
北京航空航天大学、上海人工智能实验室和香港大学的研究人员推出新型4D内容生成管道4Diffusion,它能够从单目视频生成具有空间-时间一致性的四维内容。简单来说,4Diffusion就像一个高级的视频编辑器,但不同于传统编辑器的是,它能够创造全新的视角和动态场景,而不仅仅是对现有视频进行剪辑和调整。尽管4Diffusion在生成4D内容方面取得了显著的成果,但仍存在一些限制,比如对基础模型的依赖和高质量训练数据集的规模限制。未来的改进可能包括扩大数据集规模和改进基础模型,以进一步提升生成内容的质量和多样性。
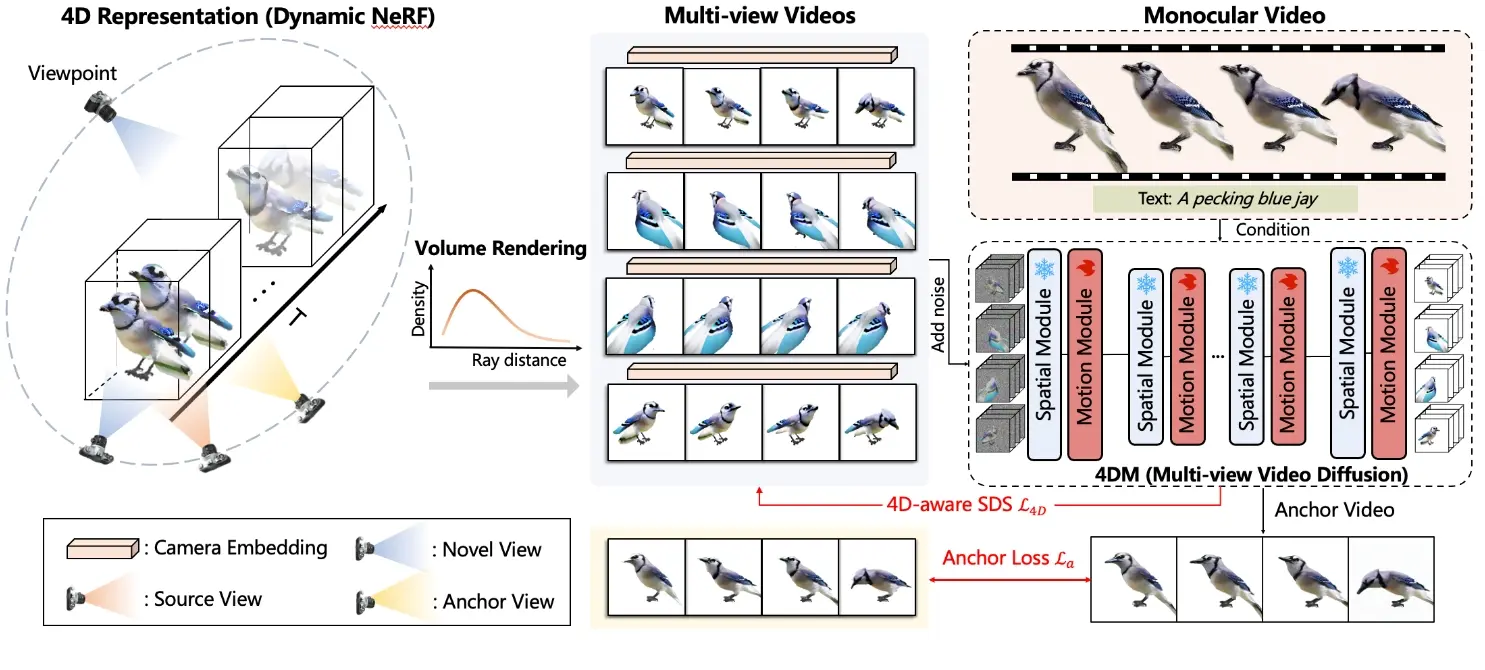
开发人员首先设计了一个适用于多视角视频生成的统一扩散模型,通过将学习的运动模块融入一个冻结的3D-aware diffusion模型来捕捉多视角空间时间相关性。在训练了一个精选数据集之后,扩散模型获得了合理的时间一致性,并保持了3D-aware diffusion模型的普遍可及性和空间一致性。随后,开发人员提出了基于多视角视频扩散模型的4D-aware Score蒸馏采样损失,以优化由动态NeRF参数化的4D表示。这旨在消除由多个扩散模型引起的差异,允许生成具有空间时间一致性的4D内容。此外,开发人员制定了一个锚定损失,以增强外观细节并促进动态NeRF的学习。

主要功能和特点:
- 多视角视频生成:4Diffusion可以生成从多个不同视角观察的一致性视频内容。
- 空间-时间一致性:生成的4D内容在动态变化中保持了时间和空间上的连贯性,避免了画面闪烁或不一致的现象。
- 基于扩散模型:它采用了先进的扩散生成模型,这类模型在图像、视频和3D内容生成方面取得了显著的成效。
- 动态NeRF优化:通过一种特别的损失函数,优化了动态NeRF(一种用于3D场景表示的技术),以提高生成内容的细节和质量。
- 锚点损失:引入锚点损失来增强外观细节,帮助动态NeRF更好地学习输入视频的特征。
工作原理:
4Diffusion的工作原理可以分为以下几个步骤:
- 多视角视频扩散模型(4DM):首先,设计一个统一的扩散模型,通过将可学习的动态模块整合到一个冻结的3D感知扩散模型中,以捕获多视角下的空间-时间关联。
- 训练与优化:在精选的数据集上训练4DM,使其获得合理的时间一致性,并保留3D感知扩散模型的泛化能力和空间一致性。
- 4D感知得分蒸馏采样(4D-aware SDS):提出基于多视角视频扩散模型的损失函数,优化由动态NeRF参数化的4D表示,以消除由多个扩散模型引起的差异,实现空间-时间一致性的4D内容生成。
- 锚点损失:利用4DM生成锚定视频,并设计锚点损失来增强外观细节,促进动态NeRF的学习。
具体应用场景:
- 虚拟现实和增强现实:在虚拟角色、游戏、媒体制作和AR/VR应用中,4Diffusion可以用于创造动态的3D场景和对象。
- 动画制作:动画师可以使用4Diffusion从单目视频生成多视角动画,大大减少传统动画制作的工作量。
- 3D内容创建:艺术家和设计师可以利用4Diffusion从简单的视频创建复杂的3D模型和场景,加速创作过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











