英伟达发布 Nemotron-Cascade 2:开源 30B MoE 模型,激活仅 3B 却斩获 IMO/IOI 金牌水平在“越大越强”的大模型军备竞赛中,英伟达走出了一条截然不同的路:追求极致的“智能密度”。 英伟达正式开源 Nemotron-Cascade 2,一款总参数量 30B、激活参数仅 3B 的混合专家模型...大语言模型# Nemotron-Cascade 2# 英伟达1周前0820
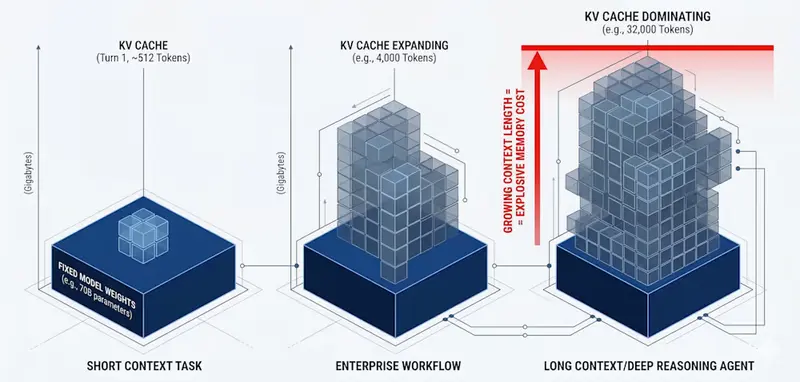
英伟达发布 KVTC 新技术:无需改模型即可将 LLM 内存占用缩小 20 倍,首字延迟降低 8 倍在大语言模型(LLM)的推理过程中,有一个长期存在的痛点:随着对话变长,显存占用呈线性甚至指数级增长。这就是著名的 KV 缓存(Key-Value Cache) 瓶颈。 现在,英伟达(NVIDIA)的...新技术# KVTC# 英伟达1周前0210
DLSS 5 遭遇口碑滑铁卢:玩家痛斥“生成式 AI”毁掉游戏艺术风格英伟达预告了下一代帧生成技术 DLSS 5,原本期待中的技术飞跃却意外引发了游戏界的强烈反弹。与以往专注于提升分辨率和帧率的超采样技术不同,DLSS 5 引入了生成式 AI来实时重构光照和纹理。 然而...早报# DLSS 5# 英伟达2周前0180
英特尔与英伟达联手:至强6 搭载DGX Rubin,提速大规模AI推理在2026英伟达GTC大会上,英特尔正式宣布:全新至强6处理器将作为英伟达DGX Rubin NVL8系统的主机CPU,双方通过CPU与AI平台深度协同,进一步提升大规模AI推理与集群整体效率。 这并...硬件# 至强6# 英伟达# 英特尔2周前0100
美国撤销争议AI硬件出口规则:取消“对等投资”要求,新规仍在制定美国商务部已正式撤销一项争议性AI硬件出口规则草案,该草案曾要求海外大型AI集群运营商必须投资美国AI基础设施才能采购英伟达、AMD等厂商的高端AI加速器。目前,针对AI硬件的新出口框架仍在制定中。 ...早报# AI硬件# AMD# 美国2周前0200
英伟达发布 Nemotron 3 Super:1200 亿参数 MoE 架构,智能体吞吐量飙升 5 倍随着企业 AI 应用从简单的聊天机器人向复杂的多智能体系统(Multi-Agent Systems)演进,两大瓶颈日益凸显:上下文爆炸导致成本激增与目标漂移,以及每一步都需大模型推理带来的高昂"思考税...大语言模型# NVIDIA Nemotron 3 Super# 英伟达3周前0400
英伟达 GDC 重磅更新:ComfyUI 新增“应用模式”与 RTX 超分,本地 AI 视频生成效率提升 2.5 倍在本周于旧金山举行的游戏开发者大会(GDC)上,英伟达宣布了一系列针对游戏开发者和数字艺术家的重大更新。通过与热门生成式 AI 工具 ComfyUI 的深度合作,结合 NVIDIA RTX 硬件加速技...新闻# ComfyUI# 英伟达3周前01190
英伟达入局智能体赛道:开源项目“NemoClaw”曝光,主打企业安全与硬件中立当生成式AI的推理能力日益强大,如何让其安全、可靠地“动手”执行任务,成为企业落地的最后一道门槛。OpenClaw的兴起证明了“模型+工具”架构的巨大潜力,但也暴露了权限失控与安全审计的隐患。 在此背...早报# NemoClaw# OpenClaw# 英伟达3周前0420
英伟达领衔英国试验:AI 数据中心实现“分钟级”电力调峰,破解电网接入瓶颈在全球 AI 算力需求爆发式增长的背景下,电力供应已成为制约数据中心扩张的最大瓶颈。然而,一项由英伟达 (NVIDIA)、英国国家电网 (National Grid)、Emerald AI 及电力研究...早报# 电力# 英伟达4周前0280
英伟达再创纪录:季度营收 680 亿美元,黄仁勋称“全球 GPU 库存耗尽,Token 需求指数级爆发”全球市值最高的公司 英伟达 (NVIDIA) 再次交出了一份令人咋舌的成绩单。周三公布的最新财报显示,受益于全球对 AI 算力的狂热需求,英伟达单季度营收高达 680 亿美元,同比增长 73%,刷新历...早报# 英伟达1个月前0160
Meta 与英伟达达成新协议,采购数百万块 AI 芯片Meta 已与英伟达达成一项多年合作协议,计划采购数百万块英伟达 AI 芯片,用于扩展自身数据中心。 此同时,英伟达也首次开启 AI CPU 对外销售,此次协议中涉及的 Grace 和 Vera 两款...早报# Meta# 英伟达1个月前0210
天气 AI 革命!英伟达发布 Earth-2 开放模型:0-6 小时预警 + 15 天预报,主权国家可自托管美国冬季风暴来袭前,多地降雪量预测差出“天壤之别”——有的说下5厘米,有的说下20厘米,气象部门和民众都陷入纠结。 在 2026 年 1 月于休斯敦举行的美国气象学会(AMS)年会上,英伟达正式发布了...世界模型# Earth-2# 英伟达2个月前0490