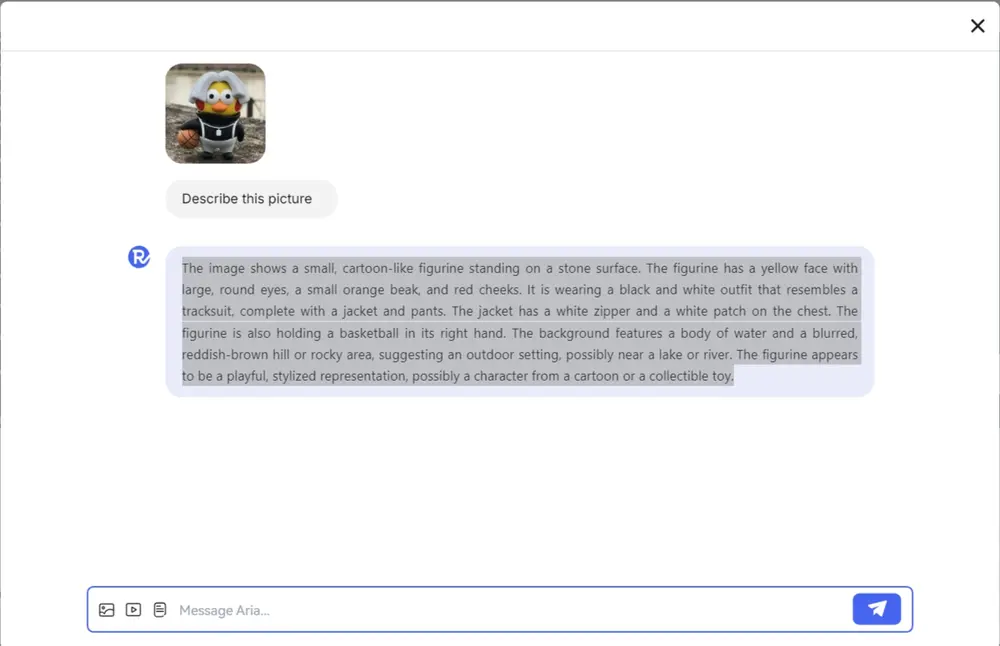
新型多模态原生模型Aria:专门设计来处理和理解多种类型的信息(文本、代码、图像和视频)Rhymes AI推出新型多模态原生模型Aria,这是一个开源的混合专家(MoE)模型,ARIA专门设计来处理和理解多种类型的信息,比如文本、代码、图像和视频,而且它能够像人类一样,不需要特别区分这些...多模态模型# Aria# Rhymes AI# 多模态模型1年前05730
深度求索推出新颖自回归框架 Janus: 具有图像生成功能的 13 亿多模态模型多模态AI模型是能够理解和生成视觉内容的强大工具。然而,现有方法通常使用单一视觉编码器来处理这两项任务,这导致了由于理解和生成在本质上不同的需求而表现不佳。理解需要高层次的语义抽象,而生成则关注局部细...多模态模型# Janus# 多模态模型1年前09330
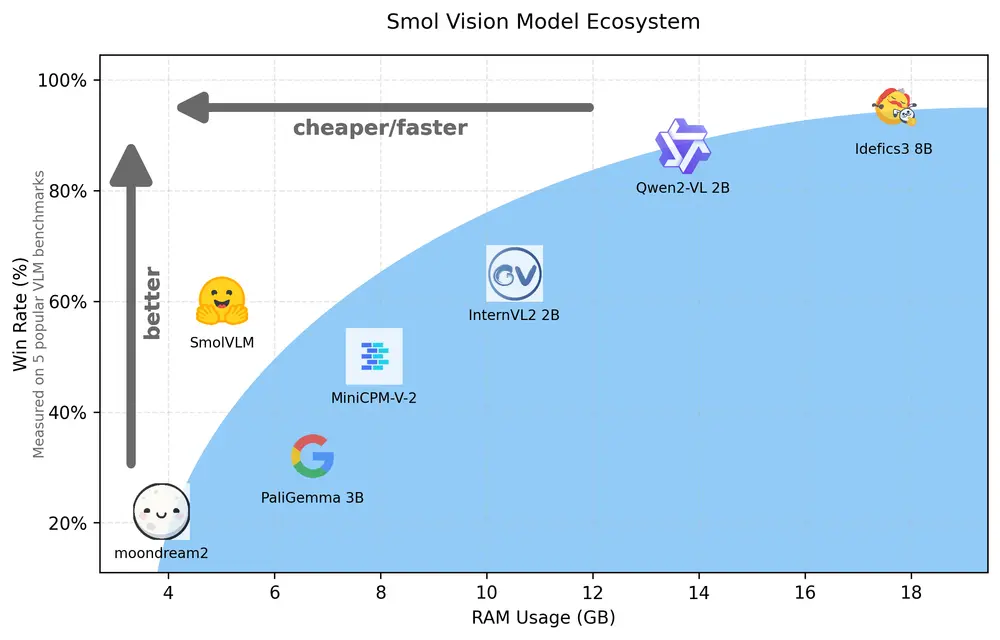
Hugging Face发布一个用于设备上推理的2B参数小型多模态模型SmolVLM近年来,随着机器学习技术的飞速发展,视觉-语言模型(VLM)的需求不断增加。这些模型能够处理图像和文本的组合任务,如图像描述、问答和故事生成等。然而,大多数现有的VLM需要大量的计算资源和内存,这限制...多模态模型# Hugging Face# SmolVLM# 多模态模型1年前02990
