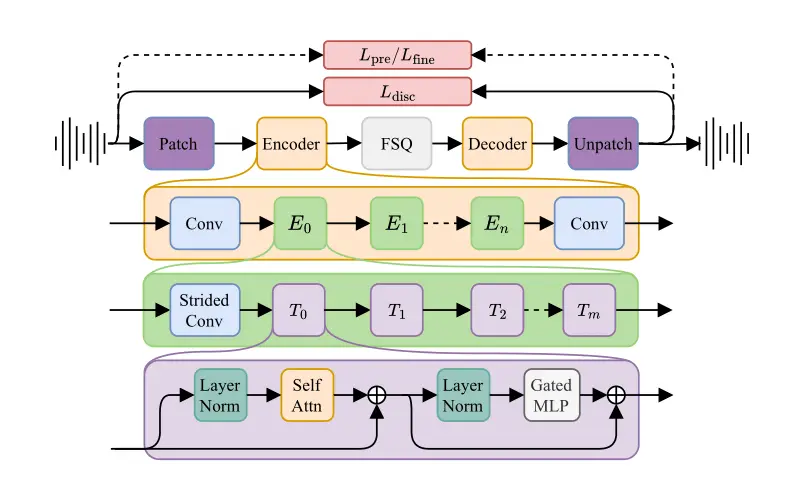
端到端的高质量ID一致性人类跳舞视频生成新框架StableAnimator近年来,人像动画生成模型在图像和视频领域取得了显著进展,但它们在身份一致性(ID一致性)方面仍然面临挑战。传统的扩散模型虽然能够生成高质量的视频,但在长时间序列中保持人物的身份特征(如面部表情、发型等...新技术# StableAnimator# 视频生成框架1年前03010
Stability AI 推出一种基于大规模 Transformer 架构的新型音频编码模型TAAE在语音处理领域,标记化(tokenization)是生成或理解语音的关键步骤。传统的语音编码模型通常依赖于低参数量的架构,使用具有强归纳偏置的组件,如卷积神经网络(CNN)和循环神经网络(RNN)。然...新技术# Stability AI# TAAE1年前03000
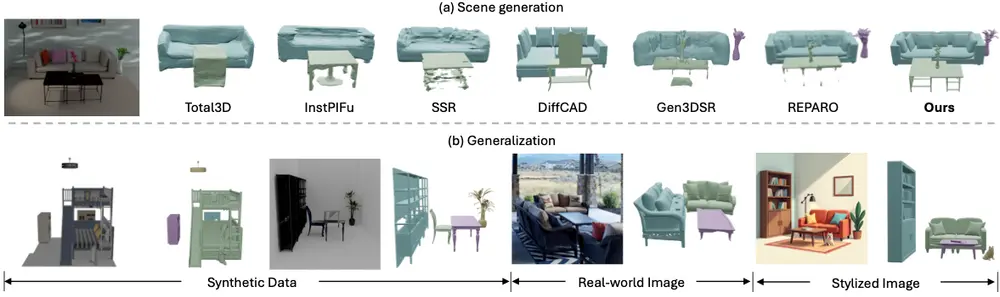
从单张图片生成3D场景的新型框架MIDI北京航空航天大学、VAST、清华大学和香港大学的研究人员推出新型框架MIDI(Multi-Instance Diffusion),它用于从单张图片生成3D场景。这项技术的核心在于将预训练的图像到3D对...新技术# 3D场景# MIDI1年前03000
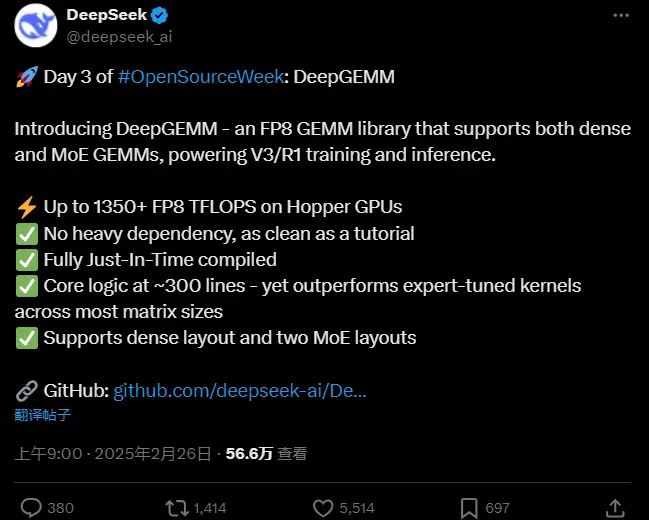
