英伟达推出Autoguidance:改进图像生成扩散模型的性能英伟达和阿尔托大学的研究人员推出Autoguidance,改进图像生成扩散模型的性能,特别是通过一种新颖的方法来控制图像质量、结果的变化性以及与给定条件(如类别标签或文本提示)的一致性。扩散模型是一种...新技术# Autoguidance# 英伟达2年前08570
Python安装教程在《必备软件》已经跟大家说了,目前多数AI应用都是使用Python编写,Python版本众多,大家要根据所安装程序所需版本来进行安装。 Python官网:https://www.python.org...教程# Python# 安装教程2年前08560
新型文生图模型的微调算法SPIN-DiffusionSPIN-Diffusion是一种新型文生图模型的微调算法。这个算法特别适用于那些只有单个图像与文本提示(prompt)相关联的数据集,它通过一种自我博弈(self-play)的机制,让模型不断地与自...新技术# SPIN-Diffusion# 文生图模型2年前08540
文生图风格化工具Artist:无需训练即可实现美学控制的文本驱动风格化香港理工大学的研究人员推出一种无需训练即可实现美学控制的文本驱动风格化方法Artist。简而言之,Artist能够根据文本描述,将一张静态图片转换成具有特定艺术风格的图像,同时保持图片内容的完整性和细...新技术# Artist# 风格化2年前08530
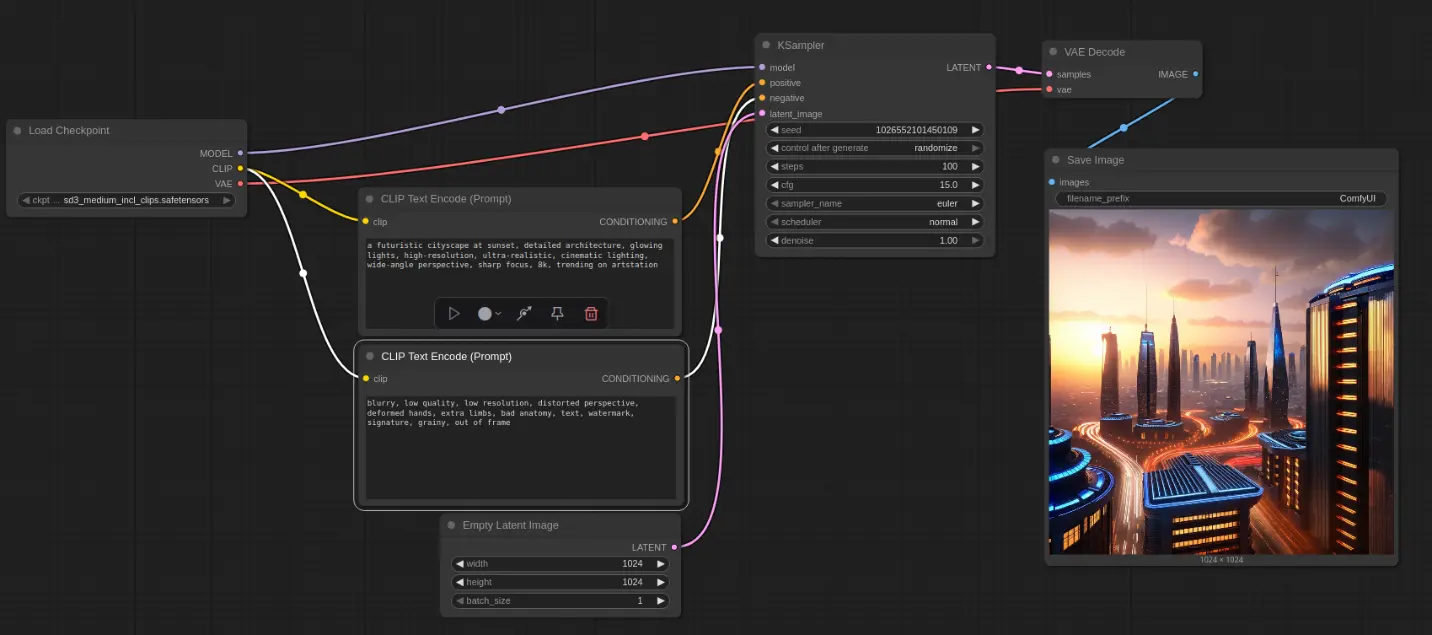
在 Windows 上使用 WSL 和 ROCm 运行 ComfyUI:AMD 显卡用户指南如果你使用的是 AMD Radeon™ 显卡,现在也可以在 Windows 上高效运行基于 PyTorch 的 AI 工作流,例如 ComfyUI。通过 Windows Subsystem for L...教程# AMD 显卡# ComfyUI# ROCm8个月前08480
视频编辑框架AnyV2V:根据文本提示、主题或风格等不同的输入来编辑视频来自滑铁卢大学、Vector研究所和Harmony.AI的研究团队推出新型视频编辑框架AnyV2V,它能够让用户根据文本提示、主题或风格等不同的输入来编辑视频。 项目主页 GitHub Demo 想象...新技术# AnyV2V# 视频编辑2年前08460
