香港大学 & 达摩院等联合推出:首个第一人称现实世界模拟器 PlayerOne由香港大学、阿里达摩院、湖畔实验室和华中科技大学联合研发的全新现实世界模拟系统 PlayerOne 正式亮相。这是首个以第一人称(egocentric)视角为核心的现实世界模拟器,标志着AI在沉浸式交...新技术# PlayerOne# 现实世界模拟器10个月前02750
苹果推出可扩展生成模型STARFlow:基于归一化流(NFs),在高分辨率图像合成方面取得了显著的成果苹果推出了一个名为STARFlow的可扩展生成模型,它基于归一化流(Normalizing Flows,NFs),在高分辨率图像合成方面取得了显著的成果。STARFlow的主要构建块是Transfor...新技术# STARFlow# 可扩展生成模型10个月前01920
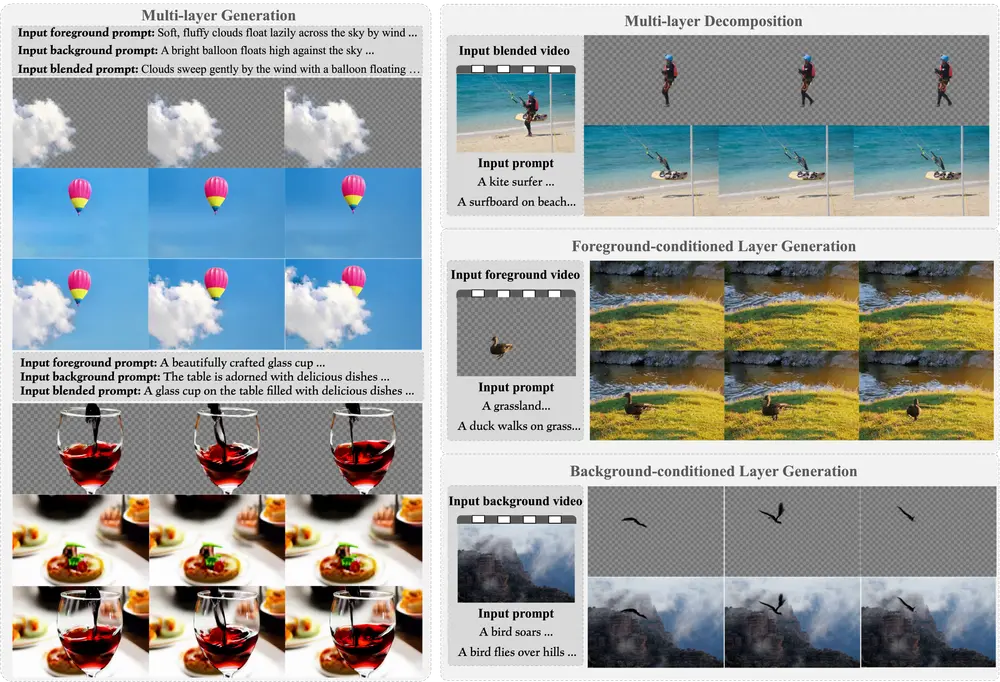
香港大学联合阿里团队推出 LayerFlow:重新定义视频生成逻辑香港大学、阿里达摩院与湖畔实验室的研究团队近日发布LayerFlow——一款专为层感知视频生成设计的统一框架。