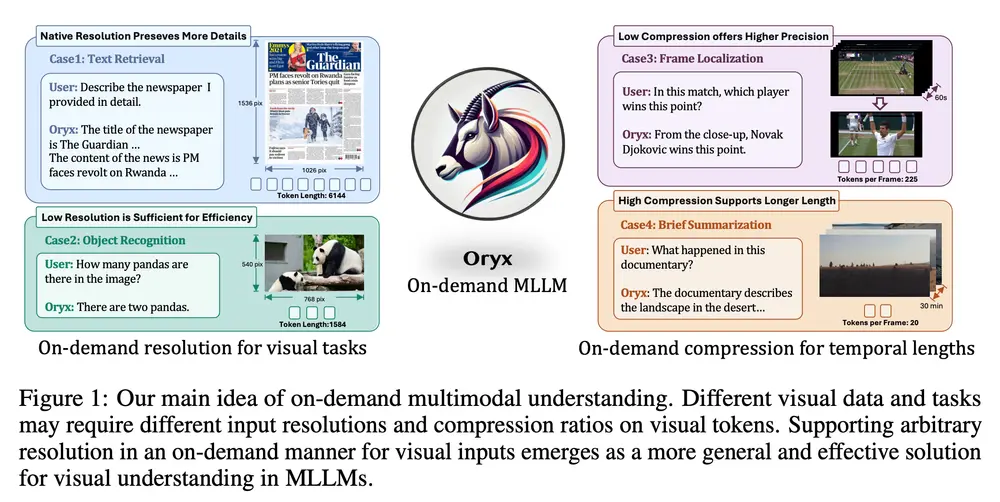
多模态大语言模型Oryx:专门设计用于理解和处理视觉数据,如图像、视频和3D场景清华大学、腾讯和南洋理工大学 S-Lab的研究人员推出多模态大语言模型Oryx,它专门设计用于理解和处理视觉数据,如图像、视频和3D场景。Oryx模型的特点是能够根据需要处理任意空间大小和时间长度的视...新技术# Oryx# 多模态大语言模型2年前06360
新型图像到视频生成技术OSV:可以将单张图像仅仅一步内生成高质量视频复旦大学、香港科技大学、香港中文大学和腾讯优图实验室的研究人员推出新型图像到视频生成技术OSV,可以将单张图像转换成视频。这项技术的目标是能够快速生成高质量的视频内容,而不需要复杂的多步骤处理。例如...新技术# OSV2年前04460
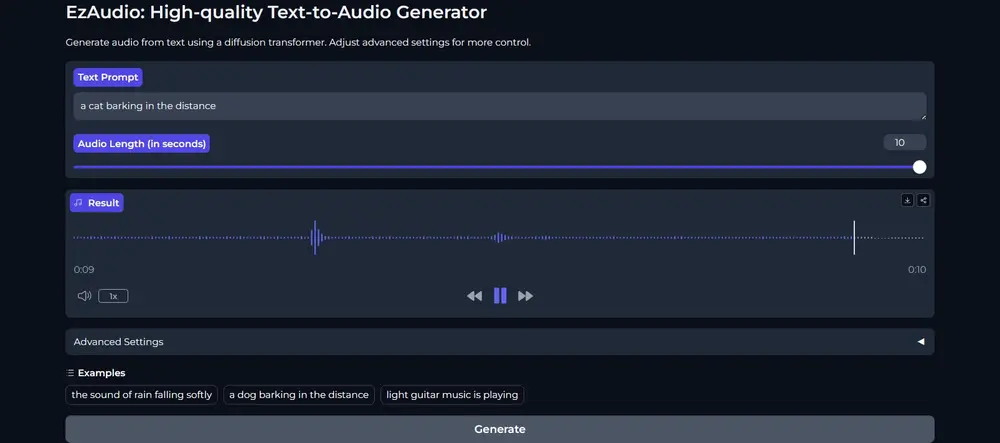
新型高品质文本音频生成器EzAudio:将文本描述转换成相应的音频内容约翰·霍普金斯大学和腾讯人工智能实验室的研究人员推出一种新型的文本到音频(Text-to-Audio,简称T2A)生成技术EzAudio,这项技术的目标是将文本描述转换成相应的音频内容,比如将“一只狗...新技术# EzAudio# 文本音频生成器2年前06350
diffusion-e2e-ft:通过微调图像条件扩散模型来简化和提高单目深度估计的效率亚琛工业大学和埃因霍温理工大学的研究人员推出diffusion-e2e-ft,通过微调图像条件扩散模型来简化和提高单目深度估计的效率。单目深度估计是指仅使用一张图片来预测场景中每个像素的深度信息。这项...新技术# diffusion-e2e-ft# 单目深度估计2年前06150
