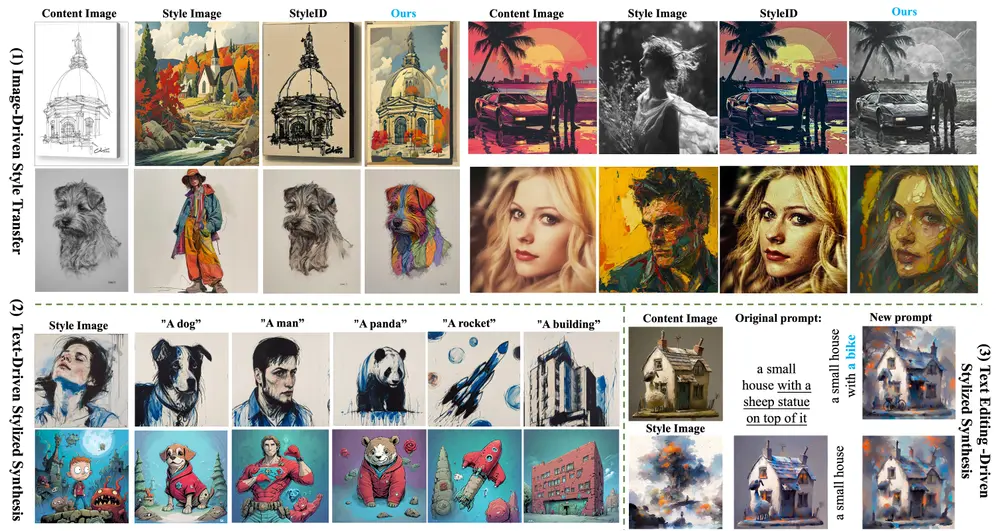
基于端到端训练的风格迁移模型CSGO:根据用户提供的文本描述和风格图像,生成具有特定风格的内容图像InstantX Team、南京理工大学、北京航空航天大学和北京大学的研究人员推出一种基于端到端训练的风格迁移模型CSGO,它是一个用于文本到图像生成的风格迁移模型。简单来说,CSGO能够根据用户提供...新技术# CSGO# 风格迁移模型2年前06590
多模态大语言模型Groma:具备精细化和定位化的视觉感知能力来自香港大学和字节跳动的研究人员推出多模态大语言模型Groma,它具备精细化和定位化的视觉感知能力。Groma不仅能够理解整个图像的内容,还能处理区域级别的任务,比如区域字幕(region capti...新技术# Groma# 多模态大语言模型2年前06590
多内容数据集ImagiNet:为了提高合成图像检测的泛化能力而设计保加利亚大特尔诺沃自然科学与数学高中、索非亚大学、保加利亚普罗夫迪夫数学高中和斯坦福大学的研究人员推出多内容数据集ImagiNet,它是为了提高合成图像检测的泛化能力而设计的。合成图像是由计算机生成的...新技术# ImagiNet# 数据集2年前06570
新型框架CSD:理解和从图像中提取风格描述符,可以实现对图像风格的检索、归因和匹配来自纽约大学、埃利斯研究所、马里兰大学帕克分校的研究人员推出新型框架CSD,旨在理解和从图像中提取风格描述符,可以实现对图像风格的检索、归因和匹配,特别适用于Stable Diffusion模型。 G...新技术# CSD# 图像风格2年前06570
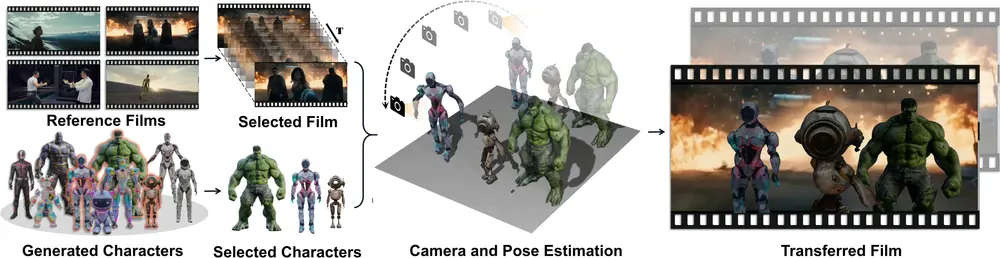
创新电影制作框架DreamCinema:利用AI技术简化了电影创作过程,使得个人也能轻松成为电影制作人清华大学推出创新电影制作框架DreamCinema,它利用AI技术简化了电影创作过程,使得个人也能轻松成为电影制作人。在这个数字化媒体蓬勃发展的时代,人们对于创造个性化、高质量的电影级视频有着广泛需求...新技术# DreamCinema# 电影2年前06560
神经网络架构MVDiffusion++:用于从单个或少量图像中重建3D物体来自西蒙弗雷泽大学和Meta Reality Labs的研究人员推出神经网络架构MVDiffusion++,它用于从单个或少量图像中重建3D物体。这个模型能够在没有相机姿态信息的情况下,生成密集且高分...新技术# 3D# MVDiffusion++# 神经网络架构2年前06560