不同于传统视频生成方案,LayerFlow通过分层提示机制,可同步生成透明前景、纯净背景及...新技术# LayerFlow# 阿里# 香港大学10个月前01970
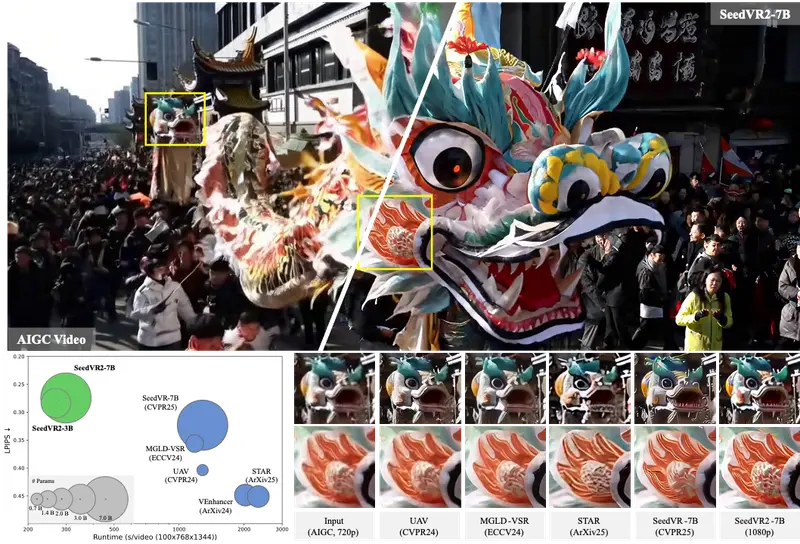
新型单步视频修复(VR)技术SeedVR2:通过扩散模型和对抗性后训练(APT)实现高效、高质量的视频修复和超分辨率南洋理工大学和字节跳动的研究人员推出一种新型单步视频修复(VR)技术SeedVR2,通过扩散模型(Diffusion Model)和对抗性后训练(Adversarial Post-Training, ...新技术# SeedVR2# 视频修复10个月前03190
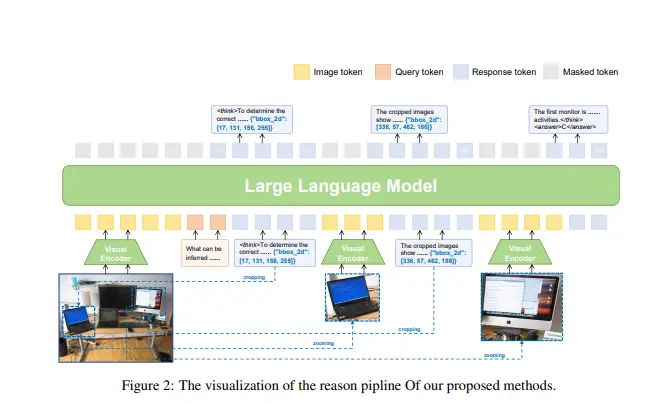
VLM-R3:增强多模态链式思考(CoT)的能力北京大学国家软件工程工程研究中心、阿里巴巴和中科智库的研究人员推出VLM-R3的框架,增强多模态链式思考(CoT)的能力。VLM-R3通过动态和迭代地关注和重新访问图像区域,实现文本推理在视觉证据中的...新技术# VLM-R3# 多模态推理10个月前03820
