腾讯混元发布 HunyuanImage-3.0:800亿参数开源原生多模态模型,实现“语义理解-图像生成”的深度融合腾讯混元项目组正式发布并开源HunyuanImage-3.0——当前开源社区规模最大、性能最强的文生图模型。该模型总参数量突破800亿,推理时每token仅激活130亿参数(兼顾性能与效率),基于原生...图像模型# HunyuanImage-3.0# 腾讯混元6个月前07780
腾讯混元推出 Hunyuan3D-Omni:统一框架实现多模态可控 3D 生成腾讯混元项目组近日发布 Hunyuan3D-Omni ——一个面向 3D 资产生成的统一框架,解决传统单图生成 3D 模型时存在的几何失真、姿态不可控等问题。 地址:https://3d.hunyua...3D模型# Hunyuan3D-Omni# 腾讯混元6个月前02220
腾讯混元联合高校提出 Direct-Align:用“一步恢复”实现扩散模型的高效偏好对齐在文生图模型日益成熟的今天,提升生成质量已不再是唯一目标——如何让图像真正符合人类的审美偏好,成为更高阶的挑战。 现有方法通常依赖强化学习或可微奖励机制,将模型输出与人类偏好对齐。但这些方法普遍存在两...图像模型# Direct-Align# flux.1-dev-SRPO# 腾讯混元7个月前01970
腾讯混元发布四款小尺寸开源模型,端侧 AI 应用迎来新选择继此前开源大尺寸模型后,腾讯混元团队近日推出四款全新小尺寸开源模型,参数量分别为 0.5B、1.8B、4B 和 7B。这些模型专为低功耗、资源受限场景设计,可在消费级显卡、笔记本电脑、手机、智能座舱及...大语言模型# 腾讯混元8个月前03770
腾讯混元提出 X-Omni:用强化学习突破离散自回归图像生成瓶颈在当前多模态生成模型的发展中,研究者始终在探索一个统一的建模范式:能否用类似语言模型“预测下一个词”的方式,来生成图像?这种被称为“下一令牌预测(next-token prediction)”的自回归...图像模型# X-Omni# 腾讯混元8个月前04840
腾讯混元推出新型框架 Hunyuan-GameCraft:为游戏环境生成高动态、交互式的视频内容腾讯混元项目组和华中科技大学的研究人员推出新型框架 Hunyuan-GameCraft,为游戏环境生成高动态、交互式的视频内容。Hunyuan-GameCraft 能够从单张图像和对应的提示出发,生成...新技术# Hunyuan-GameCraft# 腾讯混元9个月前04080