深度求索开源第三弹DeepGEMM:专为高效 FP8 矩阵乘法设计的库在开源周的第三天,DeepSeek 推出了一个名为 DeepGEMM 的新库,专为高效、简洁的 FP8 通用矩阵乘法(GEMM)而设计。这一工具旨在解决现代 AI 计算中矩阵乘法的效率和精度问题,特别...新技术# DeepGEMM# DeepSeek# 深度求索1年前02990
新型多视图生成新视角合成(NVS)模型NVComposer香港中文大学、腾讯PCG ARC实验室和北京大学的研究人员推出新型多视图生成新视角合成(NVS)模型NVComposer,它能够从少量未对准的稀疏图像中生成新视角的视图,而无需依赖外部的多视图对齐过程...新技术# NVComposer1年前02990
可控人类图像生成的新框架BootComp:特别适用于包含多个参考服装的情况韩国科学技术研究院和OMNIOUS.AI的研究人员提出了BootComp——一种用于可控人类图像生成的新框架,特别适用于包含多个参考服装的情况。这一创新解决了训练数据获取的主要瓶颈,即为每个人类主体收...新技术# BootComp1年前02990
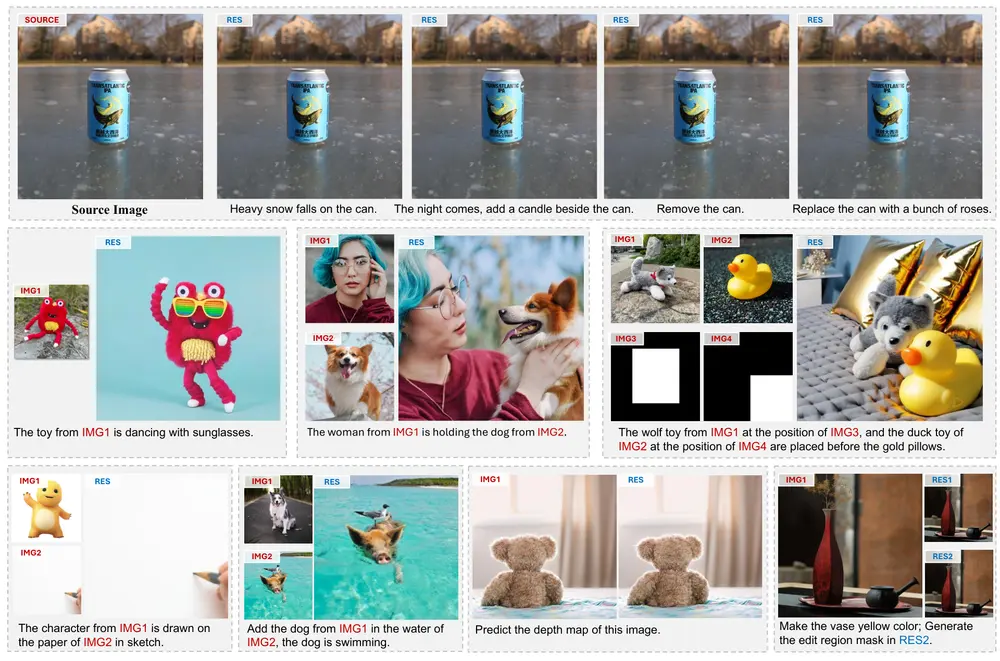
解决图像生成与编辑任务的统一框架UniReal图像生成和编辑任务在计算机视觉领域中具有广泛的应用,如图像合成、风格迁移、图像修复等。然而,现有的解决方案通常针对特定任务设计,缺乏一个统一的框架来处理多种图像级任务。香港大学和Adobe Resea...新技术# UniReal# 图像生成# 图像编辑1年前02980
