
新Chrome 全面拥抱 Gemini:侧边栏助手、自动浏览与个人智能登场,非美区开启教程
谷歌正持续将 Gemini 大模型全面接入旗下全线产品,从日历自动排期、云端硬盘与相册智能整理,到 Gmail 智能辅助处理,AI 能力不断下沉。近期,谷歌正式公布,将 Gemini 核心能力深度整合...

新商汤开源 SenseNova-MARS:多模态自主推理模型登顶 MMSearch 榜单
商汤科技正式开源 SenseNova-MARS —— 一款支持动态视觉推理与图文搜索深度融合的多模态大模型(VLM)。该模型提供 8B 与 32B 双版本,在多模态搜索与推理核心基准 MMSearch...
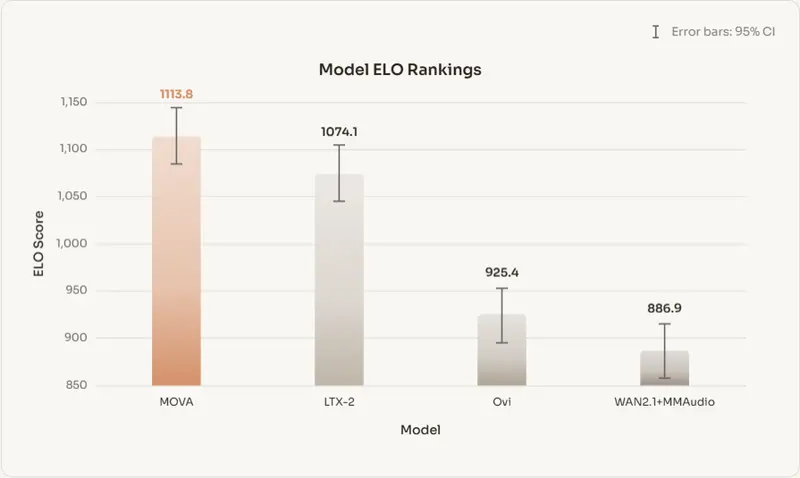
新模思智能推出 MOVA:开源同步音视频生成基座模型,打破“无声视频”困局
模思智能正式开源 MOVA(MOSS Video and Audio)——一款专注于原生同步生成视频与音频的基座模型。针对当前主流系统(如 Sora 2、Veo 3)普遍采用的“先画后音”级联流程,M...
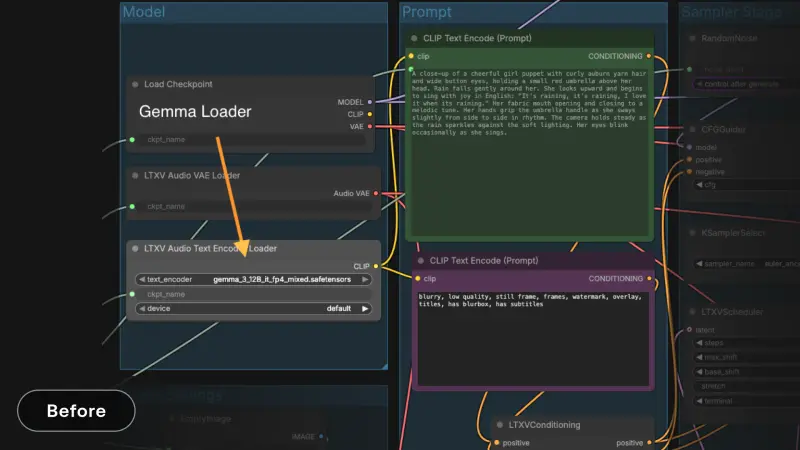
新LTX-2 一月末更新:Gemma 编码节点优化 + 多模态引导器 + IC-LoRA 升级,强化视频工作流控制
Lightrick官方发布LTX-2一月末更新,本次更新围绕创作者在真实世界视频工作流中的核心需求——更高精度、更灵活的可控性展开,通过优化Gemma文本编码节点、新增多模态引导器、升级IC-LoRA...
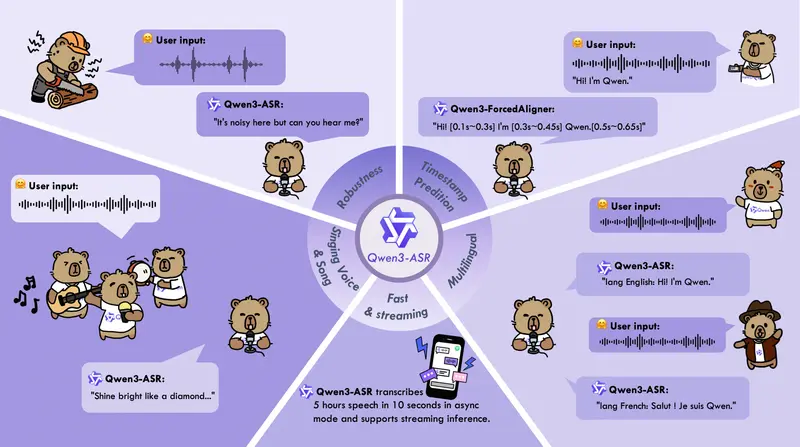
新通义千问开源 Qwen3-ASR 与 Qwen3-ForcedAligner:支持流式、多语言、高并发的语音识别与对齐工具
Qwen(通义千问)团队正式开源全新一代语音技术方案——Qwen3-ASR系列语音识别模型与Qwen3-ForcedAligner强制对齐模型。该系列包含Qwen3-ASR-1.7B、Qwen3-AS...
新ComfyUI DiffSynth Studio Wrapper:在 ComfyUI 中调用 Z-Image I2L 实现图像到 LoRA 的实时转换
ComfyUI DiffSynth Studio Wrapper 是一个轻量级自定义节点封装器,旨在将 DiffSynth-Studio 的 Z-Image I2L(Image-to-LoRA)功能无...