韩国科学技术院推出TIC-FT:用时间上下文微调解锁视频扩散模型的精准控制在视频生成领域,我们正见证一场静默但深刻的变革。随着文本到视频扩散模型的质量不断提升,其输出已接近专业制作水平。然而,如何实现对视频生成过程的精确控制——例如根据特定图像或短片引导视频风格、动作或构图...新技术# TIC-FT# 时间上下文微调10个月前03600
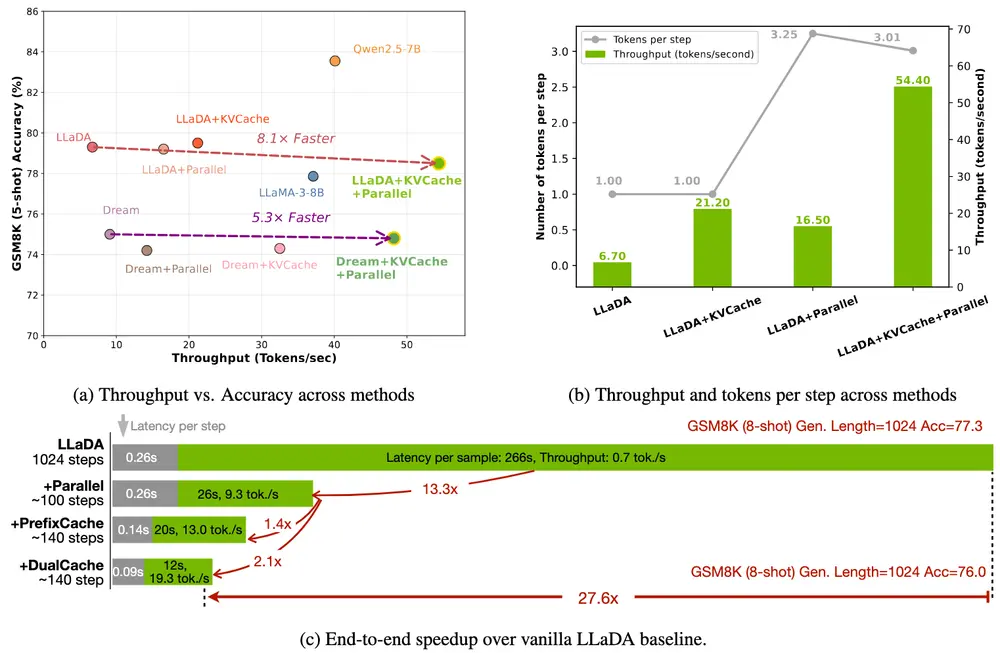
英伟达联合 MIT 与港大推出 Fast-dLLM:显著提升扩散模型推理效率近日,英伟达(NVIDIA)联合麻省理工学院(MIT)与香港大学的研究团队,推出了名为 Fast-dLLM 的新型框架,解决当前扩散模型(Diffusion-based LLMs)在推理效率和生成质量...新技术# Fast-dLLM# 扩散模型10个月前01760
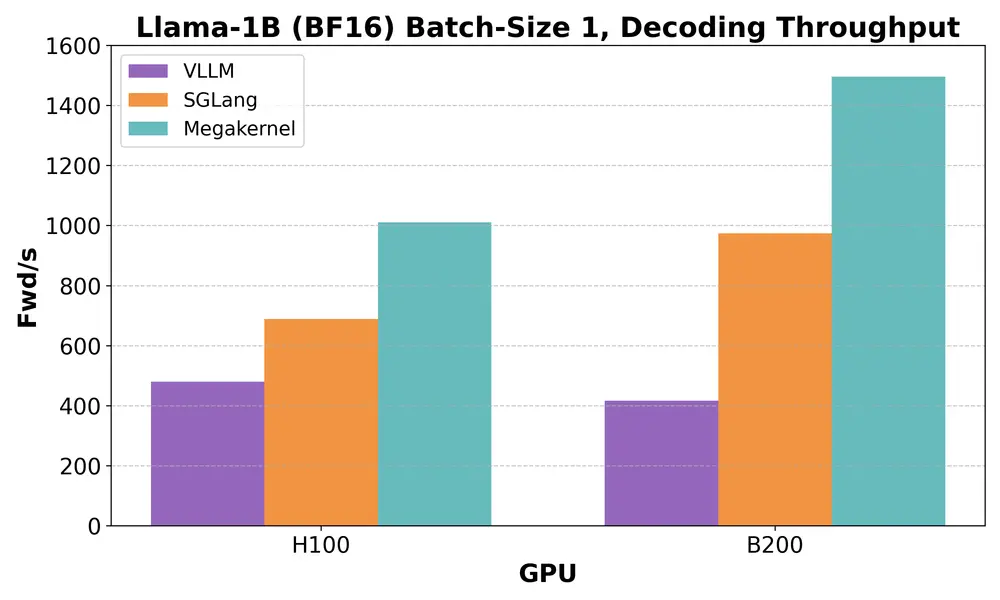