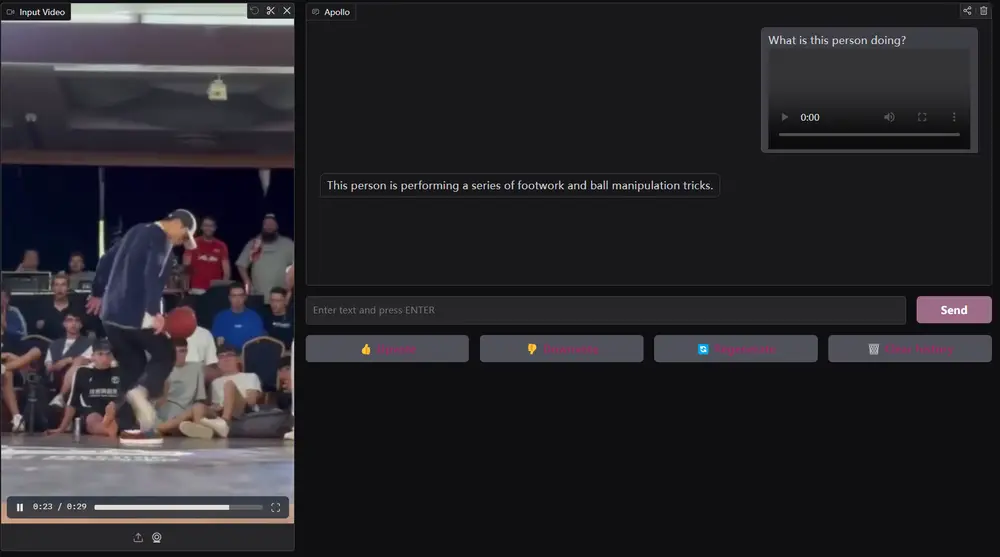
Meta推出多模态模型Apollo:擅长处理长视频,能够在长达一小时的视频中保持高效的理解能力尽管视频感知能力已经迅速集成到大型多模态模型(LMMs)中,但其驱动视频理解的基本机制仍未被充分理解。这导致了许多设计决策缺乏适当的理由或分析,尤其是在训练和评估这些模型时,高昂的计算成本和有限的开放...多模态模型# Apollo# Meta# 多模态模型1年前03100
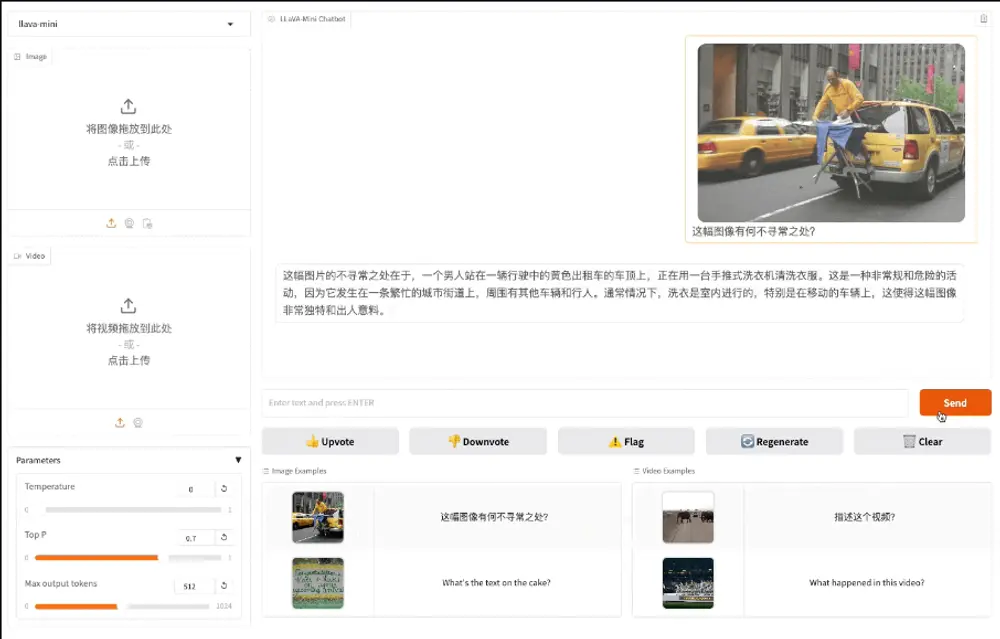
高效大型多模态模型LLaVA-Mini:通过最小化视觉令牌(vision tokens)的数量来提高模型的计算效率和响应速度中国科学院计算技术研究所智能信息处理重点实验室(ICT/CAS)、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出高效大型多模态模型LLaVA-Mini,旨在通过最小化视觉令牌(visi...多模态模型# LLaVA-Mini# 多模态模型1年前02980