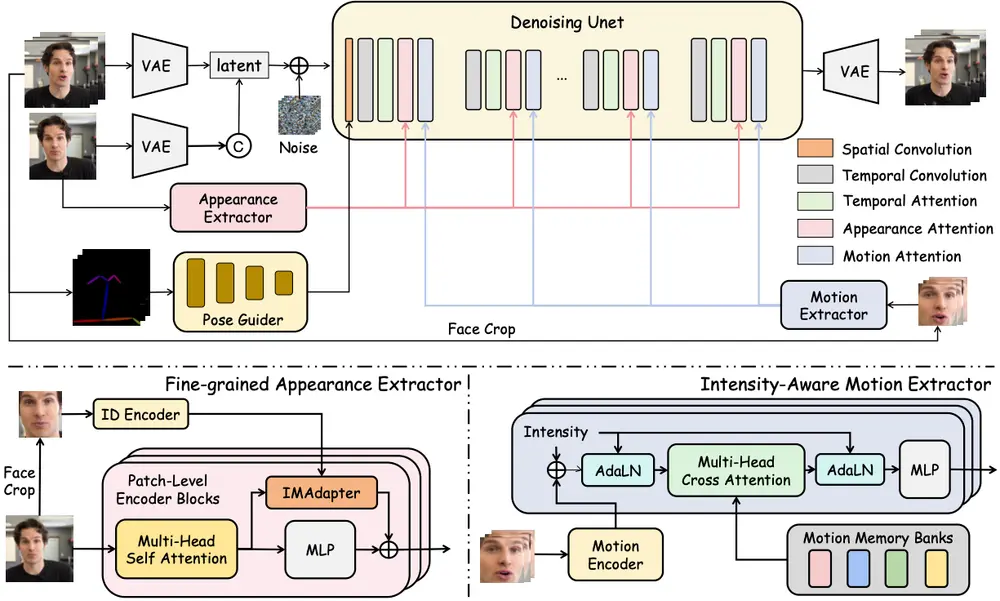
腾讯混元项目组推出数字人头像生成模型 HunyuanPortrait :用于高度可控且逼真的肖像动画生成腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模...视频模型# HunyuanPortrait# 腾讯混元10个月前01950
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型10个月前04230
微软AI研究团队WizardLM被爆已加入腾讯混元项目组,腾讯加速布局AI领域近日,位于北京的微软AI研究小组 WizardLM 被曝已加入腾讯。这一消息由 WizardLM 团队的核心成员在社交媒体上证实。腾讯正通过吸纳顶尖AI人才进一步强化其AI研发能力。 周二,Wizar...早报# WizardLM# 微软# 腾讯混元11个月前02110
基于Flux模型的创新角色生成框架InstantCharacter:单张图像生成高质量角色图像腾讯混元团队与InstantX团队近日联合推出了一种全新的角色定制方法——InstantCharacter。这一方法无需调优,仅通过单张图像即可实现高保真、文本可控且角色一致的图像生成,支持多种下游任...图像模型# FLUX模型# InstantCharacter# InstantX12个月前06050
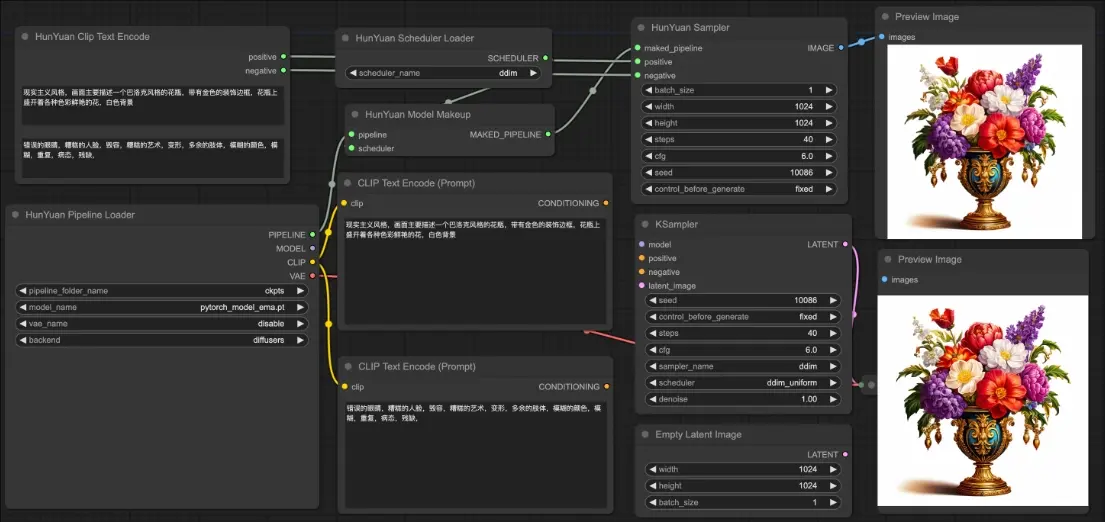
降低生成步数!腾讯发布混元文生图开源大模型的蒸馏模型和ComfyUI节点及工作流腾讯发布针对腾讯混元文生图开源大模型(混元 DiT)的加速库,号称大幅提升推理效率,生图时间缩短 75%。混元 DiT 模型的使用门槛也大幅降低,用户可以基于 ComfyUI 的图形化界面使用腾讯混元...插件# Hunyuan-DiT# 混元 DiT# 腾讯混元2年前01,3670
腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT:能够根据上下文与用户进行多轮多模态对话,生成并优化图像腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT,它特别擅长理解中文和英文的文本提示,并据此生成图像,Hunyuan-DiT能够根据上下文与用户进行多轮多模态对话,生成并优化图像...新技术# Hunyuan-DiT# 提示词# 文生图模型2年前07420