英伟达联合团队提出新型连续时间流图(flow map)模型 AYF:统一扩散与流模型的少步生成方案由英伟达、多伦多大学及矢量研究所联合提出一种新型的连续时间流图(flow map)模型Align Your Flow(AYF) ,显著提升扩散模型和基于流的生成模型的采样效率。这些模型虽然在图像与文本...新技术# Align Your Flow# AYF# 英伟达10个月前03810
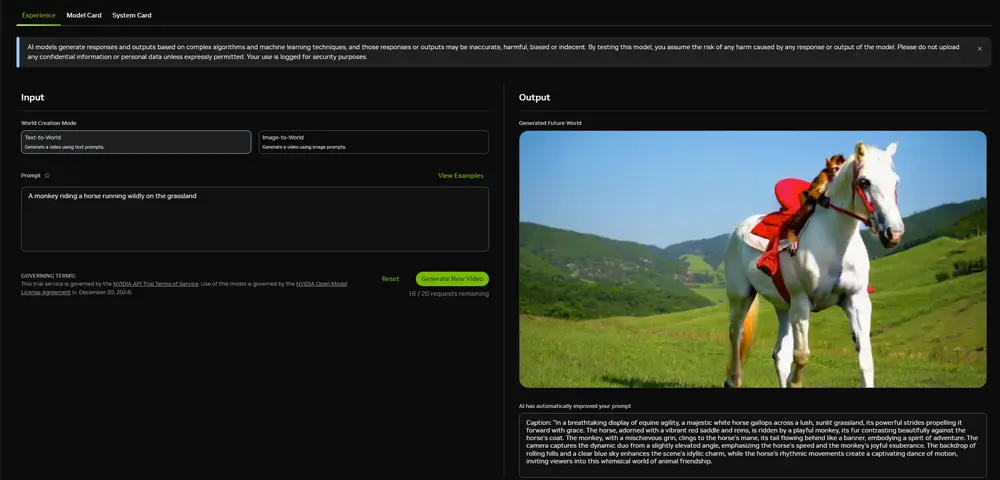
英伟达推出世界基础模型平台NVIDIA Cosmos :帮助物理 AI 开发人员更好、更快地构建物理 AI 系统英伟达在CES2025上宣布推出 NVIDIA Cosmos 平台,该平台包含先进的世界基础生成模型、高级分词器、防护栏和加速视频处理管道,旨在推动自动驾驶汽车(AV)和机器人等物理 AI 系统的发展...多模态模型# NVIDIA Cosmos# 世界模型# 英伟达1年前03620
英伟达提出 DC-Gen:用于加速扩散模型的后训练框架,生成速度快 53 倍在文生图领域,高分辨率输出(如 4K)正成为标配。然而,随之而来的计算成本和推理延迟问题日益凸显——以当前领先的 FLUX.1-Krea-12B 模型为例,在英伟达H100 GPU 上生成一张 4K ...图像模型# DC-Gen# 文生图模型# 英伟达6个月前03600
