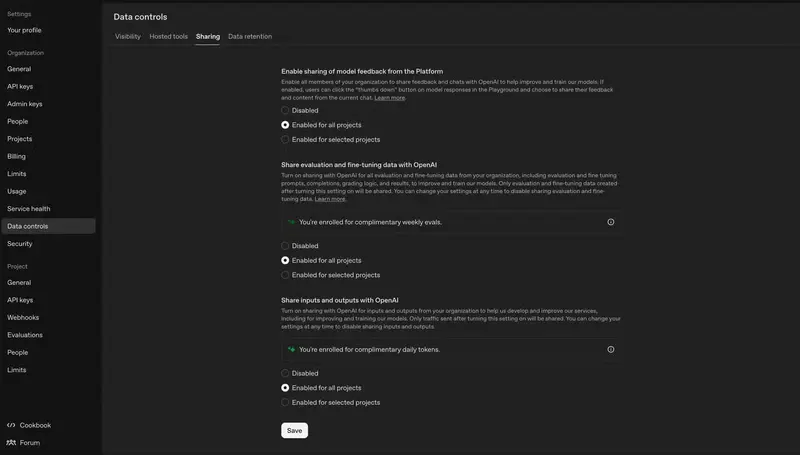
谷歌即将推出一款全新的 AI 模型——Gemini 2.5 Flash。这款模型主打高效性与灵活性,特别适合高容量、实时应用的场景,例如客户服务和文档解析。

Gemini 2.5 Flash 将很快登陆谷歌的 AI 开发平台 Vertex AI,并为开发者提供一种动态且可控的方式来优化性能与成本之间的平衡。以下是关于这款新模型的详细介绍及其潜在应用场景。
Gemini 2.5 Flash 的核心特点
1. 动态计算能力
Gemini 2.5 Flash 提供“动态且可控”的计算能力,允许开发者根据查询的复杂性调整处理时间。这意味着用户可以根据具体需求,在速度、准确性和成本之间找到最佳平衡点。
速度优先:适用于需要快速响应的场景,例如实时客服对话。 准确性优先:适用于对精度要求较高的任务,例如法律文件解析或医疗数据分析。 成本优化:通过降低计算资源的使用,减少运行成本。
谷歌表示:“这种灵活性是优化 Flash 在高容量、成本敏感型应用中性能的关键。”
2. 高效推理模型
Gemini 2.5 Flash 是一种“推理”模型,类似于 OpenAI 的 o3-mini 和 DeepSeek 的 R1。这类模型的特点是在回答问题时会稍慢一些,以便进行自我事实核查,从而提高输出的可靠性。
尽管推理速度略逊于顶级模型,但其在效率和成本方面的优势使其成为一个极具吸引力的选择,特别是在需要大规模部署的应用场景中。
3. 专为高容量与实时应用设计
谷歌强调,Gemini 2.5 Flash 是一款“主力模型”,专门针对低延迟和降低成本进行了优化。它非常适合以下应用场景:
客户服务:作为虚拟助手,快速响应用户问题。 文档解析:高效处理大量文本数据,生成摘要或提取关键信息。 实时工具:例如会议记录生成、聊天机器人等。
“它是响应式虚拟助手和实时摘要工具的理想引擎,在这些场景中大规模效率至关重要。” 谷歌在博客文章中写道。
为何选择 Gemini 2.5 Flash?
1. 成本效益显著
随着旗舰 AI 模型的成本持续攀升,许多企业和开发者开始寻找更经济实惠的替代方案。Gemini 2.5 Flash 以一定的准确性为代价,提供了高性能的同时大幅降低了运行成本,成为昂贵顶级模型的有力竞争者。
2. 灵活性与可扩展性
Gemini 2.5 Flash 的动态计算能力使其能够适应多种不同场景的需求。无论是需要快速响应还是更高精度的任务,开发者都可以通过调整参数来优化模型表现。
3. 支持本地化部署
谷歌还宣布,从第三季度开始,包括 Gemini 2.5 Flash 在内的 Gemini 系列模型将引入本地环境。这些模型将可通过 Google Distributed Cloud (GDC) 使用,这是谷歌 为具有严格数据治理要求的客户提供的本地解决方案。
此外,谷歌正与 Nvidia 合作,将 Gemini 模型引入符合 GDC 标准的 Nvidia Blackwell 系统。客户可以通过谷歌或其首选渠道购买这些系统,从而在本地环境中安全高效地运行 AI 模型。
Gemini 2.5 Flash 的局限性
尽管 Gemini 2.5 Flash 提供了许多令人兴奋的功能,谷歌并未为其发布详细的安全或技术报告。公司表示,对于其认为“实验性”的模型,通常不会提供相关报告。这使得外界难以全面评估该模型的优劣势。
不过,谷歌强调,Gemini 2.5 Flash 主要面向的是那些对成本敏感且需要大规模部署的应用场景,而非对精度要求极高的任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