无需训练、基于轨迹的可控图像生成技术TraDiffusion:允许用户通过鼠标轨迹来轻松引导图像的生成,而无需进行额外的训练或微调厦门大学和中国科学院大学深圳先进技术研究院的研究人员推出新型图像生成技术TraDiffusion,这项技术的核心在于它允许用户通过鼠标轨迹来轻松引导图像的生成,而无需进行额外的训练或微调。简单来说,就...新技术# TraDiffusion# 图像生成2年前08450
新型自编码器LiteVAE:用于提高图像生成模型中的效率和性能来自苏黎世联邦理工学院和迪士尼研究工作室的研究人员推出新型自编码器LiteVAE,它被设计用于提高图像生成模型中的效率和性能。自编码器是一类神经网络,它们通过学习数据的压缩表示来重构数据。在图像处理中...新技术# LiteVAE# 自编码器2年前08440
新型视频深度估计方法DepthCrafter:为开放世界(即不受限制、多样化的现实世界场景)的视频生成时间上连贯、细节丰富的深度序列腾讯人工智能实验室、香港科技大学和腾讯 PCG ARC 实验室的研究人员推出新型视频深度估计方法DepthCrafter,能够为开放世界(即不受限制、多样化的现实世界场景)的视频生成时间上连贯、细节丰...新技术# DepthCrafter# 视频深度估计2年前08410
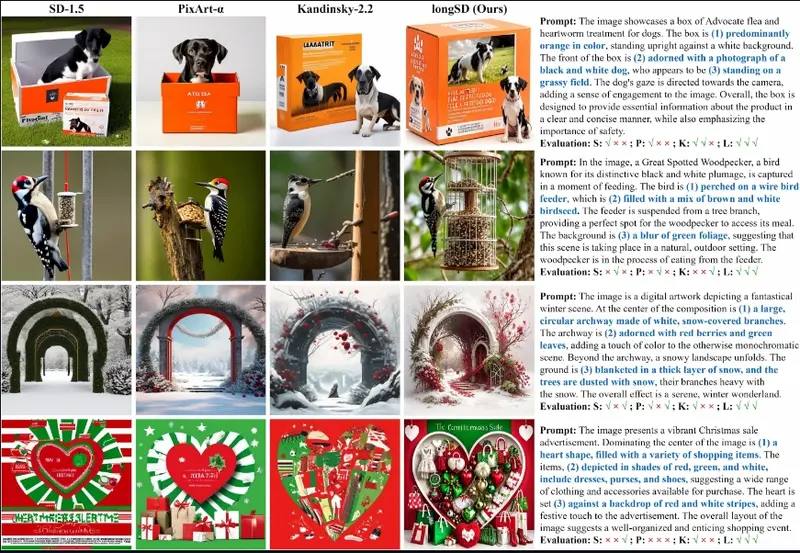
LongAlign:改进文生图模型的长文本对齐文生图模型的快速发展使它们能够从给定的文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法如 CLIP 面临限制,并且将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,香港大学、新加...新技术# LongAlign# 文生图模型# 长文本对齐1年前08360
多模态大语言模型LITA:专门设计来处理视频中的时间定位问题英伟达推出多模态大语言模型LITA(Language Instructed Temporal-Localization Assistant),它专门设计来处理视频中的时间定位问题。 GitHub 论文...新技术# LITA# 多模态大语言模型2年前08360
新型图像生成蒸馏模型LinFusion:利用文本提示生成高分辨率的图像新加坡国立大学学习与视觉实验室的研究人员推出新型图像生成模型LinFusion,它能够利用文本提示生成高分辨率的图像。LinFusion的核心在于它采用了一种新颖的线性注意力机制,这使得它在处理大量像...新技术# LinFusion# 蒸馏模型2年前08340