谷歌推出新型图像编辑工具Magic Insert:将一张图片中的主题(比如一个人或者一个物体)拖拽到另一张风格完全不同的图片上,并且让这个主题在新图片中看起来非常自然谷歌推出新型图像编辑工具Magic Insert,可以让我们像变魔术一样,将一张图片中的主题(比如一个人或者一个物体)拖拽到另一张风格完全不同的图片上,并且让这个主题在新图片中看起来非常自然,就像它本...新技术# Magic Insert# 图像编辑# 谷歌2年前07430
一致性模型的强化学习RLCM:提升图像生成的速度和质量来自康奈尔大学的研究团队推出RLCM(Reinforcement Learning for Consistency Models, 一致性模型的强化学习),RLCM提供了一种有效的方法来提升图像生成的...新技术# RLCM# 一致性模型2年前07430
腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT:能够根据上下文与用户进行多轮多模态对话,生成并优化图像腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT,它特别擅长理解中文和英文的文本提示,并据此生成图像,Hunyuan-DiT能够根据上下文与用户进行多轮多模态对话,生成并优化图像...新技术# Hunyuan-DiT# 提示词# 文生图模型2年前07420
Garment3DGen:根据真实世界的图像或通过文本描述生成的图像来创建3D服装模型Meta推出Garment3DGen,它是一种自动化的方法,能够将基础的服装网格模型转换成可以直接用于模拟的资产,无论是通过图像还是文本提示。这个方法使得快速生成资产变得简单快捷,大大降低了原本需要专...新技术# 3D服装模型# Garment3DGen2年前07420
全新文生图框架RealCompo:结合SD1.5模型与GLIGEN模型的优势来提高生成图像的质量RealCompo是一个全新的文生图框架,它旨在解决当前文生图模型在处理多对象组合生成时遇到的困难,通过动态平衡真实性和组合性来提高生成图像的质量。 GitHub 论文 RealCompo利用了文本到...新技术# GLIGEN模型# RealCompo# 文生图框架2年前07420
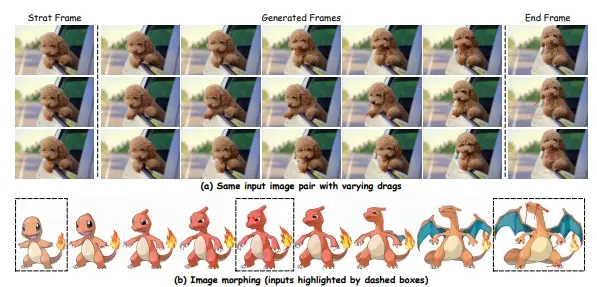
交互式帧插值工具Framer:根据用户的创造力生成两个图像之间平滑过渡的帧帧插值是生成两个图像之间平滑过渡帧的技术,广泛应用于视频处理、动画制作和内容创作等领域。传统的帧插值方法通常依赖于固定的算法,难以实现对局部运动的精细控制。浙江大学和蚂蚁集团的研究人员提出了Frame...新技术# Framer# 帧插值1年前07410
【AI周报】openAI取消GPT 4使用时3 小时 40条的限制1、openAI取消GPT 4使用时3 小时 40条的限制 GPT 4取消了3 小时 40条的限制,可以无限量使用,这是因为竞争加剧还是因为GPT 5要来了呢? 2、OpenAI首推语音引擎 用15秒...早报# DBRX# Jamba# OpenAI2年前07410
去噪方法GeneOH Diffusion:解决手-物体交互(HOI)去噪的问题来自清华大学、上海人工智能实验室、上海启智研究院的研究人员推出GeneOH Diffusion,它旨在解决手-物体交互(HOI)去噪的问题。在手-物体交互中,我们经常需要准确地追踪手部动作,尤其是在游...新技术# GeneOH Diffusion2年前07400
谷歌推出CamViG:控制视频生成过程中的相机视角,从而生成具有精确相机运动的视频Google Research推出CamViG(Camera Aware Image-to-Video Generation),它能够根据单一图像和三维相机运动信号生成视频。这项技术的核心在于,它能够...新技术# CamViG# 相机运动# 谷歌2年前07390
LayerDiffusion:可生成高质量的透明图像和图层Controlnet、Fooocus、Stable Diffusion WebUI Forge的开发者lllyasviel推出新的项目LayerDiffusion,它允许大规模预训练的潜在扩散模型(如...新技术# LayerDiffusion# 图层# 透明图像2年前07390
阿里推出AI视频生成模型I2VGen-XL阿里旗下达摩院推出AI视频生成模型I2VGen-XL,可以根据用户输入的静态图像和文本生成目标接近、语义相同的视频,生成的视频具高清 (1280 * 720)、宽屏 (16:9)、时序连贯、质感好等特...新技术# AI视频# I2VGen-XL# 阿里2年前07330
文生视频新技术T2V-Turbo:快速生成高质量的视频,并且能够根据文本描述来创建视频内容来自加州大学圣巴巴拉分校、谷歌和滑铁卢大学的研究人员推出文生视频新技术T2V-Turbo,它可以快速生成高质量的视频,并且能够根据文本描述来创建视频内容。它将来自混合的不同可微奖励模型的反馈整合到预训...新技术# T2V-Turbo# 文生视频2年前07320