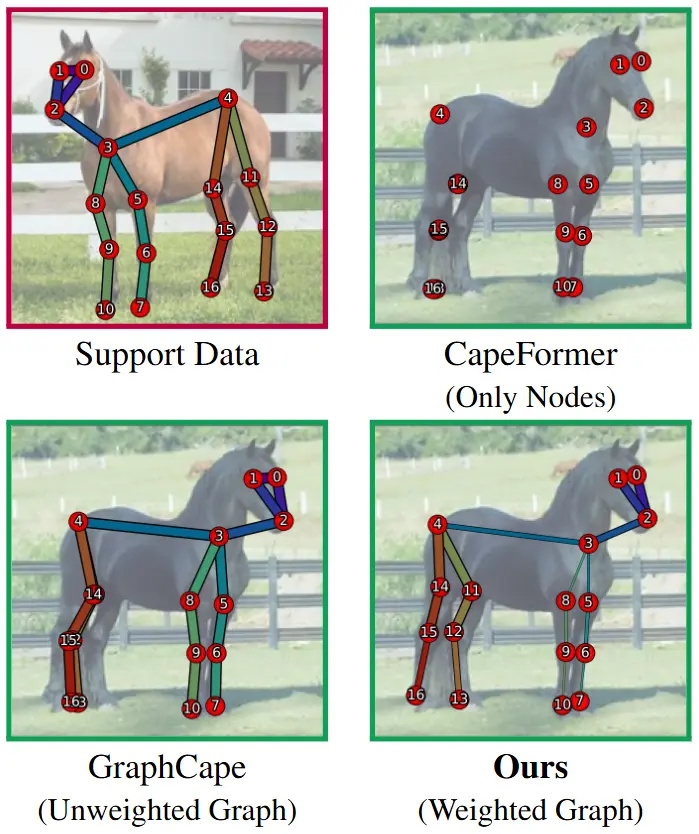
用于类别无关的姿态估计新型框架EdgeCape特拉维夫大学的研究人员推出新型框架EdgeCape,它用于类别无关的姿态估计(Category-Agnostic Pose Estimation, CAPE)。EdgeCape能够通过单一模型在多样化...新技术# EdgeCape# 姿态估计1年前03390
FIND3D模型:在开放世界环境中对3D对象的任何部分进行语义分割加州理工学院的研究人员推出FIND3D模型,它能够在开放世界环境中对3D对象的任何部分进行语义分割。这意味着FIND3D可以基于任何文本查询,对任何对象的任何部分进行分割。这项技术在机器人技术、虚拟现...新技术# FIND3D# 语义分割1年前02920
新型框架SplatFlow:用于3D高斯绘制(3DGS)的合成和编辑Twelvelabs和韩国科学技术研究院的研究人员推出新型框架SplatFlow,它用于3D高斯绘制(3D Gaussian Splatting,简称3DGS)的合成和编辑。SplatFlow通过结合...新技术# 3DGS# SplatFlow1年前02770
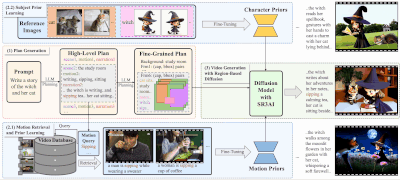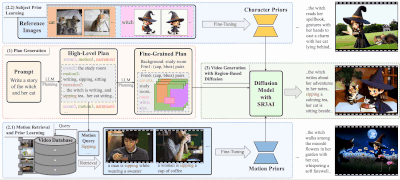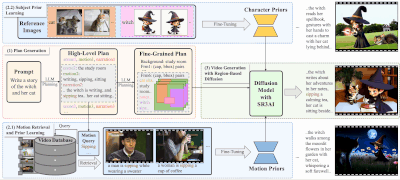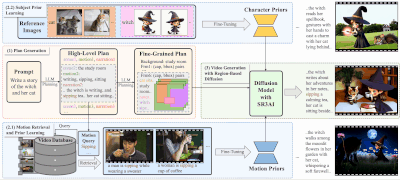
新型故事视频生成框架DreamRunner:根据文本脚本生成长篇、多动作、多场景的视频,适用于CogVideoX模型故事讲述视频生成(SVG)是一项旨在从文本脚本创建长时间、多动作、多场景视频的任务。这种技术在媒体和娱乐领域的内容创作中具有巨大潜力,但同时也面临着诸多挑战,包括但不限于: 物体需要展示一系列精细、复...新技术# DreamRunner# 视频生成1年前03180
