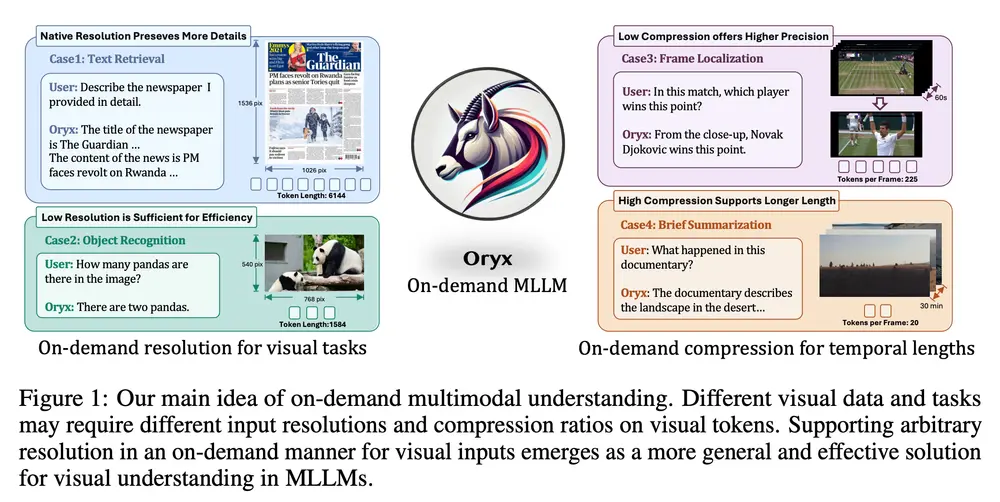
由香港大学、阿里达摩院、湖畔实验室和华中科技大学联合研发的全新现实世界模拟系统 PlayerOne 正式亮相。这是首个以第一人称(egocentric)视角为核心的现实世界模拟器,标志着AI在沉浸式交互环境建模领域迈出了重要一步。
PlayerOne 能够根据用户上传的第一人称场景图像,构建一个动态、逼真的虚拟世界,并生成与用户通过外视角(exocentric)相机捕捉到的真实动作高度对齐的视频内容。这项技术为虚拟现实、增强现实、数字人交互等前沿领域带来了新的可能性。

核心功能亮点
1. 实时动作捕捉与对齐
用户可以通过外部摄像头捕捉自己的动作(如伸手拿物、转身走动等),PlayerOne 可实时生成与之完全同步的虚拟角色动作视频。
2. 场景一致性建模
在长视频生成过程中,PlayerOne 保证了场景结构的一致性,避免传统模型常见的“场景错乱”或“物品凭空消失”等问题。
3. 自由运动控制
支持多样化的自然动作输入,而非仅限于预设动作,真正实现用户自由探索虚拟世界的体验。
4. 高效生成能力
借助模型蒸馏等技术优化,PlayerOne 支持实时视频生成,具备良好的落地应用潜力。
核心技术突破
1. 部分解耦的动作注入(PMI)
将人体动作拆分为头部、手部和身体三个部分分别处理,再合并注入模型,实现更精确的动作控制,尤其在头部姿态和视角变化上表现优异。
2. 联合场景-帧重建(SR)
同时建模 4D 场景点云和视频帧信息,确保生成视频不仅动作准确,场景也高度一致,特别适用于长时间视频生成任务。
3. 粗到细的训练策略
先在大规模第一人称文本-视频数据集上进行粗粒度预训练,随后在高质量动作-视频对上进行微调,提升模型泛化能力并弥补数据稀缺问题。
4. 自动化数据集构建流程
从现有的第一人称-第三人称视频数据集中自动提取动作-视频配对样本,构建高质量训练数据,降低人工标注成本。
工作原理简析
PlayerOne 的整体流程如下:
- 输入处理
- 用户上传一张第一人称视角图片作为初始场景;
- 同步使用外视角摄像头捕捉用户的实际动作序列。
- 动作解耦与编码
- 将动作分解为头部、手部、身体三个部分;
- 分别通过专用编码器提取潜在表示,并融合后注入生成模型。
- 场景建模与重建
- 利用点云重建技术生成 4D 场景点云图;
- 使用带适配器的编码器提取场景特征并与视频特征融合。
- 视频生成与去噪
- 在 DiT 模型中对融合后的潜在空间进行加噪与去噪操作;
- 最终通过 VAE 解码器输出视频结果。
- 推理阶段简化
- 推理时只需提供第一帧图像和动作序列即可完成生成。
实验验证与性能表现
定量评估
PlayerOne 在多个关键指标上优于现有方法:
- DINO-Score(衡量视觉一致性)表现优异;
- CLIP-Score(文本-图像匹配度)显著提升;
- MPJPE(关节位置误差)更低,说明动作建模更加精准。
用户研究反馈
用户对 PlayerOne 生成视频的评价包括:
- 视觉质量高;
- 动作流畅自然;
- 场景一致性好;
- 与文本描述或动作输入高度对齐。
动作对齐测试
通过不同动作条件下生成的视频对比,验证了 PlayerOne 在复杂动作响应上的稳定性和准确性。
未来展望
PlayerOne 是以第一人称视角为核心的世界建模系统的首次尝试,为未来的沉浸式交互系统提供了坚实基础。它不仅推动了 AI 在真实动态环境建模中的边界,也为以下方向打开了新思路:
- 更自然的虚拟人交互体验;
- 基于第一视角的智能助手系统;
- 结合AR/VR的沉浸式游戏引擎;
- 个性化虚拟世界构建工具。
尽管目前仍面临诸如长序列记忆维持、物理规律约束等挑战,但其创新性的架构设计与训练策略已展现出巨大的发展潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