新Gemini 3 Flash 引入智能体视觉:视觉推理+代码执行,答案基于视觉证据
谷歌正式为 Gemini 3 Flash 推出全新能力——智能体视觉,通过将视觉推理与代码执行深度结合,让AI从“静态一瞥”升级为“主动调查”,彻底改变图像理解方式。这项功能可使多数视觉基准测试质量提...
新Genie 3驱动!Project Genie 上线:文本/照片生成可探索世界,限时60秒体验
Google DeepMind 正式宣布,实验性AI工具 Project Genie 即日起向美国地区的 Google AI Ultra 订阅用户开放访问。这款由最新世界模型 Genie 3、图像生成...
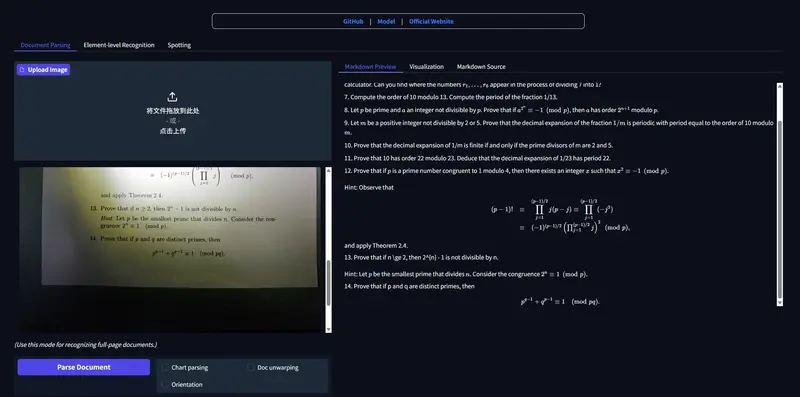
新百度飞桨发布PaddleOCR-VL-1.5:0.9B轻量多模态模型,真实场景文档解析全面SOTA
百度飞桨近期完成 PaddleOCR 3.4.0 版本更新,正式推出新一代视觉语言模型 PaddleOCR-VL-1.5。这款面向真实场景的文档解析专用模型,仅0.9B参数量却实现资源高效与性能领先...

新腾讯混元推出 HunyuanImage 3.0-Instruct:原生多模态图像编辑模型,支持精准编辑与多图融合
腾讯混元项目组正式开源 HunyuanImage 3.0-Instruct —— 一款专注于图像编辑的原生多模态大模型。该模型不仅能理解输入图像的语义内容,还能基于复杂指令进行推理,并生成高保真、高一...