StreamChat:增强大型多模态模型(LMMs)与流媒体视频内容的交互能力香港中文大学、英伟达、上海人工智能实验室、InnoHK和香港理工大学的研究人员推出新型方法StreamChat,它旨在增强大型多模态模型(LMMs)与流媒体视频内容的交互能力。在流媒体交互场景中,现有...新技术# StreamChat# 多模态模型1年前03100
Inst-IT:增强大型多模态模型实例级理解能力复旦大学计算机学院、上海创新学院和华为诺亚方舟实验室的研究人员提出了Inst-IT,这是一种通过明确的视觉提示指令调优来增强大型多模态模型(LMMs)实例级理解能力的解决方案。尽管现有的LMMs在整体...新技术# Inst-IT# 多模态模型1年前03070
多模态模型Transfusion:能够同时处理离散数据(如文本)和连续数据(如图像)Meta、Waymo和南加州大学的研究人员推出多模态模型Transfusion,它能够同时处理离散数据(如文本)和连续数据(如图像)。Transfusion的核心思想是将语言模型的下一个词预测(nex...新技术# Transfusion# 多模态模型2年前07640
阿里推出新型大型多模态模型ConvLLaVA:专门设计用于处理高分辨率的视觉数据清华大学和阿里巴巴的研究人员推出新型大型多模态模型ConvLLaVA,它专门设计用于处理高分辨率的视觉数据。多模态模型能够理解和处理多种类型的数据,比如文本、图像和视频,这使得它们在各种应用场景中都非...新技术# ConvLLaVA# 多模态模型# 阿里巴巴2年前07210