突破 SD3.5/FLUX.1!TiM模型实现少步高效与多步高质无缝衔接来自香港中文大学MMLab、上海人工智能实验室和悉尼大学的研究团队,推出了一款名为Transition Models (TiM) 的新型生成模型。该模型通过重构生成学习的核心目标,成功破解了生成模型领...图像模型# Transition Models# 生成模型7个月前02690
Drawing2CAD:一键把二维工程图转成三维参数化 CAD 模型在工业设计、机械工程、产品开发领域,有一个长期存在的“效率瓶颈”: 设计师画好了二维工程图 → 工程师手动在 CAD 软件里重建三维模型 → 耗时、易错、难迭代。 现在,这个问题有了一个自动化解法 ...图像模型# CAD 模型# Drawing2CAD7个月前05720
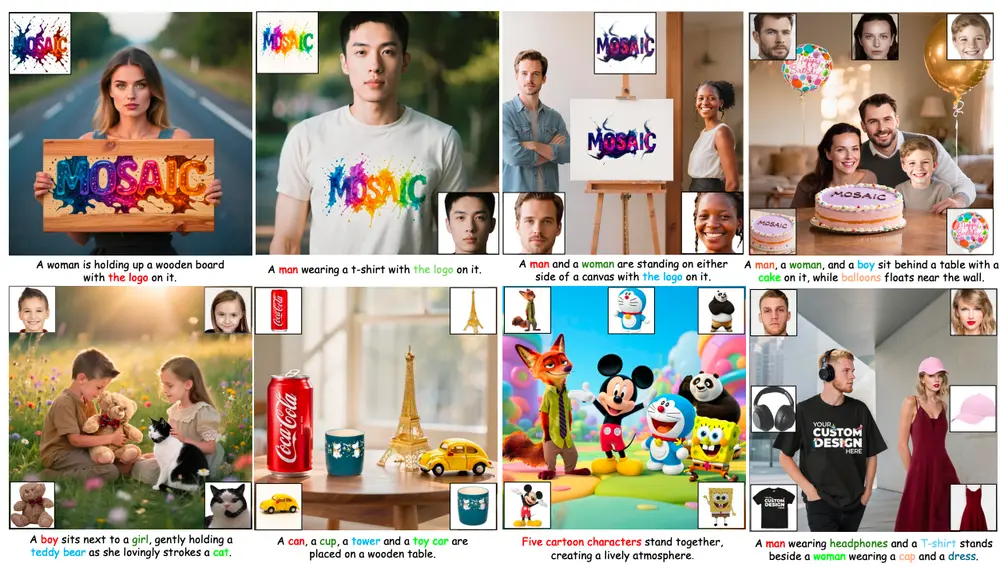
MOSAIC:通过语义对齐与特征解耦实现高保真的多主体个性化生成在个性化图像生成任务中,我们常常希望将多个参考主体(如人物、动物、物体)的特征融合到一张新图像中——例如,“让A的脸型、B的发型、C的表情和D的服饰出现在同一人身上”。这类任务被称为多主体个性化生成...图像模型# MOSAIC# 个性化生成7个月前01700
基于图像编辑模型的 FE2E:革新单目密集几何预测在单目深度估计、表面法线预测等密集几何预测任务中,如何在有限标注数据下实现高精度的零样本泛化,一直是三维视觉的核心挑战。 近年来,研究者尝试利用文本到图像生成模型(如Stable Diffusion...图像模型# FE2E# 图像编辑7个月前03120
Face-MoGLE:一种面向高保真与可控人脸生成的新框架在生成模型中,可控人脸合成是一项极具挑战的任务。既要保证生成图像的真实感与细节质量,又要实现对发型、五官、表情等语义属性的精确控制,二者往往难以兼顾。 现有方法常将语义条件直接拼接或交叉注意力注入生成...图像模型# Face-MoGLE# 人脸生成7个月前03180
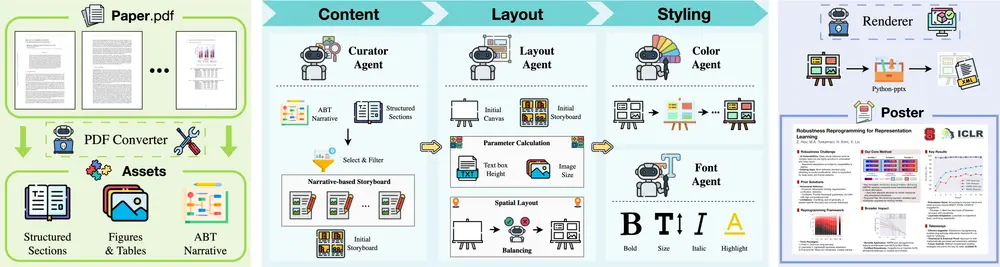
PosterGen:用多智能体系统自动生成高质量学术海报对研究人员而言,撰写论文只是第一步。在会议展示阶段,如何将复杂的研究内容浓缩成一张信息清晰、视觉美观、叙事连贯的学术海报,是一项耗时且需要设计经验的任务。 尽管已有自动化工具尝试解决这一问题,但大多数...图像模型# PosterGen# 学术海报7个月前04440
