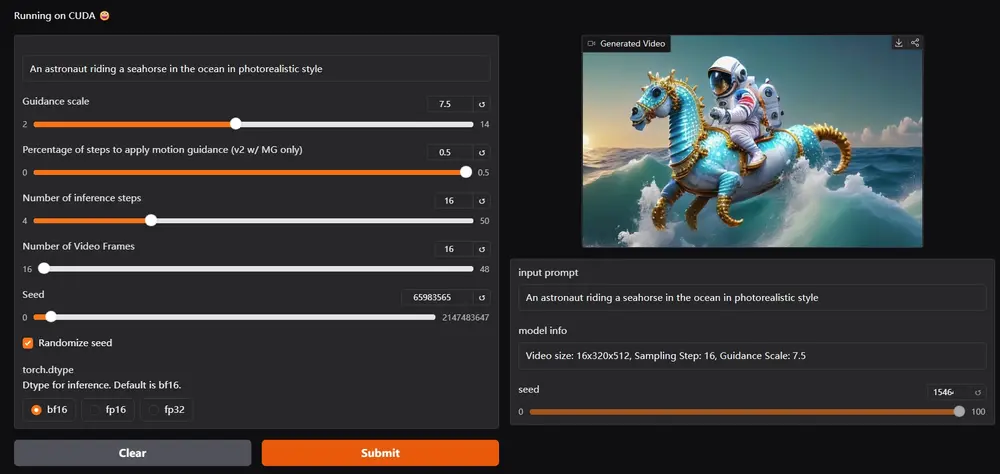
Wan2.2 视频生成模型ComfyUI 官方原生工作流发布,官方完整配置及使用指南阿里云通义实验室推出的 Wan2.2 视频生成模型已全面支持 ComfyUI,并提供官方原生工作流模板。 Wan2.2 模型采用创新的 MoE架构,由高噪专家模型和低噪专家模型组成,能够根据去噪时间步...工作流# Wan2.2# 视频生成模型8个月前05,4380
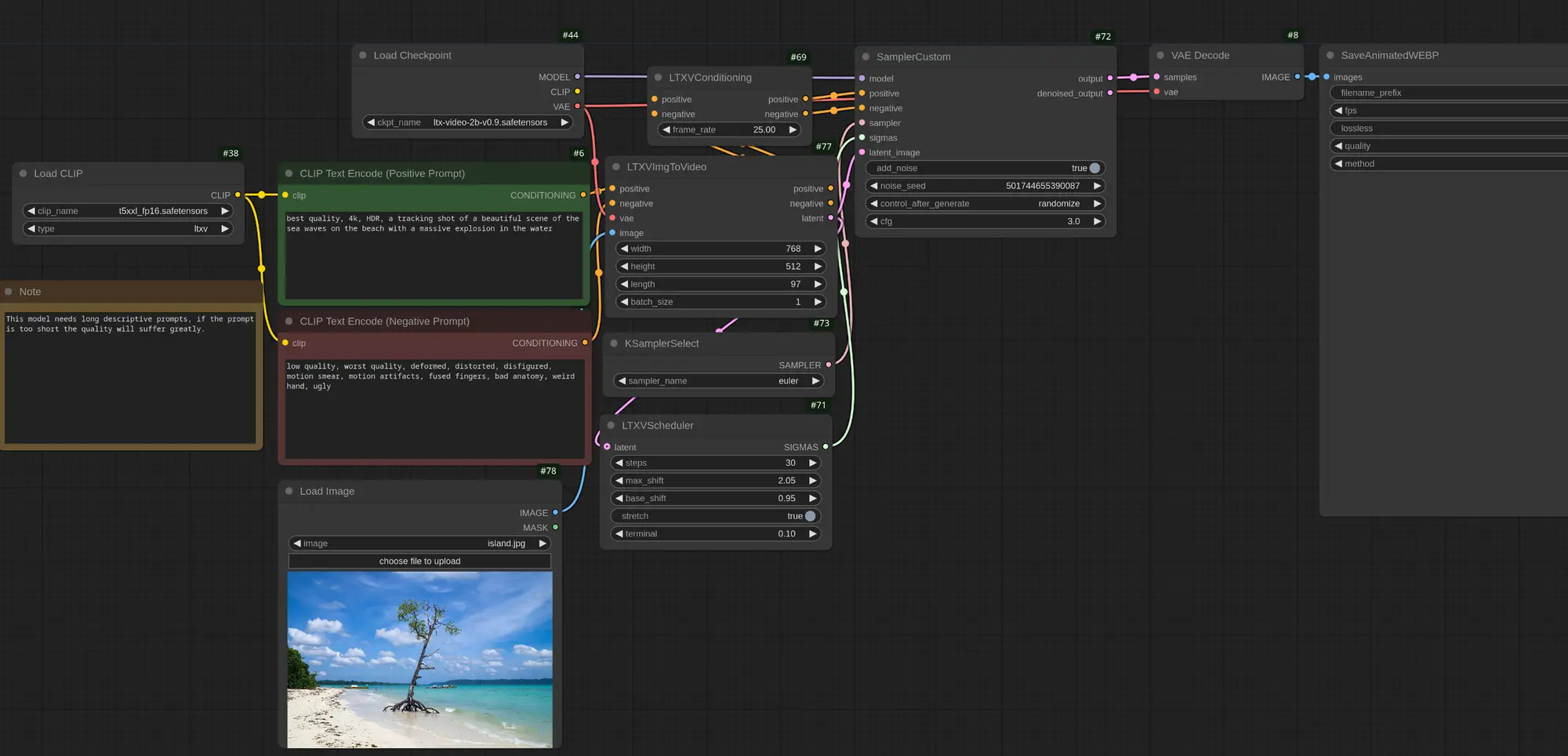
Lightricks推出开源视频生成模型LTX Video,ComfyUI 已原生支持Lightricks隆重推出全新的开源、社区驱动的视频生成模型LTX Video,ComfyUI也在第一时间宣布支持该模型,LTX-Video 是一个仅20亿参数的基于DiT的视频生成模型,能够实时生...工作流# ComfyUI# Lightricks# LTX Video1年前03,0250
用于生成长视频的模型FreeLong:在不增加额外训练成本的情况下,让现有的短视频生成模型处理更长的视频内容悉尼科技大学和浙江大学的研究人员推出一种用于生成长视频的模型FreeLong,它可以在不增加额外训练成本的情况下,让现有的短视频生成模型处理更长的视频内容,同时保持或提升视频的质量。FreeLong是...新技术# FreeLong# 视频生成模型2年前01,2460
