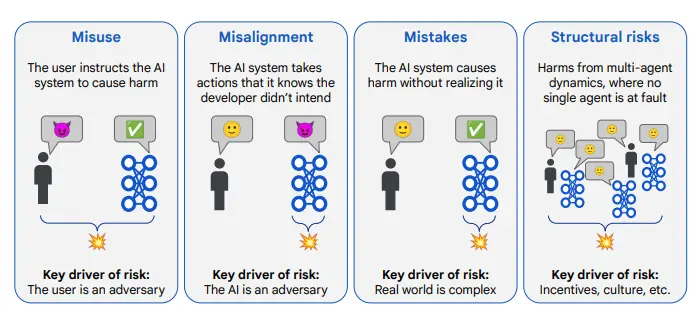
谷歌 DeepMind 的首席执行官 Demis Hassabis 近日在 X 平台(原 Twitter)上对用户关于“能否用 Veo 3 玩游戏”的提问回应称:“这会是件大事吧。”这一简短回复引发了广泛关注。
随后,谷歌 AI Studio 和 Gemini API 产品负责人 Logan Kilpatrick 也以一串 “🤐🤐🤐🤐” 表情符号回应,进一步增添了神秘色彩。尽管目前谷歌官方尚未透露更多细节,但这些来自高层的“戏谑式暗示”无疑激发了业界对其在可玩世界模型方向发展的期待。
世界模型 vs 视频生成模型:本质区别
虽然谷歌最新发布的视频生成模型 Veo 3 在视觉质量和物理模拟方面表现出色,但它仍属于被动输出型视频生成模型,而非真正意义上的“世界模型”。
什么是世界模型?
- 可预测环境变化与行为响应;
- 支持智能体(AI 或人类)实时交互;
- 构建动态、可探索的虚拟世界;
- 实现从输入到反馈的闭环系统。
Veo 3 的定位:
- 擅长生成高质量视频片段(最长 8 秒);
- 支持语音、音效、背景音乐同步生成;
- 物理模拟逼真,适用于电影化叙事;
- 尚未具备实时交互和动态响应能力。
换句话说,Veo 3 是一个视觉生成引擎,而非一个可被“游玩”的世界。
谷歌在世界模型上的布局与进展
尽管 Veo 3 尚未达到世界模型的标准,但谷歌在该领域已有深厚积累,并展现出明确的技术路线图。
✅ Genie 2:迈向可玩世界的一步
2024 年 12 月,DeepMind 发布了 Genie 2,一个基于自回归潜在扩散模型的框架,能够通过单张图像生成无限多样的 3D 世界,并支持键盘和鼠标交互。
- 基于大规模视频数据训练;
- 模拟物体交互、动画、物理、光照和 NPC 行为;
- 已被视为“大型现实模型”的代表之一。
✅ 新团队组建:专注现实模拟模型
2025 年初,谷歌成立了一个由前 OpenAI Sora 项目联合负责人 Tim Brooks 领导的新团队,目标是构建能够模拟真实世界动态的 AI 模型。此举表明,谷歌正在加速向 AGI(通用人工智能)迈进。
💡 Veo 3 的潜力与局限性
✔️ 优势
- 高质量视频生成能力;
- 精准的物理动作模拟;
- 支持语音、音效、背景音乐;
- 可用于游戏中的过场动画、预告片制作等。
❌ 局限
- 仅生成固定长度视频片段;
- 缺乏实时互动与动态反馈;
- 不支持玩家输入驱动的场景演变;
- 当前仍属“展示型”模型。
因此,尽管 Veo 3 在视觉呈现上令人惊艳,它仍无法实现真正的“可玩性”。
🔄 可能的发展路径:混合架构成为突破口
要让 Veo 3 成为可玩世界模型的一部分,谷歌可能采取一种混合方法:
| 模块 | 功能 | 可能使用的技术 |
|---|---|---|
| 视觉生成 | 创建高保真图像与动画 | Veo 3 |
| 世界交互 | 提供可操作的 3D 场景 | Genie 2 |
| 控制逻辑 | 实时响应玩家输入 | 强化学习 + 多模态控制 |
这种组合方式不仅能够利用 Veo 3 的视觉生成能力,还能借助 Genie 2 的交互式世界生成技术,推动游戏、虚拟现实、教育等领域的创新应用。
竞争格局:谷歌并非唯一挑战者
谷歌并非唯一一家在探索世界模型的公司:
- World Labs(李飞飞创立):能从单一图像生成类游戏的 3D 场景,具备空间记忆能力。
- OpenAI Sora:视频生成能力强大,但尚未公开交互功能。
- Scenario、Runway、Pika:各自在视频生成与编辑方面持续突破。
- 微软:结合其 Azure AI 云服务和大模型资源,也在推进相关研究。
不过,凭借 Gemini 模型、DeepMind 技术实力以及 YouTube、Google Maps 等庞大数据资源,谷歌在构建复杂世界模型方面仍具有显著优势。
社区与行业观点:期待与质疑并存
X 平台上的讨论反映出两种声音:
- 乐观派:认为 Veo 3 的物理模拟能力接近世界模型门槛,未来可期;
- 理性派:指出当前模型仍为“预设内容”,距离真正可交互、可修改的世界还有距离。
此外,也有开发者担忧谷歌在将前沿研究成果产品化方面的执行力,认为其在落地速度上可能落后于一些初创企业,如 World Labs 和以色列的 Decart。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











