
北京大学国家软件工程工程研究中心、阿里巴巴和中科智库的研究人员推出VLM-R3的框架,增强多模态链式思考(CoT)的能力。VLM-R3通过动态和迭代地关注和重新访问图像区域,实现文本推理在视觉证据中的精确定位。
例如,在分析一张包含多个物体的图像时,VLM-R3能够逐步验证假设、跟踪物体状态或理解复杂的空间关系,从而得出准确的结论。
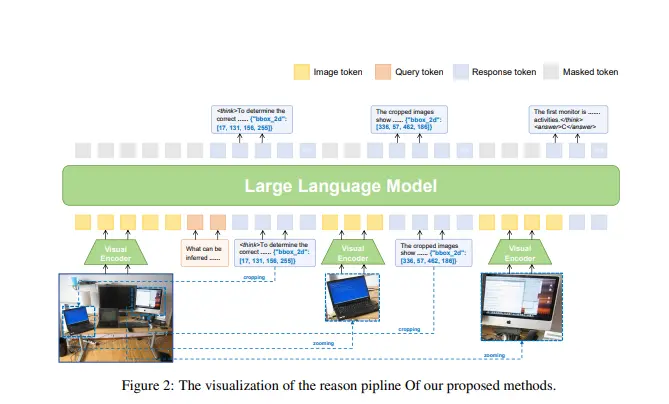
主要功能
- 区域识别与推理:决定何时需要额外的视觉证据,确定在图像中何处进行定位,并将相关的子图像内容无缝地融入交错的思考链中。
- 动态视觉聚焦:在推理过程中动态选择和处理图像区域,如裁剪和放大,以获取更详细的视觉信息。
- 多步推理:支持多步推理,允许模型在推理链中多次查询和处理图像区域。
主要特点
- 区域条件强化策略优化(R-GRPO):通过奖励模型选择信息丰富的区域、制定适当的变换(如裁剪、放大)并将结果视觉上下文整合到后续推理步骤中,优化模型的区域选择和推理能力。
- Visuo-Lingual Interleaved Rationale(VLIR)数据集:为训练和评估提供步骤级监督,包含视觉区域定位、图像裁剪指令和语义增强线索的显式注释。
- 交互式推理管道:允许模型在推理过程中动态选择和整合视觉信息,支持多步、自适应的视觉定位。
工作原理
VLM-R3的工作原理基于以下关键部分:
- 数据集VLIR:通过精心策划的数据集提供步骤级监督,帮助模型学习如何在推理过程中动态选择和处理图像区域。
- 交互式推理管道:模型在推理过程中可以动态地选择和处理图像区域,如裁剪和放大,以获取更详细的视觉信息。处理后的图像区域被编码为视觉标记并附加到模型的输入序列中,为模型提供新的上下文。
- R-GRPO训练策略:通过强化学习优化模型的区域选择和推理策略,奖励模型选择信息丰富的区域并将其整合到推理链中。
测试结果
- 多模态推理基准测试:在MathVista、ScienceQA等基准测试中,VLM-R3在零样本和少样本设置中均取得了新的最佳性能,特别是在需要微妙空间推理或精细视觉线索提取的问题上表现突出。
- 具体性能提升:在MathVista上,VLM-R3的准确率从68.2%提升到70.4%;在MathVision上,准确率从25.1%提升到30.2%;在ScienceQA上,准确率从73.6%提升到87.9%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











