
艾伦AI研究所在成功推出Tülu 3之后,又在昨天宣布推出Tülu 3 405B——这是首次将完全开放的后训练方法应用于最大规模的开放权重模型。此次发布不仅展示了艾伦AI研究所在大规模参数模型上的可扩展性和有效性,同时也为语言模型的训练提供了一种新的路径。
- 官方介绍:https://allenai.org/blog/tulu-3-405B
- 模型:https://huggingface.co/collections/allenai/tulu-3-models-673b8e0dc3512e30e7dc54f5
- Demo:https://playground.allenai.org/?model=tulu3-405b
主要亮点
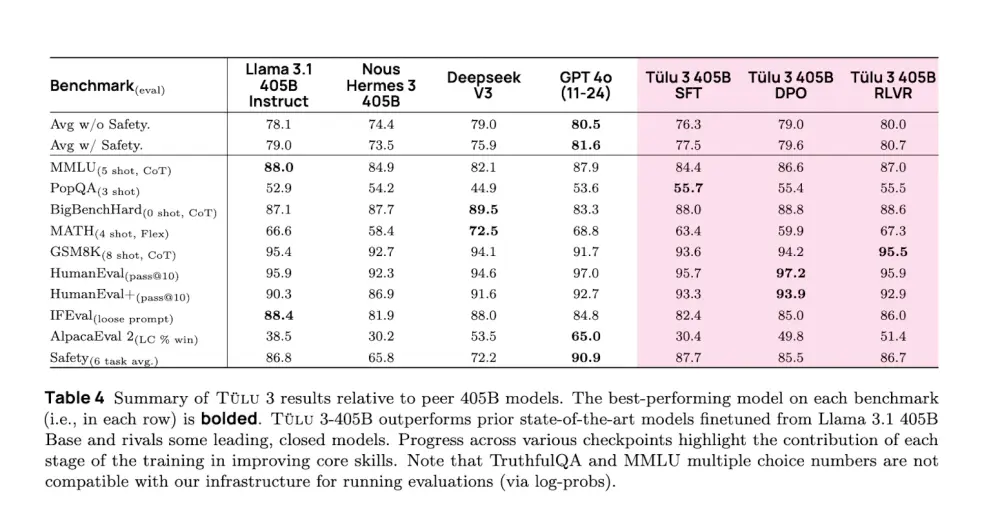
- 基于验证奖励的强化学习(RLVR):Tülu 3 405B采用了一种新颖的基于可验证奖励的强化学习框架(RLVR),尤其在数学问题解决和指令遵循等任务上表现出色。
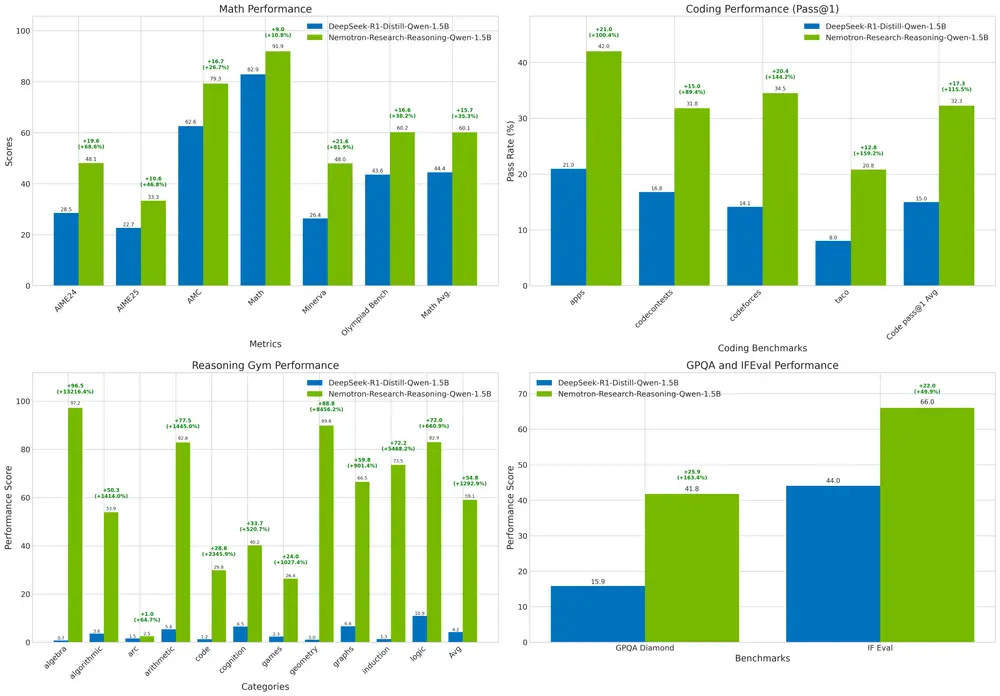
- 性能优势:在多个标准基准测试中,Tülu 3 405B的表现优于或与DeepSeek v3和GPT-4o相当,并超越了先前相同规模的开放权重后训练模型。
- 数据管理和合成:采用了细致的数据管理策略,包括监督微调(SFT)、直接偏好优化(DPO)以及针对核心技能的合成数据使用。
技术挑战与解决方案
在扩大到405B参数规模的过程中,项目团队面临了计算资源需求高、超参数调整受限等挑战。通过利用vLLM和16路张量并行部署,团队能够有效地进行模型推理和训练。尽管遇到了一些技术难题,如NCCL同步问题,但最终还是实现了稳健的训练流程。
应用场景与未来方向
Tülu 3 405B适用于需要高度精确和低延迟响应的应用场景,例如数学问题解答、指令执行等。对于未来的改进,团队计划探索更大的价值模型或尝试无价值模型的替代算法,以进一步降低RLVR阶段的计算成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











