图像风格化技术B-LoRA:将单张图片中的风格和内容分离,从而实现高质量的图像风格化处理来自特拉维夫大学和赖希曼大学的研究团队推出B-LoRA(Block Low-Rank Adaptation),它能够将单张图片中的风格和内容分离,从而实现高质量的图像风格化处理。图像风格化是指在保持图...新技术# B-LoRA# 图像风格化2年前05810
苹果推出开源图像编辑模型MGIE:通过文字提示来编辑任何图像来自苹果的团队推出开源图像编辑模型MGIE(MLLM-Guided Image Editing),它旨在通过使用多模态大语言模型(MLLMs)来提升基于指令的图像编辑能力。简单来说,MGIE可以帮助用...新技术# MGIE# 图像编辑# 苹果2年前05810
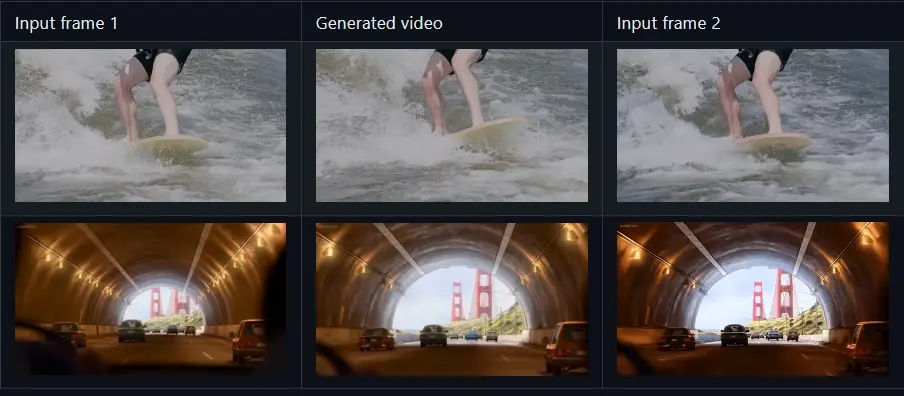
谷歌推出首尾帧图生视频新方法Generative Inbetweening:在两个关键帧之间产生连贯的运动华盛顿大学、谷歌 DeepMind和加州大学伯克利分校的研究人员推出一种用于生成视频序列的方法Generative Inbetweening,能够在两个关键帧之间产生连贯的运动。简单来说,就是给定视频...新技术# Generative Inbetweening# 插帧# 视频序列2年前05800
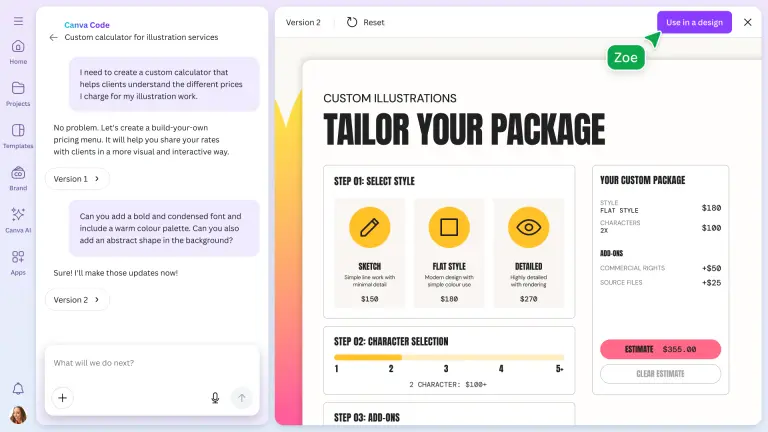
Canva全面拥抱AI:新增图像生成、交互式编程与电子表格功能设计工具领域的领军企业Canva近日宣布推出一系列全新AI功能,进一步扩展其平台的能力。这些新功能包括AI助手(Canva AI)、通过提示创建交互式应用程序的能力(Canva Code)、AI驱动的...早报# AI# Canva1年前05790
OpenAI发布全新GPT-4.1系列模型:GPT-4.1、GPT-4.1 mini和GPT-4.1 nano本周一,OpenAI发布了全新的模型系列——GPT-4.1,包括GPT-4.1、GPT-4.1 mini和GPT-4.1 nano。这些模型在编程和指令遵循方面表现出色,标志着OpenAI在打造“代理...大语言模型早报# GPT-4.1# GPT-4.1 mini# GPT-4.1 nano1年前05770
Adobe MAX大会亮点!Adobe旗下多个应用发布新功能,视频生成功能已上线Adobe Premiere Pro和Adobe Firefly今天,在美国迈阿密海滩举行的Adobe MAX大会上,Adobe发布了最新版本的Adobe Creative Cloud,其中包括超过100项新功能,涵盖了Photoshop、Illustrator...早报# Adobe Firefly# Adobe MAX# Adobe Premiere Pro2年前05770
分布式长视频生成框架Video-Infinity:能够利用多个GPU并行工作,快速生成长时间的视频内容新加坡国立大学的研究人员推出Video-Infinity系统,它是一个分布式的长视频生成框架。简单来说,Video-Infinity能够利用多个GPU(显卡)并行工作,快速生成长时间的视频内容。这对于...新技术# Video-Infinity# 长视频生成框架2年前05770
3D重建模型MeshLRM:基于LRM的方法,能够从极少量的输入图像(仅需四张)快速重建出高质量的3D网格模型来自加州大学圣地亚哥分校和Adobe的研究人员推出大型3D重建模型MeshLRM,这是一种新颖的基于LRM的方法,它能在不到一秒的时间内,能够从极少量的输入图像(仅需四张)快速重建出高质量的3D网...新技术# 3D重建模型# MeshLRM2年前05770
Scaling (Down) CLIP:从数据、架构和训练策略三个维度对CLIP进行了详细探究来自加州大学圣克鲁斯分校和Google Deepmind的研究人员发布论文探讨如何有效地缩减对比语言-图像预训练(CLIP)模型的规模,以适应计算资源有限的情况。研究团队从数据、架构和训练策略三个维度...新技术# CLIP模型2年前05760
图像编辑框架StableDrag:通过点(handle points)来精确控制图像编辑南京大学软件新技术国家重点实验室和腾讯公司研究团队推出图像编辑框架StableDrag,它专注于通过点(handle points)来精确控制图像编辑。 项目主页 论文地址 StableDrag提供了...新技术# StableDrag# 图像编辑2年前05760
新型高效微调方法SaRA:用于提升预训练扩散模型(SD 1.5、SD 2.0和SD 3.0)在新任务上的表现上海交通大学和腾讯优图实验室的研究人员推出新型高效微调方法SaRA,用于提升预训练扩散模型在新任务上的表现。扩散模型是一种强大的生成模型,能够生成图像、视频和3D模型等。但这些模型通常需要大量的参数...新技术# SaRA# 微调模型2年前05750
基准测试CommonsensenT2I:用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力宾夕法尼亚大学和加州大学圣塔芭芭拉分校的研究人员推出基准测试CommonsensenT2I,用于评估文生图模型(T2I)生成符合现实生活常识的图像的能力。简单来说,就是研究这些模型是否能够根据文字描述...新技术# CommonsensenT2I# 基准测试# 文生图模型2年前05750