适用于FLUX模型!新型零样本主题驱动图像生成方法Diptych Prompting主题驱动的文本到图像生成旨在通过准确捕捉主体的视觉特征和文本提示的语义内容,在期望的上下文中生成新主体的图像。传统方法依赖于耗时耗资源的微调以实现主题对齐,而最近的零样本方法则依赖于即时的图像提示,通...新技术# Diptych Prompting# FLUX模型1年前03470
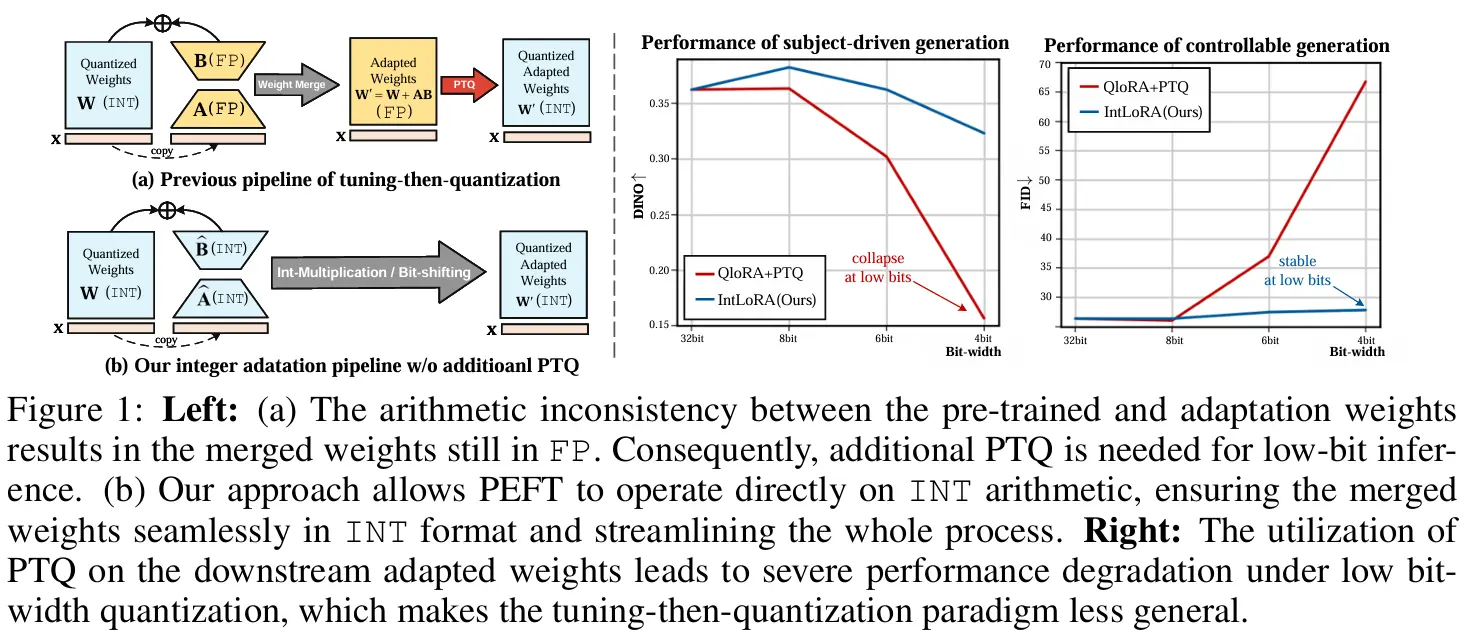
整数低秩参数微调量化扩散模型IntLoRA:提升了文生图模型微调的效率近年来,文生图模型在各种下游任务中取得了显著的成果。然而,微调这些大型模型所需的计算资源非常庞大,限制了其在个性化定制和实际应用中的普及。为了解决这一问题,研究人员开始探索参数高效微调(PEFT)技术...新技术# IntLoRA1年前03030
DiffusionGS:单阶段3D扩散模型,实现单视图物体和场景生成现有的前馈图像到3D的方法主要依赖于2D多视图扩散模型,这些模型在生成3D内容时存在一些显著的局限性。首先,它们无法保证3D一致性,导致在改变提示视图方向时容易崩溃。其次,这些方法主要处理以物体为中心...新技术# 3D模型# DiffusionGS1年前03750
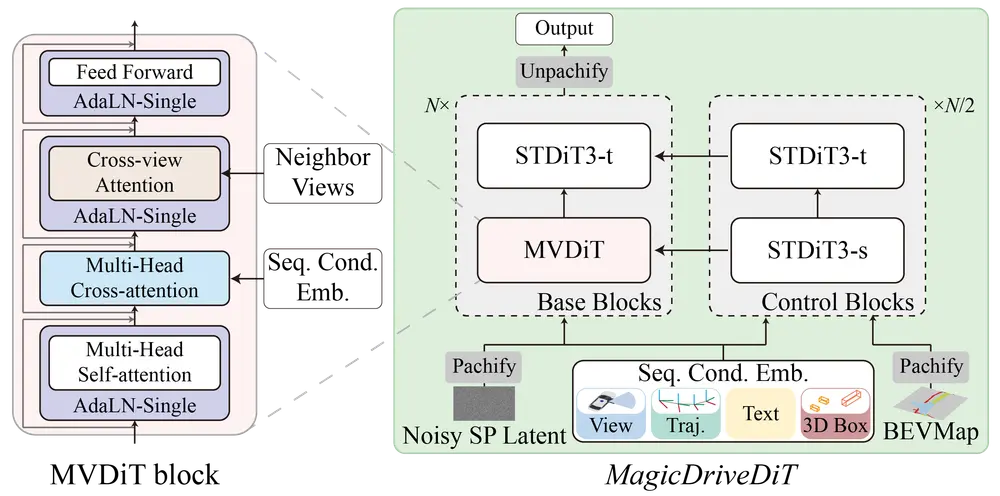
MagicDriveDiT:提高视频合成的效率和可控性,以更好地服务于自动驾驶应用随着扩散模型的迅速发展,视频合成技术尤其是可控视频生成领域取得了重大突破,这对自动驾驶等应用具有重要意义。然而,现有的视频生成方法在处理高分辨率和长视频时面临可扩展性和控制条件整合的挑战,限制了它们在...新技术# MagicDriveDiT# 自动驾驶1年前03530
