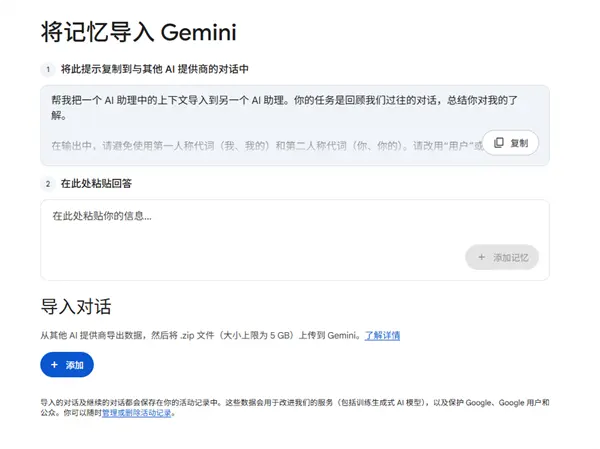
阿里通义大模型团队宣布,Wan2.2-I2V-Flash 正式上线。这款轻量级图生视频(Image-to-Video)模型,在保持高画质与强控制力的同时,实现了生成速度与性价比的显著跃升。

它不是对前代的简单优化,而是一次面向实用化落地的重构:让高质量视频生成从“能用”走向“好用”。
目前,该模型已接入阿里云百炼平台,开发者可通过 API 调用快速集成。
核心升级:快12倍,贵不到1毛钱每秒
在实际应用中,视频生成模型不仅要看质量,更要算“效率账”。Wan2.2-I2V-Flash 在关键指标上实现全面突破:
| 指标 | 提升表现 |
|---|---|
| 推理速度 | 相比 Wan2.1 提升 12 倍 |
| 调用成本 | 仅 0.1 元 / 秒(生成时长计费) |
| 抽卡成功率 | 相比 Wan2.1 提升 123%(指符合提示词预期的结果比例) |
这意味着:
- 过去需要几分钟生成的片段,现在几秒内完成;
- 更低的试错成本,适合批量生成与交互式创作;
- 更高的输出一致性,减少无效生成。
能力亮点:不只是快,更要“听懂指令”
Wan2.2-I2V-Flash 的价值不仅在于速度,更在于其对用户意图的理解与执行能力。
✅ 指令遵循能力大幅提升
支持直接输入各类特效提示词,无需复杂工程技巧,即可实现:
- “镜头缓缓推进,聚焦人物眼神”
- “慢动作回旋,背景虚化”
- “阳光从左侧斜射,人物轮廓泛金边”
这些描述能被模型准确解析,并转化为对应的运镜与光影变化。
✅ 精准控制运镜与节奏
内置对多种摄像语言的理解能力,可实现:
- 推拉摇移跟升降(经典七种运镜方式)
- 快慢动作调节
- 转场衔接逻辑
让生成视频更具叙事感和专业感。
✅ 风格稳定,动态自然
无论输入的是插画、水墨、赛博朋克还是写实风格图像,模型都能:
- 保持原始艺术风格一致性
- 添加合理且流畅的动作细节(如发丝飘动、衣角摆动)
- 避免常见失真问题(如肢体扭曲、画面抖动)
适用于 IP 动画化、广告创意、短视频制作等场景。
技术背景:站在 Wan2.2 的肩膀上
Wan2.2-I2V-Flash 并非孤立存在,而是建立在通义万相 Wan2.2 系列的强大基础之上。
就在不久前的 7 月 28 日,阿里开源了完整的 Wan2.2 模型家族,包含:
| 模型 | 类型 | 架构特点 |
|---|---|---|
| Wan2.2-T2V-A14B | 文生视频 | MoE 架构,总参数 27B,激活 14B |
| Wan2.2-I2V-A14B | 图生视频 | 同上,业界首个 MoE 视频生成模型 |
| Wan2.2-IT2V-5B | 统一视频生成 | 支持图文混合输入 |
这三款模型均采用 MoE(Mixture of Experts)架构,在保证性能的同时控制计算开销。
更重要的是,它们引入了 电影美学控制系统,在以下维度达到专业级水准:
- 光影层次
- 色彩情绪
- 构图美学
- 微表情细节
真正实现了“AI 生成,电影质感”。
而 Wan2.2-I2V-Flash,则是这一技术体系下的轻量推理版本,专为高频、低延迟场景优化。
如何体验?
目前,Wan2.2-I2V-Flash 已上线 阿里云百炼平台,支持:
- API 调用(JSON 输入输出)
- 批量任务提交
- 多分辨率输出(如 9:16、16:9)
- 自定义提示词控制
开发者可直接集成到内容生产系统中,构建自动化视频流水线。
🔗 体验入口:阿里云百炼 - 通义万相
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