阿里 WAN 项目组正式推出 Wan2.2:MoE 架构 + 高压缩设计,开源视频生成再进化阿里 WAN 项目组正式推出 Wan2.2,这是对 WAN 系列视频生成模型的一次重大升级。本次发布涵盖多个模型变体,全面支持文本到视频(T2V)、图像到视频(I2V)以及混合输入(TI2V)任务,在...视频模型# Wan2.2# 视频生成模型8个月前01,1050
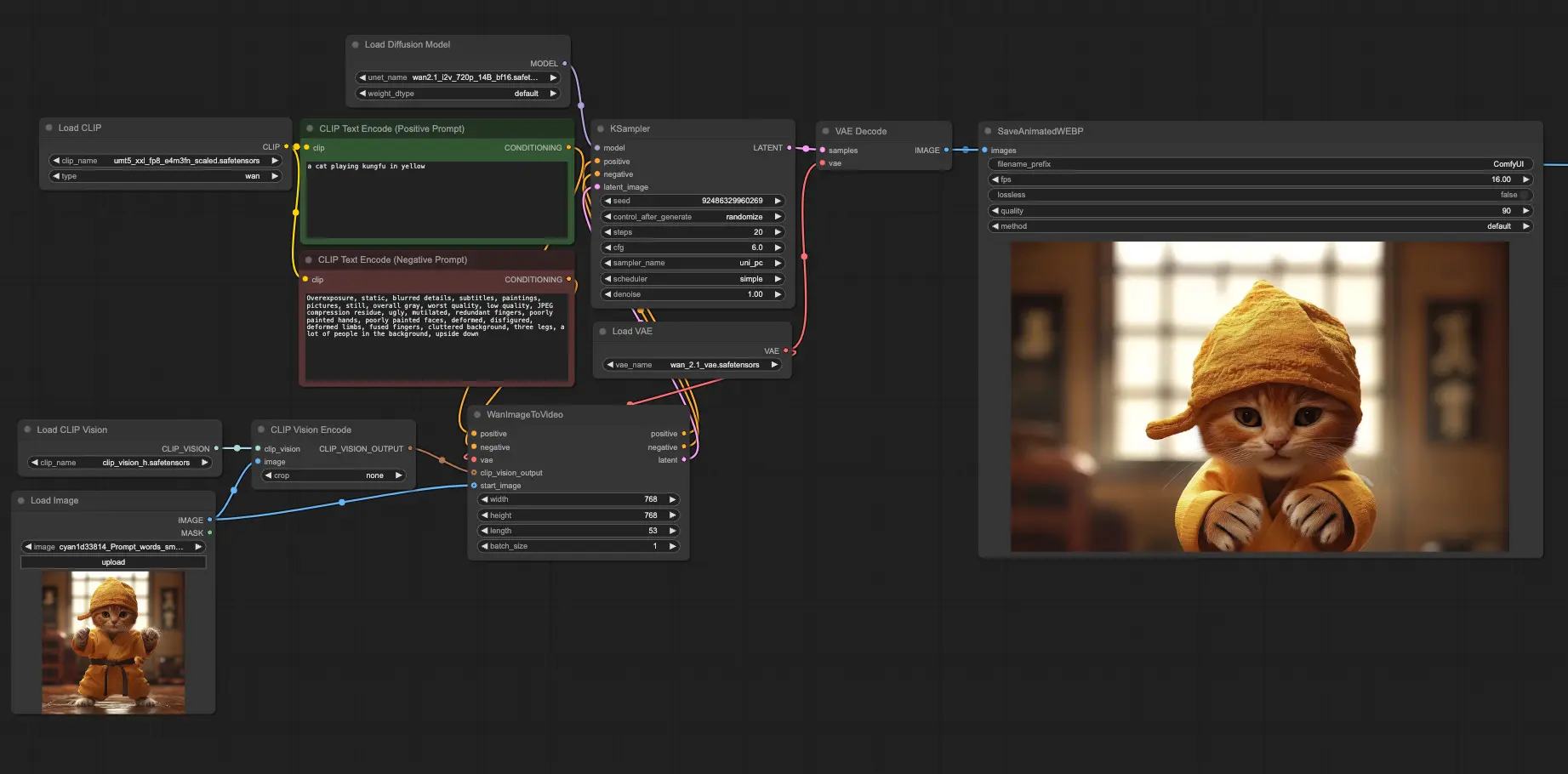
ComfyUI 宣布已原生支持阿里开源视频生成模型Wan2.1阿里巴巴集团通义实验室于 2025 年 2 月 25 日正式开源了其最新一代视频生成模型 Wan2.1。该模型能够根据文本、图像或其他控制信号生成高质量的视频内容,适用于创意设计、影视制作和教育领域等...工作流# ComfyUI# Wan2.1# 视频生成模型1年前08510
高效且多功能的框架Ctrl-Adapter:在各种图像和视频生成模型中加入丰富的控制功能北卡罗来纳大学教堂山分校的研究人员推出高效且多功能的框架CTRL-Adapter,它能够为任何图像或视频扩散模型添加多样的空间控制功能。它支持多种实用的应用,如视频控制、多条件视频控制、稀疏帧条件下的...图像模型# Ctrl-Adapter# 空间控制# 视频生成模型1年前08450
