新型4D内容生成管道4Diffusion:创造全新的视角和动态场景,而不仅仅是对现有视频进行剪辑和调整北京航空航天大学、上海人工智能实验室和香港大学的研究人员推出新型4D内容生成管道4Diffusion,它能够从单目视频生成具有空间-时间一致性的四维内容。简单来说,4Diffusion就像一个高级的视...新技术# 4Diffusion# 4D模型2年前07570
图像编辑技术Paint by Inpaint:根据文本指令在图像中添加对象,而无需用户提供输入遮罩来自魏茨曼科学研究所和以色列理工学院的研究人员推出一种新颖的图像编辑技术Paint by Inpaint,它能够根据文本指令在图像中添加对象,而无需用户提供输入遮罩(mask)。这项技术的核心在于利用...新技术# Paint by Inpaint# 图像编辑2年前07570
单前向视频生成模型SF-V:通过一次前向传播快速生成高质量、运动连贯的视频Snap和罗格斯大学的研究人员推出新型单步视频生成模型SF-V,此模型的核心特点是能够通过一次前向传播(single forward pass)快速生成高质量、运动连贯的视频,这对于需要实时视频合成和...新技术# SF-V# 单前向视频生成模型2年前07540
新型框架Isotropic3D:根据单张参考图片的CLIP嵌入生成多视角一致且高质量的3D模型来自复旦、清华、同济的研究人员推出新型框架Isotropic3D,它能够根据单张参考图片的CLIP嵌入(embedding)生成多视角一致且高质量的3D内容。CLIP嵌入是一种能够捕捉图像语义信息的技...新技术# 3D模型# Isotropic3D2年前07530
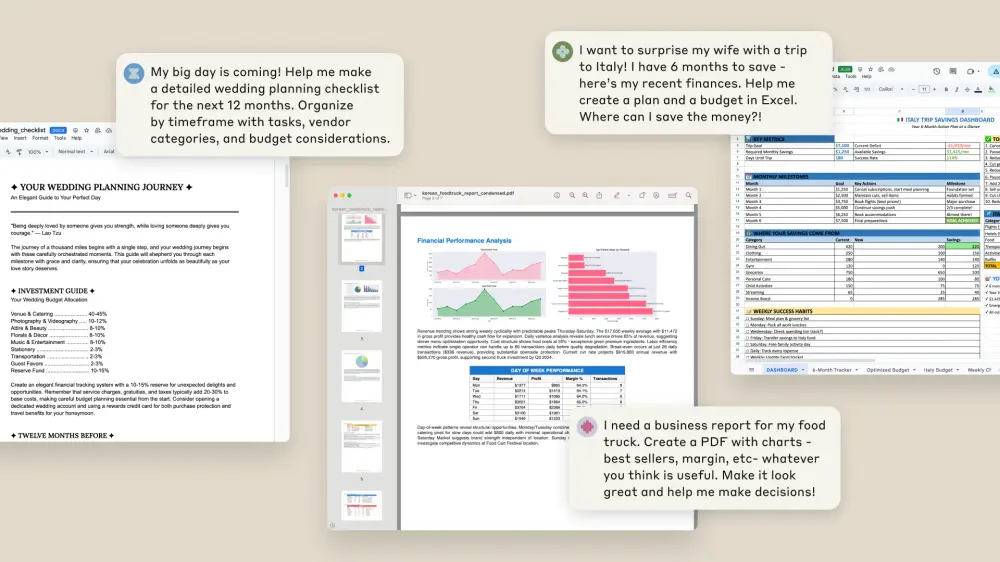
Claude 现可直接生成和编辑文件:Excel、PPT、PDF 全支持Anthropic 正式推出 Claude 文件创建与编辑功能,标志着其从“对话助手”向“生产力协作者”的关键跃迁。 现在,你不再需要让 Claude 只输出文本建议,而是可以直接对它说: “根据这份...早报# Claude7个月前07500
英伟达推出视频生成模型CMD:解决现有视频生成技术在处理高维视频数据时所面临的高内存和计算需求问题英伟达推出新型的视频生成模型内容-运动潜在扩散模型(Content-Motion Latent Diffusion Model,简称CMD),这个模型是为了解决现有视频生成技术在处理高维视频数据时所面...新技术# CMD# 英伟达2年前07500
通用且即插即用的加速方案AsyncDiff:加速SD模型的运行速度新加坡国立大学推出通用且即插即用的加速方案AsyncDiff,它能够显著加速扩散模型(diffusion models)的运行速度。扩散模型是一种强大的生成模型,能够创造出各种数据,比如图片和视频,但...新技术# AsyncDiff# SD模型2年前07490
建立在多模态大语言模型基础上的统一文本到图像生成和检索框架TIGeR来自新加坡国立大学 NExT++ 实验室、南洋理工大学、香港理工大学和哈尔滨工业大学(深圳)的研究人员推出一个统一的文本到图像生成和检索框架TIGeR,这个框架建立在多模态大语言模型(MLLMs)的基...新技术# TIGeR# 文生图2年前07480
MegaFusion:将现有的扩散模型扩展到更高分辨率的图像生成,而无需额外的调整或适应上海交通大学、上海人工智能实验室和大连理工大学的研究人员推出MegaFusion,它能够将现有的扩散模型(diffusion models)扩展到更高分辨率的图像生成,而无需额外的调整或适应。具体而言...新技术# MegaFusion2年前07460
OpenAI公开AI视频生成模型Sora:可创建长达 60 秒的视频OpenAI公开了AI视频生成(文生视频)模型Sora,它可以创建长达 60 秒的视频,其中包含高度详细的场景、复杂的摄像机运动和具有生动情感的多个角色。 官方介绍 以下是官方介绍全文翻译: 我们正在...新技术# AI视频生成模型# OpenAI# Sora2年前07460
DreamReward:通过人类偏好反馈来提升从文本到3D内容生成的质量生数科技发布创新框架DreamReward,它专注于通过人类偏好反馈来提升从文本到3D内容生成(text-to-3D generation)的质量。它通过结合人类反馈和先进的机器学习技术,极大地提高了...新技术# 3D模型# DreamReward2年前07450
基于图像条件的扩散模型Semantica:根据给定的条件图像(即输入图像)的语义信息生成新的图像Google Deepmind推出新型图像生成模型Semantica,Semantica的核心特点是它能够在不需要对特定数据集进行微调(finetuning)的情况下,适应不同的图像数据集。这是通过一...新技术# Google DeepMind# Semantica2年前07440