EasyControl 框架:基于扩散变换器(DiT架构)的图像生成模型提供高效且灵活的条件控制能力Tiamat AI、上海科技大学、新加坡国立大学和Liblib AI的研究人员推出 EasyControl 框架,为基于扩散变换器(DiT架构)的图像生成模型提供高效且灵活的条件控制能力。它通过一系列...图像模型# DiT架构# EasyControl1年前03390
基于 GenAI 的视觉内容创作控制框架ZenCtrl:利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调ZenCtrl 是一款基于 GenAI 的视觉内容创作控制框架,专注于利用单张主体图像生成多视角、多样化场景的高分辨率图像,无需额外微调。它通过精细的控制能力和模块化设计,为创作者提供了一个强大且灵活...图像模型# OminiControl# ZenCtrl# 图像控制框架11个月前05550
Ideogram 3.0发布:更真实、更创意、更一致的生成式设计体验Ideogram在今天正式发布了其最新模型Ideogram 3.0,这款最新的AI生成模型不仅在图像质量和文本渲染方面取得了重大突破,还通过强大的风格控制功能和高效的设计能力,为创作者和专业人士提供了...图像模型# AI绘画# Ideogram# Ideogram 3.01年前05950
StarVector:利用多模态大语言模型(MLLM)从图像和文本生成SVG代码ServiceNow Research、魁北克人工智能研究所、加拿大 CIFAR 人工智能主席、不列颠哥伦比亚大学、高等工程技术学院和苹果的研究人员推出StarVector,利用多模态大语言模型(ML...图像模型# StarVector# SVG代码# 多模态大语言模型1年前04850
个性化图像生成和编辑方法SISO:适合在只有单张主题图像的情况下使用巴伊兰大学和英伟达的研究人员推出一种无需训练的方法SISO,用于从单张主题图像进行个性化图像生成和编辑。SISO 是一种无需训练的方法,通过优化与输入主题图像的相似度分数来实现图像的个性化生成和编辑...图像模型# SISO# 图像生成# 图像编辑1年前02080
URAE:基于 Flux的超高分辨率图像生成的高效解决方案在图像生成领域,高分辨率图像的生成一直是一个极具挑战性的问题,尤其是在训练数据和计算资源有限的情况下。新加坡国立大学的研究人员推出了一种名为 URAE(Ultra-Resolution Adaptat...图像模型# FLUX# URAE1年前04140
Yandex Research推出分层蒸馏框架SWD:加速扩散模型(如FLUX和SD3.5)的生成过程Yandex Research 推出了一种名为 “Scale-wise Distillation of Diffusion Models (SWD)” 的新型框架,通过分层采样策略加速扩散模型(DMs...图像模型# FLUX# SD3.5# SWD1年前06180
新型图像编辑框架PhotoDoodle:通过文字提示在照片中添加艺术化装饰新加坡国立大学、上海交通大学、北京邮电大学、字节跳动和Tiamat的研究人员推出新型图像编辑框架PhotoDoodle,通过少量样本学习艺术家的独特风格,将装饰元素(如手绘线条、装饰图案等)无缝叠加到...图像模型# PhotoDoodle# 图像编辑框架# 照片涂鸦1年前02980
字节跳动推出新型框架 InfiniteYou (InfU):用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片字节跳动推出新型框架 InfiniteYou (InfU),用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片。该框架利用先进的扩散变换器(Diffusion Transformers...图像模型# InfiniteYou# InfU# 字节跳动1年前01960
SANA模型的升级版SANA 1.5:实现高质量的图像生成,同时显著降低了训练和推理成本英伟达、麻省理工学院、清华大学、Playground和北京大学的研究团队推出了SANA模型的升级版SANA 1.5,这是一款高效的DiT架构模型,通过创新的训练和推理策略,实现文本到图像生成任务中的高...图像模型# DiT架构模型# SANA 1.5# 文生图模型1年前03430
Illustrious XL v2.0正式发布,支持1024x1536原生分辨率生成在开源AI绘画模型领域,Flux模型是众多衍生开发的基础。然而,在二次元领域,尤其是日式风格方面,情况有所不同。目前,大量用户依然以SDXL模型为基础进行衍生开发。在开源社区中,Pony、Illust...图像模型# Illustrious XL v2.0# SDXL# 二次元1年前02,9150
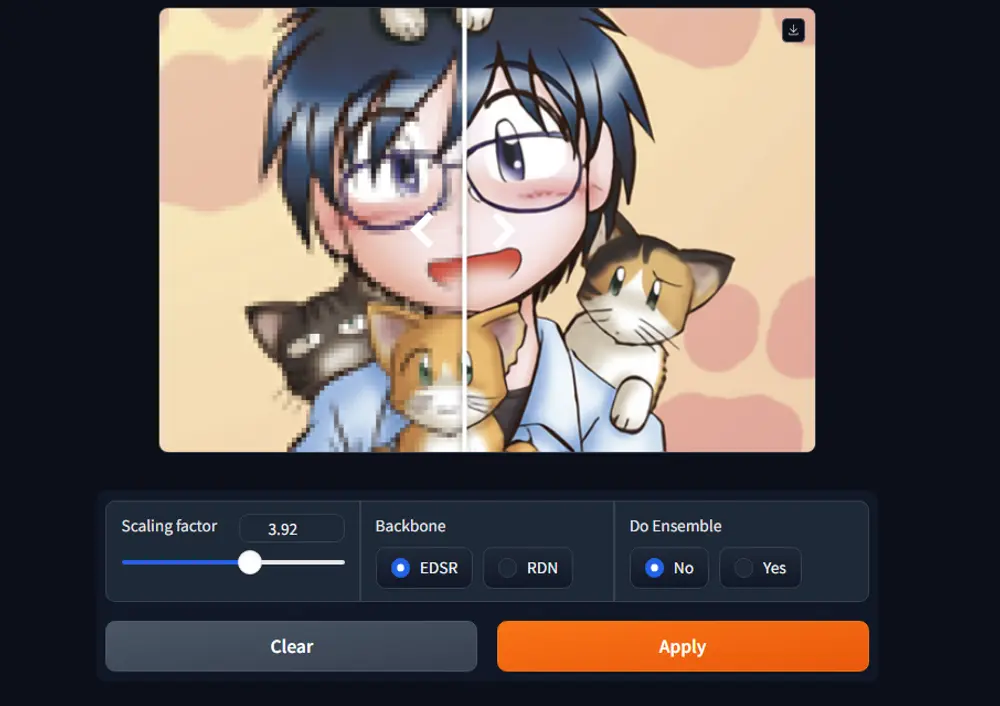
基于神经热场的无混叠任意尺度超分辨率(ASR)方法Thera:实现高质量的图像超分辨率重建苏黎世联邦理工学院和苏黎世大学的研究人员推出一种基于神经热场(Neural Heat Fields)的无混叠任意尺度超分辨率(ASR)方法Thera,该方通过结合神经场(Neural Fields)和...图像模型# Thera# 图像放大# 图像高清1年前06990