英伟达 TensorRT 为 RTX显卡带来 2 倍性能提升,全面支持所有 RTX显卡英伟达宣布将 TensorRT AI 加速技术 引入 RTX 平台,为所有 GeForce RTX显卡提供最高可达 2 倍于 DirectML 的性能提升。这一突破性进展不仅显著优化了 AI 推理速度...早报# TensorRT# 英伟达11个月前03560
英伟达推出面向文档理解的小而强视觉-语言模型 Llama Nemotron Nano VL英伟达正式发布了 Llama Nemotron Nano VL —— 一款专为高效处理复杂文档设计的轻量级视觉-语言模型(VLM)。该模型基于 Llama 3.1 架构构建,在保持高性能的同时兼顾推理...多模态模型# Llama Nemotron Nano VL# 英伟达10个月前03550
英伟达推出Add-it:基于文本指令在图像中添加对象的创新方法英伟达、特拉维夫大学和巴伊兰大学的研究人员推出一个名为Add-it的系统,它是一种无需训练的方法,可以在图像中根据文本提示添加对象。这种方法扩展了预训练扩散模型的注意力机制,以整合来自三个关键来源的信...新技术# Add-it# 英伟达1年前03520
英伟达 RTX显卡实现 OpenAI 最新开源模型 gpt-oss最快推理速度英伟达(NVIDIA)宣布与 OpenAI 深度合作,将后者最新发布的开放权重模型 gpt-oss-20b 和 gpt-oss-120b 带入消费级与专业级设备端,依托 GeForce RTX 与 R...早报# gpt-oss# OpenAI# 英伟达8个月前03490