用“Megakernel”打破LLM推理瓶颈:斯坦福Hazy Research实现Llama-1B史上最低延迟在一些对响应速度极为敏感的应用场景中,例如对话式 AI 或人机协同的工作流系统,语言模型的推理延迟不仅影响效率,更直接影响用户体验。 以 Llama-3.2-1B 这类小型开源模型为例,在单序列生成任...新技术# Llama-1B# Megakernel10个月前08200
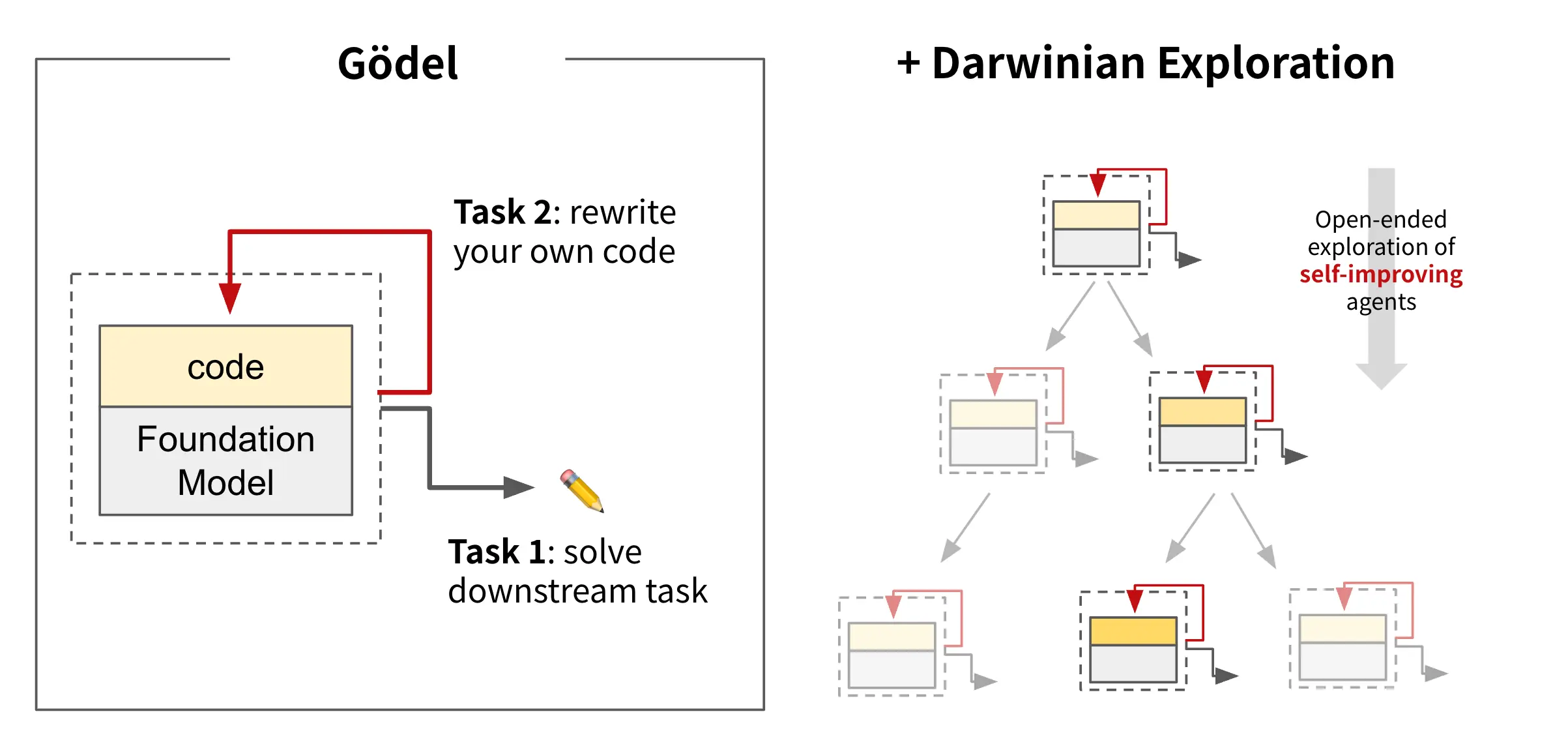
Darwin Gödel Machine(DGM):能够自主修改自身代码的 AI智能体在AI研究领域,一个长期目标是构建能够“无限学习”的系统——不仅在训练中学习,在部署后也能持续自我演化和提升。这一愿景的核心思想源自 哥德尔机器(Gödel Machine),它是一种理论上具备自修改...新技术# AI智能体# Darwin Gödel Machine10个月前02900
阿里通义实验室推出基于浏览器的自主信息检索智能体WebDancer:像人类一样在复杂的网络环境中进行多步骤的信息搜索和推理阿里通义实验室推出基于浏览器的自主信息检索智能体WebDancer,它能够像人类一样在复杂的网络环境中进行多步骤的信息搜索和推理。WebDancer通过模仿人类浏览网页的行为,利用搜索和点击等工具,逐...新技术# WebDancer# 检索智能体# 阿里通义实验室10个月前02520
