最近的技术通过微调预训...新技术# SG-I2V# 视频生成1年前04760
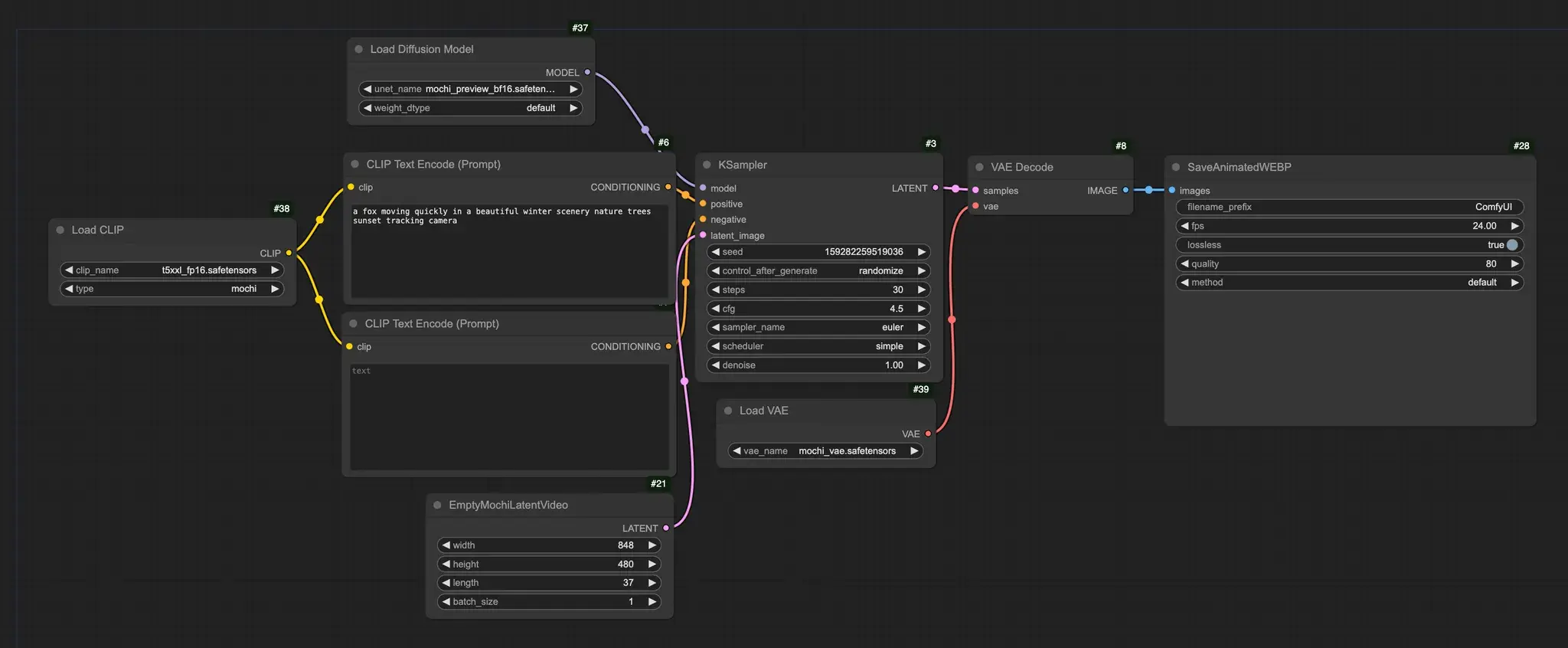
ComfyUI原生支持视频生成模型Mochi,12G显存即可进行生成随着技术的不断进步,视频生成领域也在持续创新。近日,ComfyUI 在其最新的 v0.2.7 版本中加入了对 Mochi 模型的原生支持,这标志着 ComfyUI 社区迎来了一次重大升级,即便是使用消...工作流# ComfyUI# Mochi# 视频生成1年前05100
Meta推出创新方案AdaCache(自适应缓存):不进行额外训练的情况下加速视频生成视频生成是AI研究的一个热点领域,特别是在生成时间上一致、高保真的视频方面。这一领域涉及创建在帧之间保持视觉连贯性并在时间上保留细节的视频序列。近年来,机器学习模型,尤其是扩散变换器(DiTs),已成...新技术# AdaCache# Meta AI# 自适应缓存1年前03960
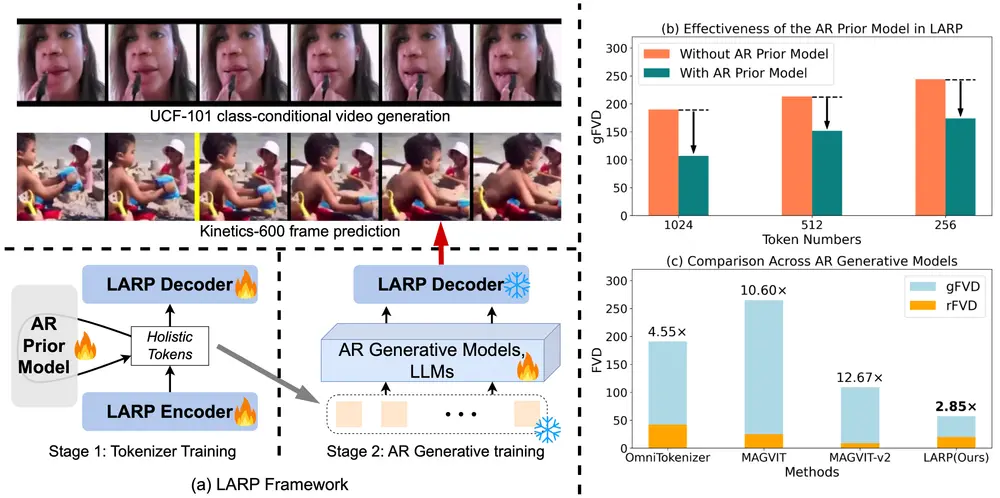
新型视频分词器LARP:专为自回归(AR)生成模型设计,用于提高视频生成任务的性能马里兰大学学院公园分校的研究人员提出了一种名为LARP(Latent Aggregation and Refinement for Perception)的新型视频分词器,它专为自回归(AR)生成模型...新技术# LARP# 视频分词器# 视频生成1年前04190