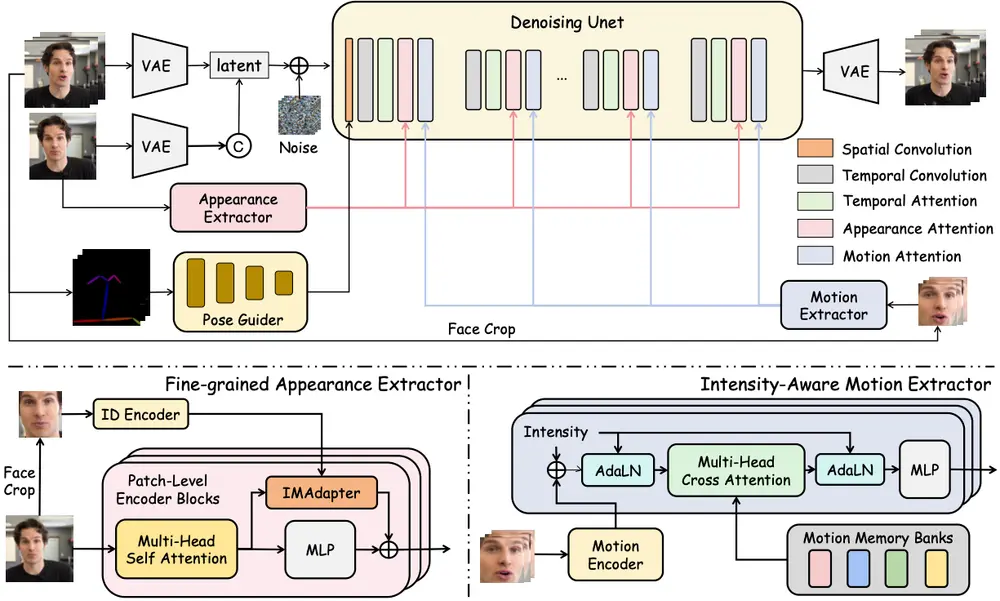
腾讯混元项目组推出数字人头像生成模型 HunyuanPortrait :用于高度可控且逼真的肖像动画生成腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模...视频模型# HunyuanPortrait# 腾讯混元10个月前01960
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型10个月前04250
别让好模型消失,这个 WAN2.1 LoRA 合集值得收藏”近日,CivitAI 在 Visa 和 Mastercard 的压力下进一步收紧内容政策,导致平台上大量 模型被删除。这些模型中包含了许多创作者精心训练的作品,尤其是 NSFW类内容。 地址:http...视频模型# WAN2.1 LoRA11个月前01,1380
视频生成模型的高效推理新方案Jenga:无需重新训练模型即可实现HunyuanVideo和Wan2.1显著提速近年来,基于 DiT架构的视频生成模型在生成质量上取得了显著突破,但其高昂的计算成本却严重限制了实际部署与落地。 为了解决这一瓶颈,来自香港中文大学、香港科技大学、快手科技和思谋科技的研究团队提出了 ...视频模型# HunyuanVideo# Jenga# Wan2.111个月前05130
可控角色动画生成框架RealisDance-DiT:在处理稀有姿态、风格化角色、角色与物体的交互、复杂光照和动态场景等挑战性问题时表现出色阿里巴巴达摩院、浙江大学、湖畔实验室、南方科技大学和深圳大学的研究人员推出可控角色动画生成框架RealisDance-DiT,其在处理稀有姿态、风格化角色、角色与物体的交互、复杂光照和动态场景等挑战性...视频模型# RealisDance-DiT# Wan 2.1# 动画生成11个月前05250
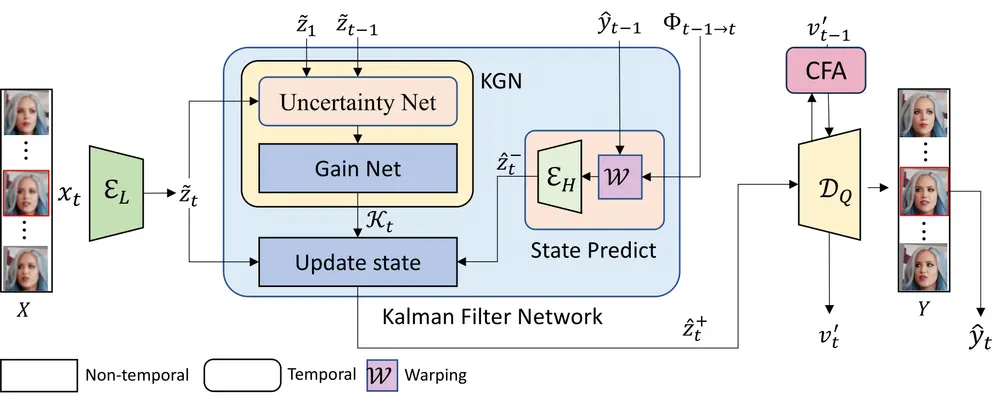
视频人脸超分辨率的新型框架KEEP:解决视频中人脸图像的超分辨率问题,同时保持时间一致性视频人脸超分辨率(VFSR)的目标是从低分辨率(LR)或严重退化的视频中重建出高分辨率(HR)的人脸图像。尽管人脸图像超分辨率(FSR)领域已经取得了显著进展,但视频人脸超分辨率仍然是一个相对较少被研...视频模型# KEEP# 视频人脸超分辨率11个月前01930