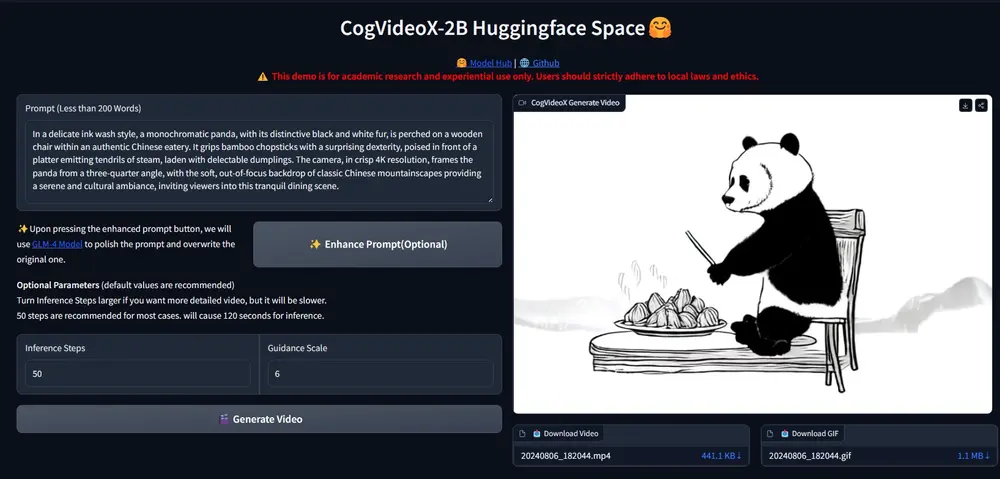
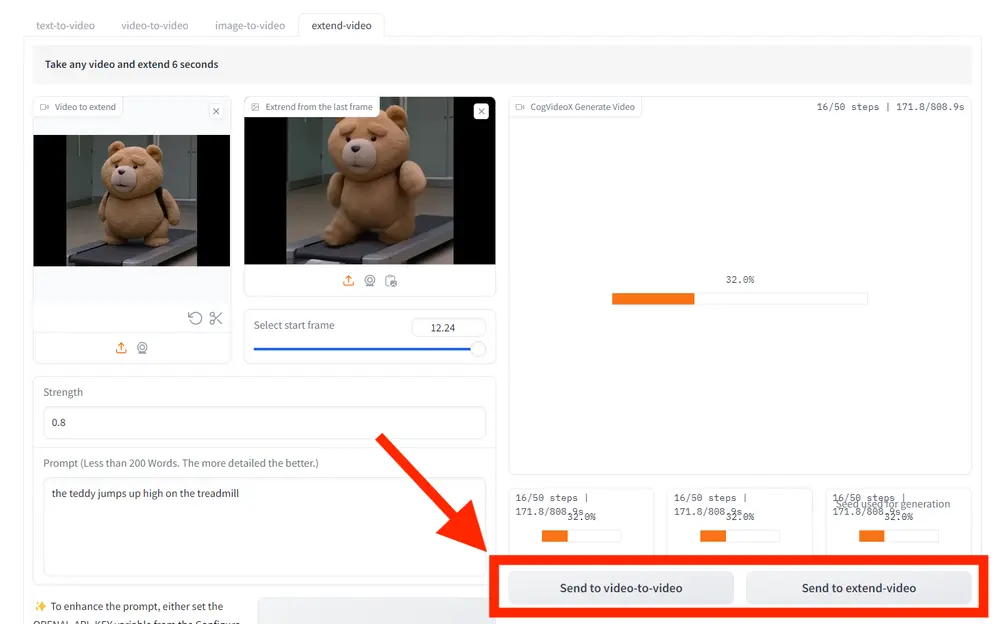
智谱AI推出视频生成模型CogVideoX:与“清影”同源,单张 4090 显卡可推理智谱 AI推出与“清影”同源的视频生成模型 —CogVideoX,CogVideoX模型包含多个不同尺寸大小的模型,目前将开源 CogVideoX-2B,它在 FP-16 精度下的推理需 18GB 显...视频模型# CogVideoX# 智谱AI# 视频生成模型1年前08130
新型视频生成模型T2V-Turbo-v2:基于VideoCrafter2模型提炼,提升视频生成的质量和效率加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术...视频模型# T2V-Turbo-v2# 视频生成模型1年前07870
智谱AI推出CogVideoX 开源模型的升级版本CogVideoX1.5-5B智谱技术团队对于旗下开源视频生成模型CogVideoX进行了升级,今天释出了CogVideoX1.5-5B 系列模型,相比于原有模型,CogVideoX v1.5 将包含 5/10 秒、768P、16...视频模型# CogVideoX1.5-5B# 智谱AI# 智谱清影1年前07340
Cogstudio:专为视频生成模型CogVideo 设计的 WebUICogstudio 是一款专为智谱开源的视频生成模型CogVideoX设计的 Gradio WebUI,建议大家使用之前介绍过的Pinokio进行安装使用,目前仅支持英伟达显卡使用。 GitHub:h...工具# Cogstudio# CogVideo# 视频生成模型2年前06970
PUSA V1.0:以500 美元成本超越 WAN-I2V-14B 的高效视频生成模型由香港城市大学、华为研究院、腾讯、岭南大学等机构联合提出,PUSA V1.0 是一个基于矢量化时间步适应(VTA) 的新型视频扩散模型,实现了极低资源消耗下的高质量视频生成能力。 项目主页:https...视频模型# PUSA V1.0# WAN-I2V-14B# 视频生成模型9个月前06350
基于Transformer架构的新型视频生成模型Snap Video来自Snap、特伦托大学、加州大学默塞德分校、布鲁诺·凯斯勒基金会的研究人员推出新型视频生成模型Snap Video,此模型基于Transformer架构,目标是将文本描述转换成高质量的视频内容。 项...新技术# Snap Video# Transformer# 视频生成模型2年前06210