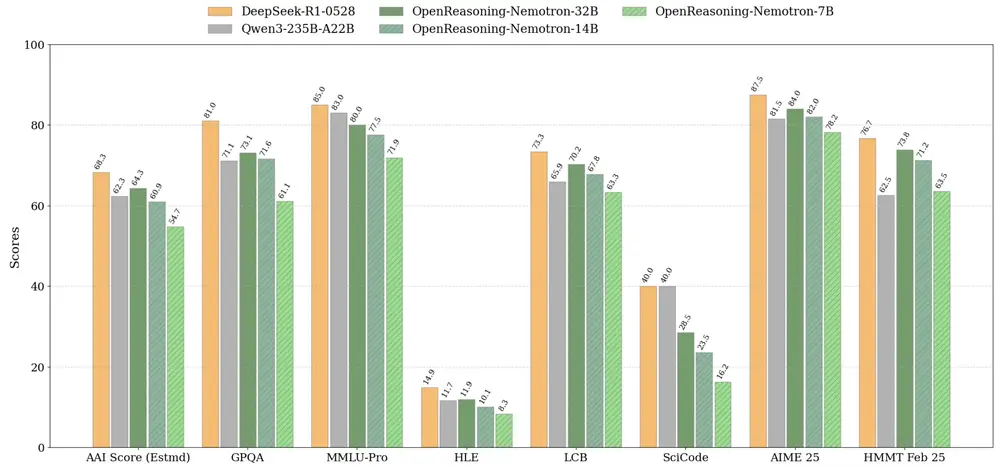
英伟达发布OpenReasoning-Nemotron:多规模推理模型,覆盖数学、科学与编程英伟达近日发布了 OpenReasoning-Nemotron 模型家族,这是一组专为数学、科学和编程推理任务优化的大语言模型。 模型:https://huggingface.co/collectio...大语言模型# OpenReasoning-Nemotron# 英伟达9个月前03400
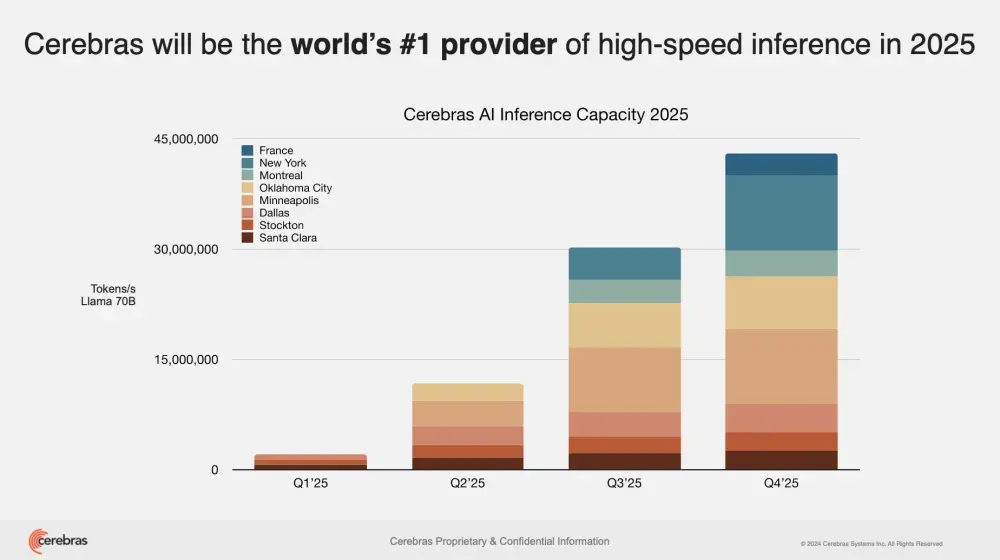
这对英伟达来说可能是坏消息!AI芯片初创公司Cerebras 新建 6 个 AI 数据中心,每秒处理 4000 万tokensCerebras Systems,一家致力于挑战英伟达在AI市场主导地位的初创公司,于周二宣布了一项重大扩展计划:在全球新增六个AI数据中心。此举不仅将大幅提升其推理能力,还将与关键行业伙伴建立合作关...早报# AI芯片# Cerebras# 英伟达1年前03160
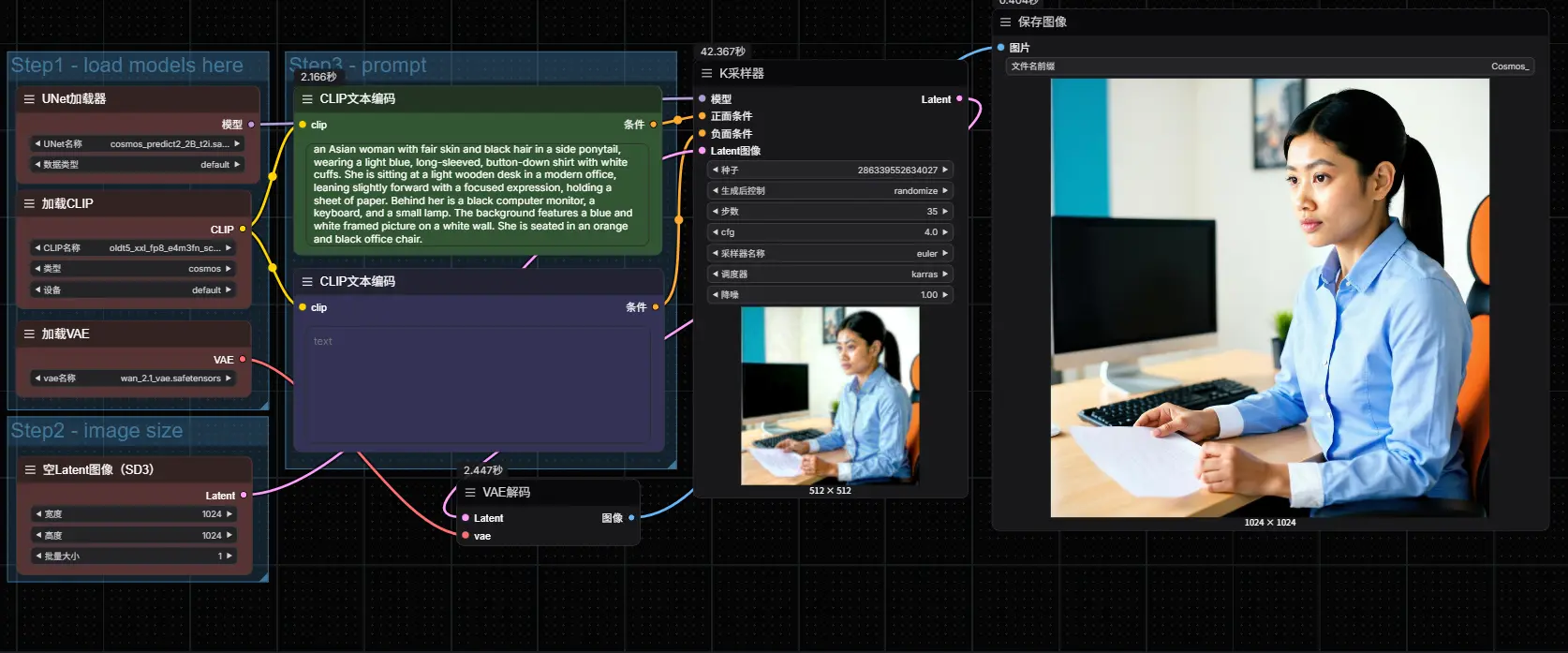