北京人工智能研究院推出新型图像生成模型OmniGen北京人工智能研究院推出新型图像生成模型OmniGen,与流行的扩散模型(例如,Stable Diffusion)不同,OmniGen不再需要额外的模块,如ControlNet或IP-Adapter来处...新技术# OmniGen# 图像生成模型1年前04550
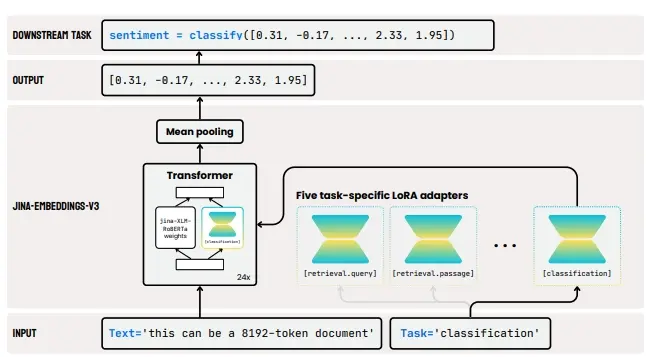
Jina AI推出新型文本嵌入模型 jina-embeddings-v3:专为多语言数据和长文本检索任务优化Jina AI推出文本嵌入模型 jina-embeddings-v3,这是一个具有 5.7 亿参数的新型文本嵌入模型,它在多语言数据和长上下文检索任务上实现了最先进的性能,支持的最大上下文长度达到 8...新技术# jina-embeddings-v3# 文本嵌入模型2年前04440
音乐生成系统Seed-Music:能够创作出高质量的音乐,并且可以根据用户的细致要求来调整音乐的风格和内容字节跳动旗下豆包团队推出音乐生成系统Seed-Music,能够创作出高质量的音乐,并且可以根据用户的细致要求来调整音乐的风格和内容。Seed-Music结合了自回归语言建模和扩散方法,支持两种关键的音...新技术# Seed-Music# 音乐生成2年前04660
图像编辑方法Click2Mask:通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述耶路撒冷希伯来大学的研究人员推出图像编辑方法Click2Mask,它能够让用户通过简单的点击来实现对图片的局部编辑,而不需要复杂的遮罩或详细的描述。总的来说,Click2Mask提供了一种直观且高效的...新技术# Click2Mask# 图像编辑2年前04630
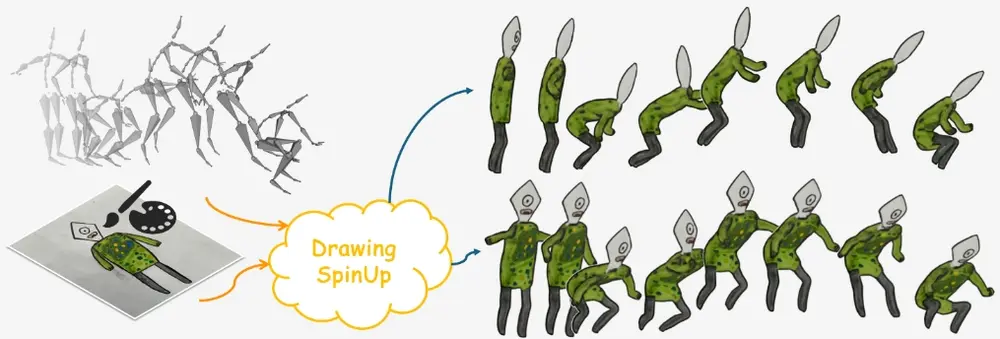