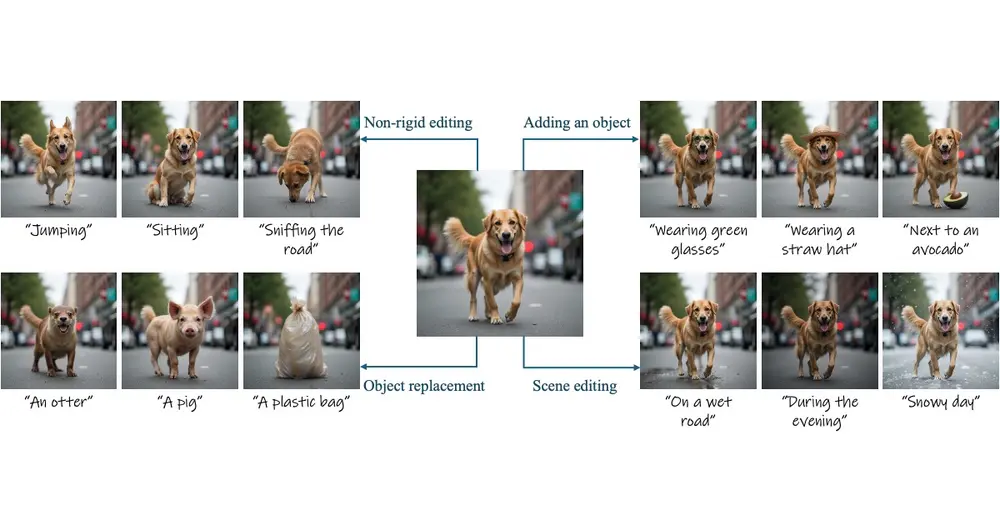
无需训练的图像编辑技术Stable Flow:执行各种类型的图像编辑操作,包括非刚性编辑、物体添加、物体替换和全局场景编辑Snap Research、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出图像编辑方法Stable Flow,这是一种无需训练的图像编辑技术,能够执行各种类型的图像编辑操作,包括非刚性编辑...新技术# Stable Flow# 图像编辑1年前03950
基础世界模型The Matrix:用于生成无限长度和实时的视频在追求高质量、实时视频生成的过程中,研究人员和开发者们面临着一系列挑战。传统的视频生成模型往往因高昂的计算成本、有限的视频时长以及缺乏实时交互性而受到限制。特别是在需要长时间、高分辨率视频生成的应用场...新技术# The Matrix# 世界模型1年前03450
Reducio-DiT:通过先进压缩技术提升视频生成效率随着技术的进步,视频生成模型已经能够创造出令人惊叹的高质量视频片段。然而,这些模型在实际应用中面临着一些显著的障碍,主要集中在计算资源的需求上。目前市场上的领先模型,例如Sora、Runway Gen...新技术# Reducio-DiT# Reducio-VAE1年前03460
开源版风格参考StyleCodes:能够将图像风格表达为一个 20 符号的 base64 代码扩散模型在图像生成方面取得了显著的成功,但如何有效地控制生成图像的风格仍然是一个挑战。虽然使用示例图像可以实现风格控制,但这种方法存在一些不便:示例图像体积较大,不易于分享,且可能涉及隐私问题。为此...新技术# Midjourney# StyleCodes# 风格参考1年前04410