新型文本到图像生成框架InstantStyle:在生成图像时保持一致的风格InstantX团队推出新型文本到图像生成框架InstantStyle,它专注于在生成图像时保持一致的风格。它通过简化风格迁移的过程,使得普通用户和专业人士都能够轻松地创造具有一致风格的图像。 项目主...新技术# InstantStyle# 风格2年前06540
RF-Solver和RF-Edit:提高校正流模型在图像和视频编辑中的反演精度基于校正流的DiT模型,如FLUX和OpenSora,在图像和视频生成领域展示了卓越的性能。然而,这些模型在反演过程中存在不准确的问题,这限制了它们在图像和视频编辑等下游任务中的有效性。为了解决这一问...新技术# RF-Edit# RF-Solver1年前06520
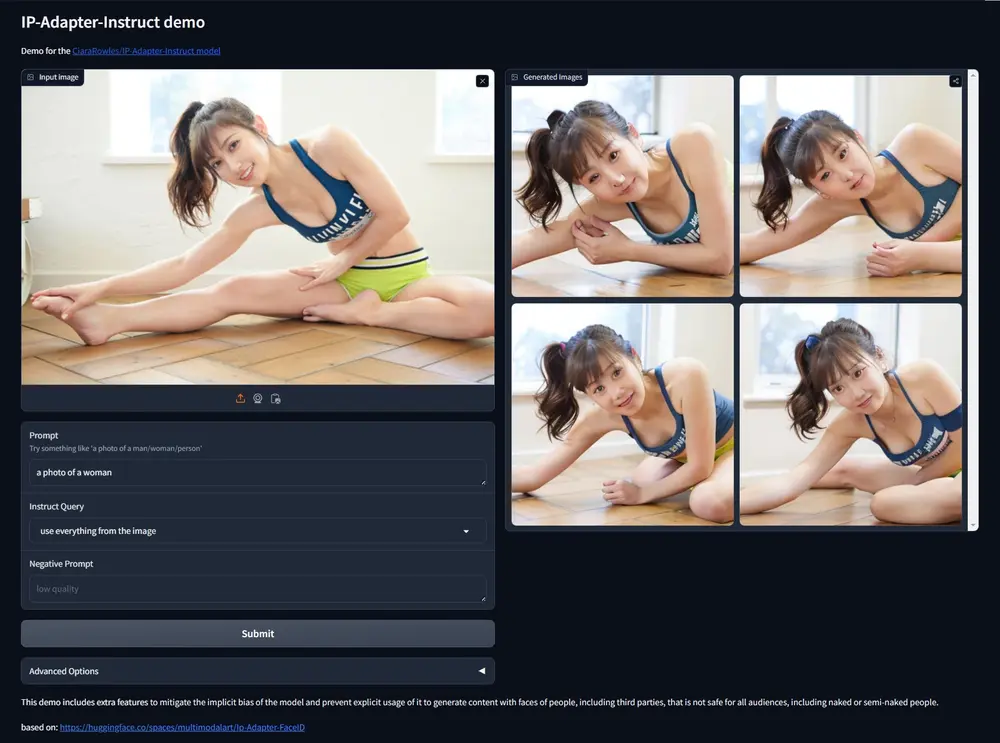
IPAdapter-Instruct:在处理基于图像的条件化时,能够更精确地理解用户的意图Unity推出IPAdapter-Instruct,它是一种用于图像生成的新技术,特别是在处理基于图像的条件化时,能够更精确地理解用户的意图。简单来说,这个模型可以让用户通过添加指令性提示(Instr...新技术# IPAdapter-Instruct2年前06510
新型框架Uni3C:通过3D增强技术实现对视频生成中相机和人体运动的精确控制阿里达摩院、复旦大学和湖畔实验室的研究人员推出新型框架Uni3C,旨在通过3D增强技术实现对视频生成中相机和人体运动的精确控制。Uni3C通过将相机控制和人体运动控制统一到一个框架中,解决了现有方法中...新技术# Uni3C# 人体运动# 视频生成12个月前06500
扩散模型中“幻觉”(hallucinations)现象:生成了一些在训练数据中从未出现过的样本卡内基梅隆大学和DatalogyAI的研究人员发布论文探讨扩散模型(diffusion models)中“幻觉”(hallucinations)现象,即模型生成了一些在训练数据中从未出现过的样本。这种...新技术# 幻觉# 扩散模型2年前06500
阿里发布 Wan2.2-I2V-Flash:更快、更稳、更可控的图生视频模型阿里通义大模型团队宣布,Wan2.2-I2V-Flash 正式上线。这款轻量级图生视频(Image-to-Video)模型,在保持高画质与强控制力的同时,实现了生成速度与性价比的显著跃升。 它不是对前...早报# Wan2.2-I2V-Flash8个月前06480