新型图像到视频生成技术 Frame In-N-Out:突破传统视频生成中帧边界限制,实现更自由、更具创意的视频生成效果弗吉尼亚大学和Adobe Research的研究人员推出新型图像到视频生成技术 Frame In-N-Out,突破传统视频生成中帧边界限制,实现更自由、更具创意的视频生成效果。具体来说,Frame I...新技术# Frame In-N-Out# 图生视频11个月前03450
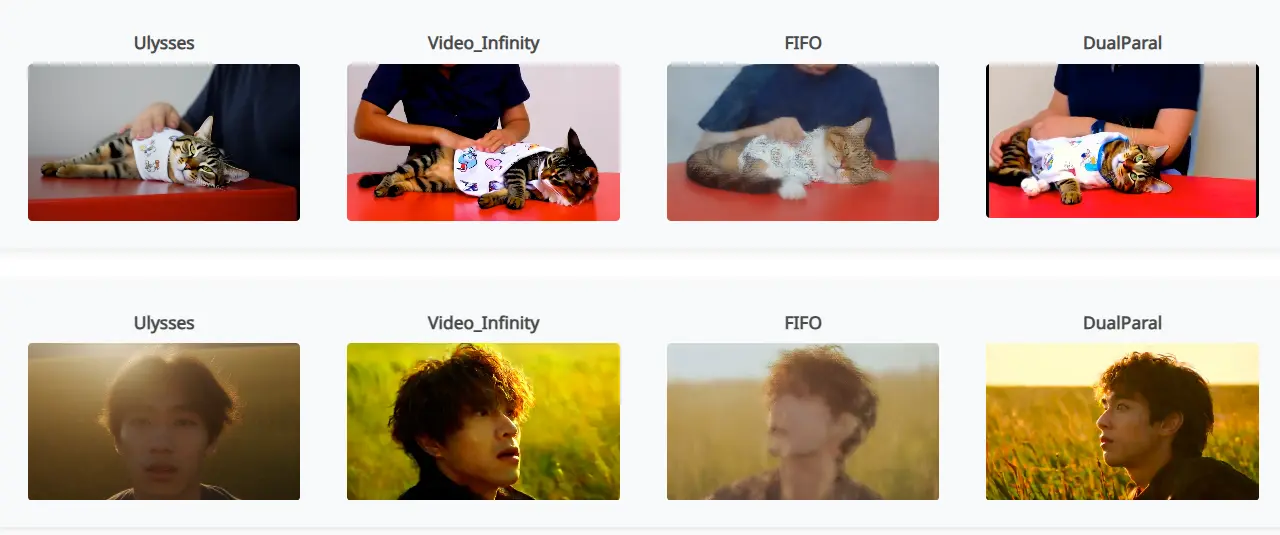
基于Wan2.1模型的分布式推理策略 DualParal:用于高效生成极端长视频新加坡国立大学、西安电子科技大学和华中科技大学的研究人员推出分布式推理策略 DualParal,用于高效生成极端长视频。该策略针对基于DiT架构模型(Wan2.1mox ),这些模型在生成高质量视频方...新技术# DualParal# Wan2.1模型# 分布式推理策略11个月前03140