CoMPaSS:让AI“看懂”空间关系,提升文生图模型的空间理解能力尽管当前的文本到图像(Text-to-Image, T2I)扩散模型能够生成高度逼真的图像,但在一个关键任务上仍频频失手:准确理解并渲染文本中描述的空间关系。 例如,当用户输入: “一个棕色皮革沙发放...图像模型# CoMPaSS7个月前01820
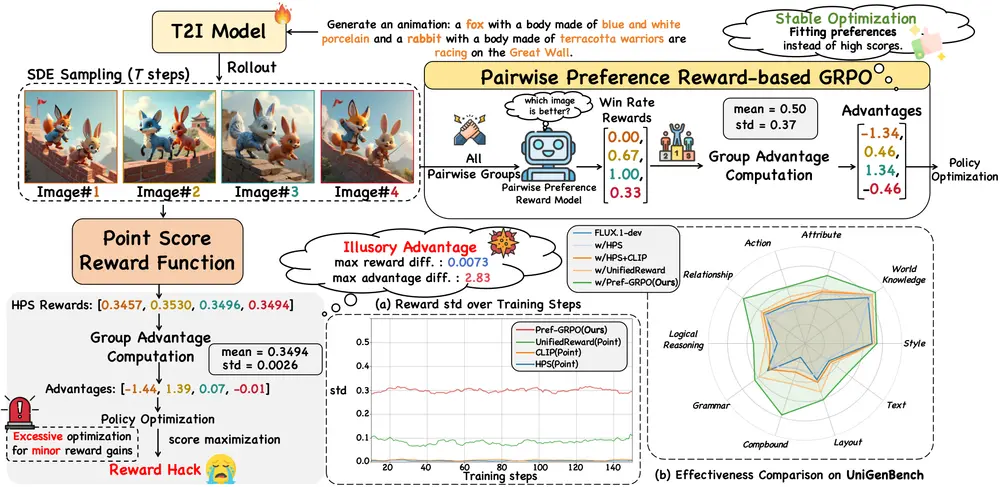
复旦等团队联合突破文生图模型生成瓶颈:Pref-GRPO解决奖励操控,UniGenBench补上评估短板文本到图像(T2I)生成技术的进步,离不开强化学习方法的优化与基准测试的支撑。但当前领域存在两大核心问题:一是传统强化学习依赖“点式奖励模型”打分,易出现“分数涨而质量降”的奖励操控现象;二是现有基准...图像模型# Pref-GRPO# 文生图模型7个月前03450
字节跳动推出 USO:统一风格与主体生成模型,开源全方案赋能创作字节跳动智能创作实验室UXO项目组近期发布了UXO家族的新成员——USO(统一风格-主体优化定制模型)。这款模型打破了现有技术中“风格驱动”与“主体驱动”生成相互孤立的困境,能在单一框架下自由组合任意...图像模型# USO# 字节跳动# 统一风格与主体生成模型7个月前06060
nano-banana正式版!谷歌发布全新图像模型Gemini 2.5 Flash Image,更精准的 AI 图像编辑谷歌正在为其 Gemini 聊天机器人引入一项重要升级:全新的 AI 图像模型 Gemini 2.5 Flash Image。该模型不仅提升了图像生成质量,更在编辑精度、角色一致性与多图融合方面实现了...图像模型# AI 图像编辑# Gemini 2.5 Flash Image# nano-banana8个月前05620
Chroma 模型家族正式发布:基于 FLUX.1-schnell,8.9亿参数开源无限制,4大分支适配不同需求开发者 lodestones 近期宣布,基于 FLUX.1-schnell 构建的 8.9 亿参数生成模型 Chroma 已完成全部基础训练,正式开放供开发者与研究者使用。作为完全遵循 Apache ...图像模型# Chroma# FLUX.1 [schnell]8个月前01,2120
GNER-T5-XXL:GNER 提升零样本实体识别能力,可用于 Flux、Chroma 等模型在多模态生成系统中,精准识别文本中的关键语义元素,是生成高质量图像或内容的前提。例如,当输入提示词“一位身着红色礼服的女人,手持手枪,站在黑暗小巷中”,模型需要准确识别出“红色礼服”“手枪”“黑暗小巷...图像模型# Chroma# FLUX# GNER-T5-XXL8个月前04490