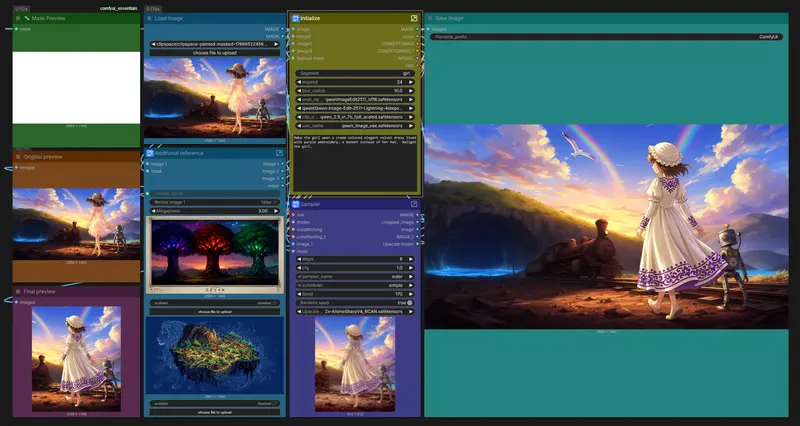
在多模态生成系统中,精准识别文本中的关键语义元素,是生成高质量图像或内容的前提。例如,当输入提示词“一位身着红色礼服的女人,手持手枪,站在黑暗小巷中”,模型需要准确识别出“红色礼服”“手枪”“黑暗小巷”等实体,才能在图像中正确呈现。
然而,传统命名实体识别(NER)方法在面对未见过的实体类型或新领域时,往往表现不佳,需要大量标注数据进行微调。
为此,研究人员提出了一种名为 GNER(Generative Named Entity Recognition) 的新型框架。它展现出在未见实体类别上的强零样本识别能力——即无需针对特定领域重新训练,即可准确识别新类型的实体。
核心机制:用生成式模型做实体识别
与传统基于分类或序列标注的NER方法不同,GNER采用生成式建模路径:将命名实体识别任务转化为“根据输入文本,生成所有对应实体”的序列生成问题。
例如:
- 输入:“职业级的原始照片,展现一位身着诱人红色礼服的致命女人……”
- 输出:“红色礼服,致命女人,手枪,黑暗小巷,午夜时分”
这种方式天然兼容大语言模型(LLM)的生成能力,尤其适合集成到当前主流的文本到图像生成流程中。
更重要的是,GNER在训练过程中引入了负例采样机制——即明确告诉模型“哪些不是实体”。这一改进显著提升了模型在模糊边界情况下的判断力。
实验表明,在 LLaMA 和 FLAN-T5 两类代表性生成模型上,加入负例训练后,实体识别性能大幅提升。最终模型 GNER-LLaMA 和 GNER-T5 在标准测试集上分别比当前最先进的方法高出 8 和 11 个 F1 分数点,达到新的性能标杆。
可集成、可部署:支持主流格式与模型
GNER 并非仅停留在论文阶段。目前,已经发布多款文本编码器,开发者OliviaRossi发布了GGUF 格式版本,支持本地部署与离线运行,便于在资源受限环境下使用。
这意味着开发者可以将 GNER 轻松集成到以下类型的系统中:
- 多模态生成模型:如 Flux、Krea、Chroma、HiDream 等
- 文本理解模块:作为 CLIP 文本编码器的替代组件,提升提示词解析精度
- 支持 FLAN-T5-XXL 等大规模生成模型的推理流程
通过替换原有文本编码路径,GNER 能帮助这些系统更准确地“理解”用户输入中的关键实体,从而提升生成内容的相关性与细节还原度。
实际效果对比:GNER vs. FLAN
以下是一个典型提示词的处理对比:
提示词:职业级的原始照片,展现一位身着诱人红色礼服的致命女人,手持手枪指向观众,特写镜头,黑暗小巷,午夜时分。
使用 GNER 解析后提取的实体:
- 红色礼服
- 致命女人
- 手持手枪
- 特写镜头
- 黑暗小巷
- 午夜时分

使用原始 FLAN 模型提取的结果:
- 女人
- 手枪
- 小巷
- 午夜

可见,GNER 不仅识别更完整,还能保留修饰词(如“红色”“致命”),这对于图像生成中的风格控制至关重要。
当然,最终视觉效果仍取决于生成模型本身的艺术表达倾向——正如作者所言:“哪个更好,取决于艺术品味。”但不可否认的是,GNER 提供了更丰富、更结构化的语义输入,为高质量生成打下更好基础。
为什么这值得关注?
在当前文本到图像、文本到视频等生成系统中,提示词解析的准确性常常成为瓶颈。许多“生成偏差”并非模型能力不足,而是因为关键信息被忽略或误读。
GNER 的出现,提供了一种轻量、高效、无需微调即可提升语义理解能力的解决方案。尤其对于以下场景具有实用价值:
- 开源本地生成工具(如 LM Studio、Ollama)集成高精度NER模块
- 提升自动标注、内容审核、知识抽取等下游任务表现
- 构建更智能的提示词优化建议系统
此外,其基于 GGUF 的发布形式,也降低了部署门槛,使更多个人开发者和小型团队能够受益。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...