基于Wan2.1-T2V-1.3B的微调模型,能够生成视觉效果更好的视频对于低显存的朋友,Wan2.1-T2V-1.3B模型是个不错的视频生成模型,开发者Evados为大家精心微调了一系列适合ComfyUI的Wan2.1-T2V-1.3B模型,这些模型经过实验优化,能够带...工作流# Wan2.1-T2V-1.3B# 视频生成模型1年前06070
Genmo推出开源视频生成模型天花板Mochi 1,型需 4 块英伟达H100 显卡才可运行Genmo是一家专注于视频生成的AI初创公司,之前都是默默无闻,其官方视频生成产品也是半死不活,但他们在昨天突然放大招开源了一款视频生成模型Mochi 1,号称其性能可与领先的闭源/专有竞争对手(如R...视频模型# Genmo# Mochi 1# 视频生成模型1年前05560
Meta推出新型视频生成模型Movie Gen:不仅能制作高清视频,还能为视频配上声音Meta宣布推出一款新AI视频生成器Movie Gen,这款工具不仅能制作高清视频,还能为视频配上声音。据Meta介绍,Movie Gen可通过简单的文字输入,自动生成全新的视频内容。此外,它还能编辑...新技术# Meta# Movie Gen# 视频生成模型2年前05530
视频生成模型的高效推理新方案Jenga:无需重新训练模型即可实现HunyuanVideo和Wan2.1显著提速近年来,基于 DiT架构的视频生成模型在生成质量上取得了显著突破,但其高昂的计算成本却严重限制了实际部署与落地。 为了解决这一瓶颈,来自香港中文大学、香港科技大学、快手科技和思谋科技的研究团队提出了 ...视频模型# HunyuanVideo# Jenga# Wan2.110个月前05090
新型视频生成模型Pyramidal Flow:提高视频生成的效率,同时保持生成视频的高质量北京大学、快手科技和北京邮电大学的研究人员推出新型视频生成模型Pyramidal Flow,这个模型的目的是提高视频生成的效率,同时保持生成视频的高质量。可以想象一下,你想制作一个视频,里面有一只小猫...视频模型# Pyramidal Flow# 视频生成模型1年前04880
Lightricks 推出 LTX Video 0.9.6:更快、更稳定,助力创意视频生成Lightricks 在 5 个月前推出了视频生成模型 LTX Video。今天,官方宣布 LTXV 0.9.6 版本正式发布,为视频生成领域带来了新的突破。此次更新推出了 2B 参数开源视频模型的两...视频模型# LTX Video# LTXV 0.9.6# 视频生成模型12个月前04630
高通AI研究院推出一个为移动设备优化的视频生成模型MobileVD高通AI研究院推出了一个为移动设备优化的视频生成模型Mobile Video Diffusion(MobileVD),该模型的目标是在保持生成视频的质量和控制力的同时,显著降低计算需求,使得在移动设备...新技术# MobileVD# 视频生成模型1年前04570
昆仑万维推出SkyReels-V2:首个基于扩散强制框架的无限长度电影生成模型近年来,视频生成领域取得了显著进展,主要得益于扩散模型和自回归框架的推动。然而,这一领域仍面临诸多关键挑战,例如提示一致性、视觉质量、动态效果和视频时长之间的权衡。为了追求更高的视觉质量,许多模型不得...视频模型# SkyReels-V2# 昆仑万维# 视频生成模型11个月前04480
Rhymes AI开源视频生成模型Allegro:从简单的文本提示生成高质量的 6 秒视频Rhymes AI在推出多模态原生模型Aria后,又在昨天开源了视频生成模型Allegro,Allegro 使用户能够从简单的文本提示生成高质量的 6 秒视频,帧率为 15 帧每秒,分辨率为 720P...视频模型# Allegro# Rhymes AI# 视频生成模型1年前04430
Lightricks 推出全新开源视频生成模型 LTXV-13BLightricks之前推出的都是小尺寸模型,而在今天它宣布推出其最新且最先进的开源视频生成模型——LTXV-13B,这一模型不仅在质量、速度和可访问性方面实现了显著提升,还为创作者提供了强大的工具...视频模型# Lightricks# LTXV-13B# 视频生成模型11个月前04360
新型视频生成模型Factorized-Dreamer:用于将文本转换成高质量的视频字节跳动和香港理工大学的研究人员推出新型视频生成模型Factorized-Dreamer,它专门用于将文本转换成高质量的视频(Text-to-Video, T2V)。Factorized-Dreame...新技术# Factorized-Dreamer# 视频生成模型2年前04290
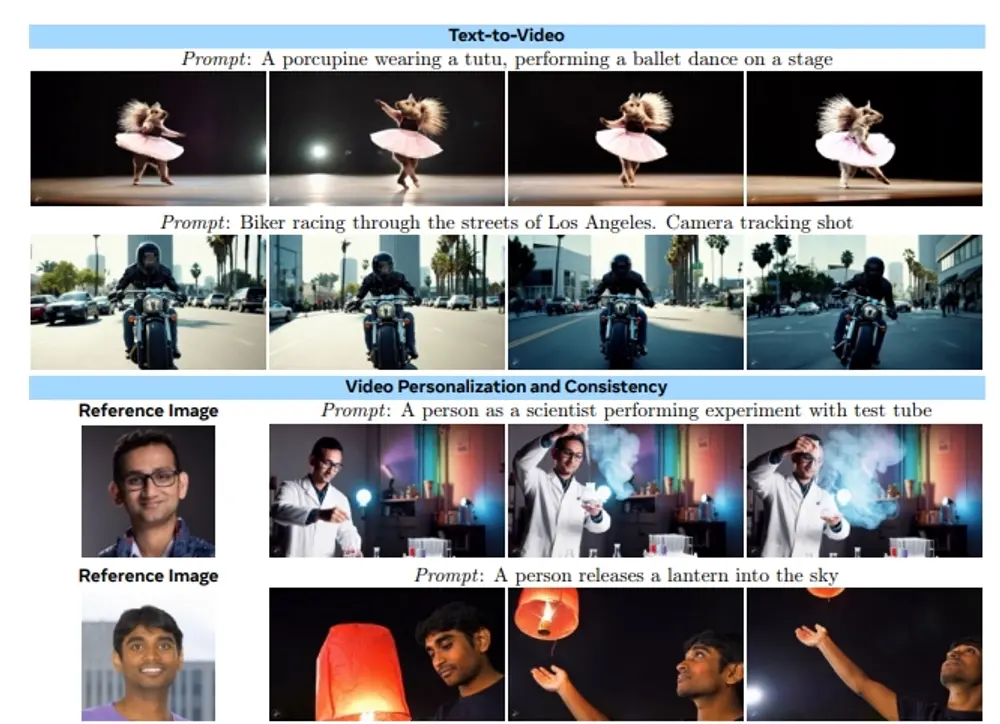
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型10个月前04230