B站Index团队开源动漫视频生成模型 AniSora:一键生成多种风格的动漫视频片段哔哩哔哩(B站)Index团队开源了一款名为 AniSora 的动漫视频生成模型。作为目前最强大的开源动漫视频生成工具,AniSora 能够一键生成多种风格的动漫视频片段,包括番剧剧集、国创动画、漫画...视频模型# AniSora# B站# 动漫视频生成模型11个月前05260
阿里通义实验室 Wan 团队正式释出Wan2.1-VACE模型:支持视频生成与编辑的模型阿里通义实验室Wan 团队正式释出了Wan2.1-VACE模型,这是一款支持视频生成与编辑的模型,单一模型可同时支持文生视频、图像参考视频生成、视频重绘、视频局部编辑、视频背景延展以及视频时长延展等全...视频模型11个月前02600
腾讯混元团队开源多模态定制化视频生成工具Hunyuan Custom:融合文本、图像、音频、视频等多模态输入生视频的能力在内容创作领域,视频生成技术正不断进化,但如何让生成的视频既保持主体一致性,又能实现多样化的场景和动作变化,一直是创作者面临的难题。今天,腾讯混元团队正式推出并开源了一款全新的多模态定制化视频生成工具...视频模型# Hunyuan Custom# 多模态定制# 腾讯11个月前04760
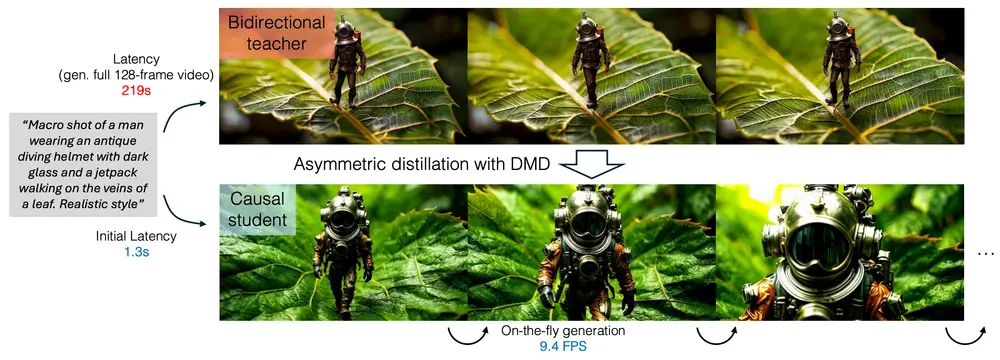
新型自回归视频扩散模型CausVid:解决传统双向扩散模型在交互式应用中的高延迟问题麻省理工学院和Adobe的研究人员推出新型自回归视频扩散模型CausVid,旨在解决传统双向扩散模型在交互式应用中的高延迟问题。通过将双向扩散模型蒸馏为快速自回归生成器,CausVid 能够实现低延迟...视频模型# CausVid# 自回归视频扩散模型11个月前04550
腾讯推出新型图生视频框架FlexiAct:实现灵活的视频动作克隆腾讯和清华大学的研究人员推出新型图生视频框架FlexiAct,实现灵活的动作控制,能够在异构场景(即具有不同空间结构、骨骼结构或视角的场景)中将参考视频中的动作迁移到任意目标图像上,同时保持动作动态和...视频模型# FlexiAct# 图生视频11个月前03860
Lightricks 推出全新开源视频生成模型 LTXV-13BLightricks之前推出的都是小尺寸模型,而在今天它宣布推出其最新且最先进的开源视频生成模型——LTXV-13B,这一模型不仅在质量、速度和可访问性方面实现了显著提升,还为创作者提供了强大的工具...视频模型# Lightricks# LTXV-13B# 视频生成模型11个月前04390