DrawingSpinUp:将单一的平面角色绘画转换成三维动画,同时保留了原始艺术作品的风格和特征香港城市大学的研究人员推出创新系统DrawingSpinUp,它能够将单一的平面角色绘画转换成三维动画,同时保留了原始艺术作品的风格和特征。这就像是给一张静态的画注入生命,让它动起来,比如让一个纸上的...新技术# DrawingSpinUp2年前04460
图像编辑框架InstantDrag:通过简单的拖拽操作来编辑图片,就像在手机上操作APP一样直观和快速首尔国立大学和浦项科技大学的研究人员推出图像编辑框架InstantDrag,它能够让用户通过简单的拖拽操作来编辑图片,就像在手机上操作APP一样直观和快速。例如,你有一张图片,你想要移动图片中的某个部...新技术# InstantDrag# 图像编辑2年前04620
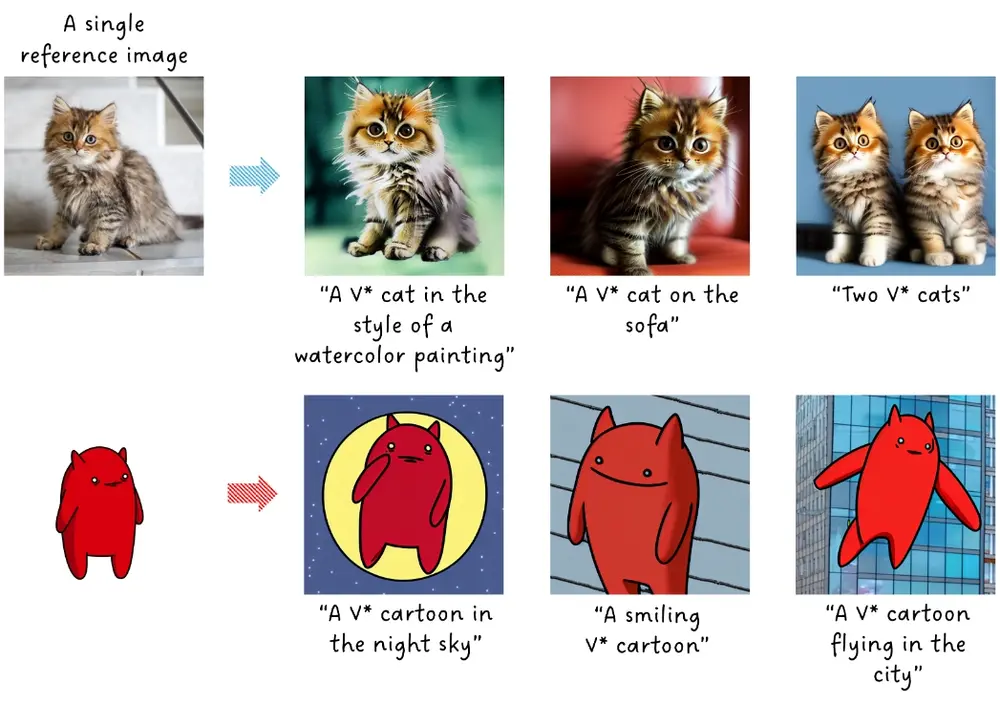
针对文生图模型的一次性个性化定制技术TextBoost:使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像韩国科学技术院推出一种针对文本到图像模型的一次性个性化定制技术TextBoost,这种方法使用单个参考图像,通过微调文本编码器,来生成与文本提示相匹配的定制化图像。例如,你想要通过一段描述来生成一张图...新技术# TextBoost# 个性化定制# 文生图模型2年前05590
IFAdapter:提升基于文本生成图像的扩散模型在生成多个实例时的精确度和细节控制能力而设计腾讯PCG和新加坡国立大学的研究人员推出新型方法IFAdapter,它是为了提升基于文本生成图像(Text-to-Image,简称T2I)的扩散模型在生成多个实例时的精确度和细节控制能力而设计的。简单...新技术# IFAdapter2年前04760