在 ComfyUI 中使用英伟达物理世界基础模型Cosmos-Predict2 实现文生图与视频生成指南Cosmos-Predict2 是由英伟达推出的新一代物理世界基础模型,专为物理 AI 场景下的高质量视觉生成与预测任务设计。该模型具备高度的物理准确性、环境交互能力以及细节还原度,能够真实模拟复杂的...工作流# Cosmos-Predict2# 物理世界基础模型# 英伟达9个月前03120
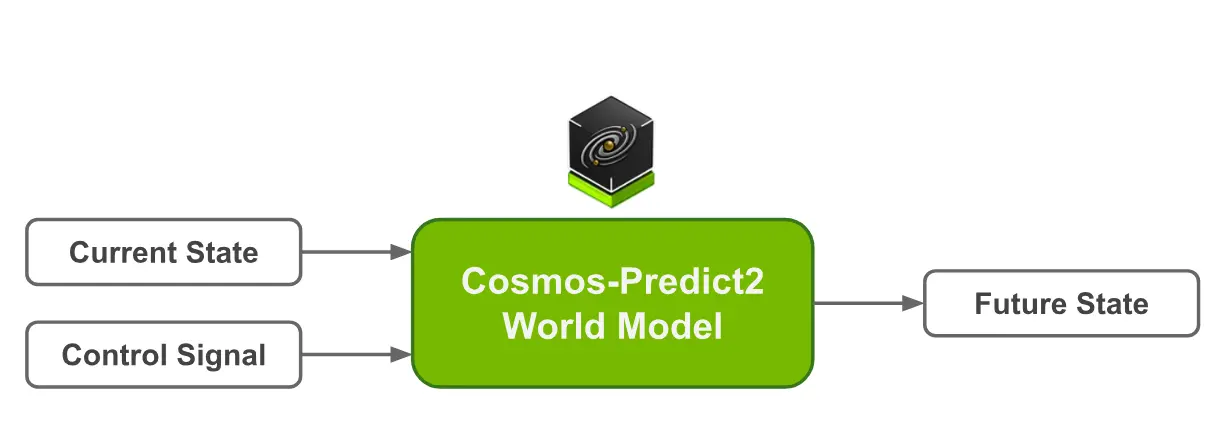
英伟达发布 Cosmos-Predict2:打造物理AI的世界基础模型在物理AI(Physical AI)系统的开发中,模拟真实世界的动态变化至关重要。为此,英伟达推出了 Cosmos-Predict2,作为其 Cosmos 世界模型 的最新演进版本,专为生成具有物理感...多模态模型# Cosmos-Predict2# 世界基础模型# 英伟达10个月前03020
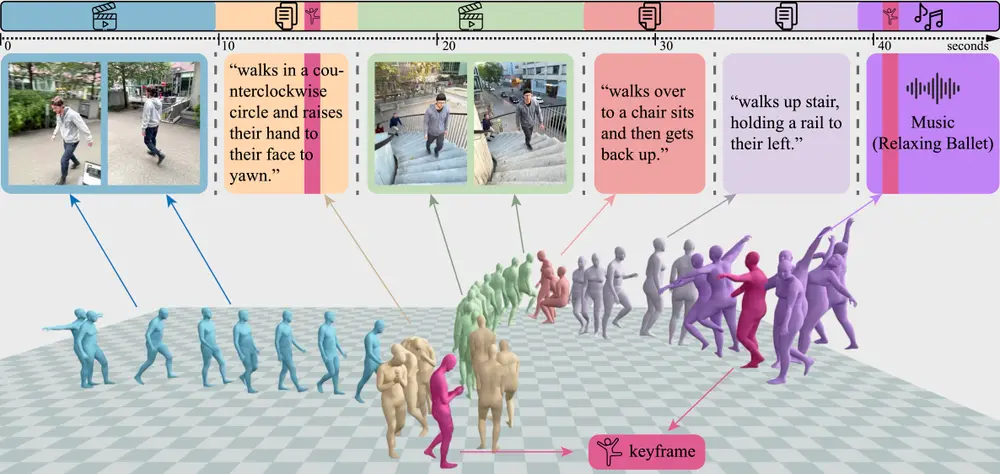
英伟达发布人体运动的通用模型Genmo:实现从视频、2D 关键点、文本描述、音乐和3D 关键帧等多种条件信号中生成和估计高质量的人类运动英伟达研究团队开发的统一框架 GENMO,用于人类运动建模。GENMO 的目标是将人类运动估计(estimation)和生成(generation)任务整合到一个框架中,从而实现从视频、2D 关键点...新技术# Genmo# 人体运动# 英伟达11个月前02970