阿里巴巴Wanx 团队推出新型多模态生成模型ACE:可以根据文本指令来执行复杂的图像编辑和生成任务阿里巴巴Wanx 团队推出新型多模态生成模型ACE,这个模型的核心功能是处理和生成图像,但它与传统的图像处理工具不同,因为它可以根据文本指令来执行复杂的图像编辑和生成任务。例如,你是一名摄影师,你拍摄...新技术# ACE# 阿里巴巴1年前06700
自回归技术StreamingT2V:能够创建具有丰富运动动力学的长视频,不会出现停滞现象来自Picsart AI研究部门、得克萨斯大学奥斯汀分校、佐治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究团队推出先进的自回归技术StreamingT2V,能够创建具有丰富运动动力学的长视频,不会出...新技术# StreamingT2V# 自回归技术2年前06690
谷歌推出基于问答的自动评估指标Gecko,用于评估文生图模型的性能谷歌推出基于问答的自动评估指标Gecko2K,用于评估文生图模型的性能。文生图模型生成的图像并不总是能够完全符合文本中的所有细节。因此,评估这些模型生成的图像与文本描述的匹配程度是一个重要的研究问题...新技术# Gecko# Gecko2K# 自动评估2年前06680
新型视觉模型EfficientViT:专门用于高分辨率的密集预测任务来自MIT、浙江大学、清华大学、MIT-IBM Watson AI实验室的研究人员推出新型视觉模型EfficientViT,它专门用于高分辨率的密集预测任务。这类任务在计算机视觉领域非常重要,应用范围...新技术# EfficientViT# 视觉模型2年前06670
DragAnything:视频生成中任意对象的运动控制来自快手、浙江大学和新加坡国立大学的研究团队推出DragAnything,它是一种用于视频生成和控制的方法,它利用实体表示法来实现对视频生成中任意对象的运动控制。 项目主页 GitHub 论文 例如...新技术# DragAnything# 视频生成# 运动控制2年前06670
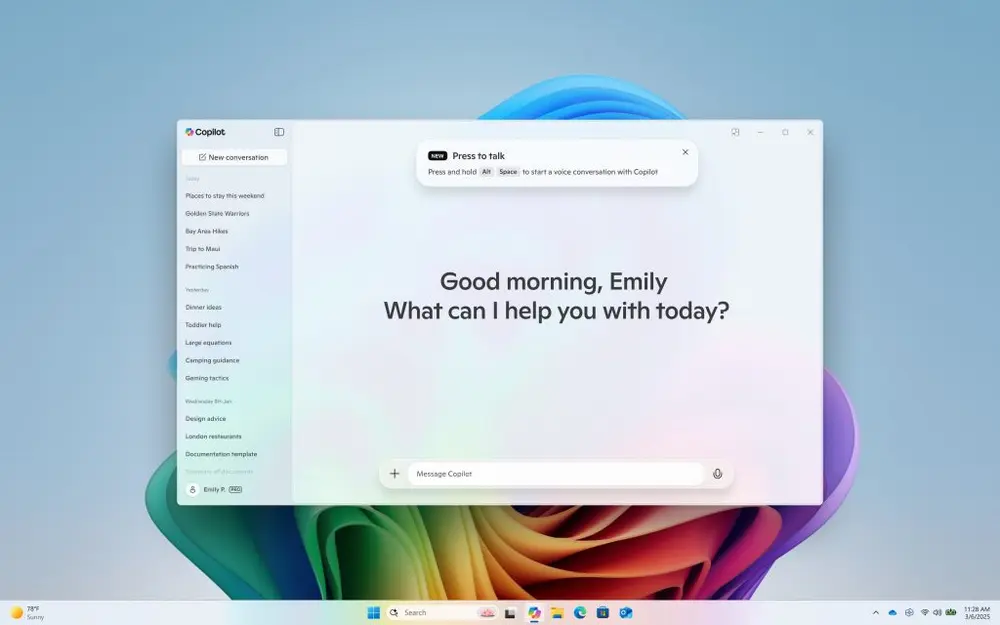
如何在 Windows 11 上启用或禁用 Copilot 的“Alt + 空格键”语音快捷键Windows 11 的 Copilot 应用最近引入了一个便捷的“Alt + 空格键”快捷键功能,允许用户通过“按下说话”或“按住说话”与聊天机器人互动。这一功能从版本 1.25024.100.0 ...教程# Copilot# Windows 11# 语音1年前06640
开源图像标注模型JoyTag:没有任何过滤和审查JoyTag是一个机器学习研究者推出的开源图像标注模型,该模型是在Danbooru 2021 + 手动标记的图像数据集上训练的,对训练的内容和标签没有任何过滤和审查,适用于从手绘到摄影的各种图像,在处...新技术# JoyTag# 图像标注模型# 开源2年前06630
TTT-Video:通过引入 Test-Time Training(TTT)层,成功让DiT 模型能够从文本故事板生成长达一分钟的视频英伟达联合斯坦福大学、加州大学圣地亚哥分校、加州大学伯克利分校和德克萨斯大学奥斯汀分校的研究人员,通过引入 Test-Time Training(TTT)层,成功让预训练的 DiT 模型能够从文本故事...新技术# CogVideoX-5B# DiT 模型# TTT-Video1年前06610
英伟达推出图像生成模型家族Edify Image:能够生成高保真度的图像内容,并且具有像素级完美准确性英伟达推出图像生成模型家族Edify Image,它们能够生成高保真度的图像内容,并且具有像素级完美准确性。Edify Image利用了一系列级联的像素空间扩散模型,这些模型通过一个新颖的拉普拉斯扩散...新技术# Edify Image# 图像生成# 英伟达1年前06610
新型图像生成技术StrokeNUWA:利用大语言模型生成矢量图形StrokeNUWA是一种新型图像生成技术,用于仅通过大语言模型(LLM)生成矢量图形,无需依赖专门的视觉模块。 论文 该方法的关键创新在于利用矢量图形固有的视觉语义,将矢量图形编码为"笔画"标记,这...新技术# LLM# StrokeNUWA# 大语言模型2年前06610
DiT架构的文生视频模型xGen-VideoSyn-1:根据文本描述生成逼真的视频场景Salesforce推出新的文生视频模型xGen-VideoSyn-1,这个模型能够根据文本描述生成逼真的视频场景,它的设计灵感来源于OpenAI的Sora模型,并在此基础上进行了改进和创新。例如,你...新技术# xGen-VideoSyn# 文生视频模型2年前06600
基于优化框架的跨模态视频-音频生成方法Seeing and Hearing:能够同时生成视频和音频内容香港科技大学和腾讯 PCG ARC 实验室推出基于优化框架的跨模态视频-音频生成方法Seeing and Hearing,它能够同时生成视频和音频内容。方法的主要创新点在于,通过预训练的多模态模型(如...新技术# Seeing and Hearing# 优化框架# 跨模态视频-音频生成方法2年前06600