FIND3D模型:在开放世界环境中对3D对象的任何部分进行语义分割加州理工学院的研究人员推出FIND3D模型,它能够在开放世界环境中对3D对象的任何部分进行语义分割。这意味着FIND3D可以基于任何文本查询,对任何对象的任何部分进行分割。这项技术在机器人技术、虚拟现...新技术# FIND3D# 语义分割1年前02980
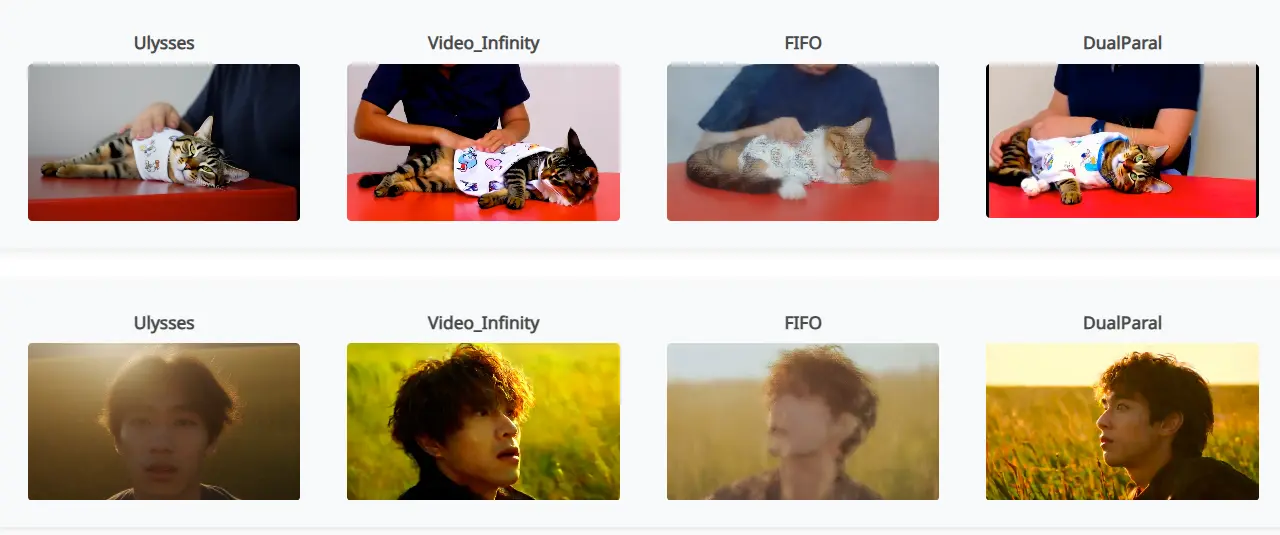
基于Wan2.1模型的分布式推理策略 DualParal:用于高效生成极端长视频新加坡国立大学、西安电子科技大学和华中科技大学的研究人员推出分布式推理策略 DualParal,用于高效生成极端长视频。该策略针对基于DiT架构模型(Wan2.1mox ),这些模型在生成高质量视频方...新技术# DualParal# Wan2.1模型# 分布式推理策略10个月前02970
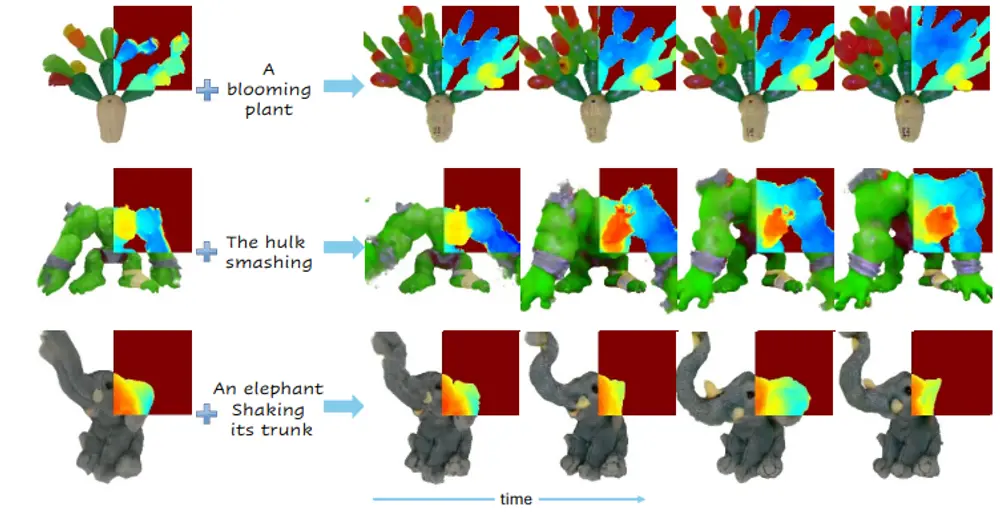
Bringing Objects to Life:将静态的3D对象转换成4D动画(即动态的3D对象),这个过程是通过文本提示来控制的巴伊兰大学和英伟达的研究人员推出一种名为3to4D的方法,它能够将静态的3D对象转换成4D动画(即动态的3D对象),这个过程是通过文本提示来控制的。这种方法允许用户为提供的3D模型添加动态行为,模拟对...新技术# 3to4D1年前02970
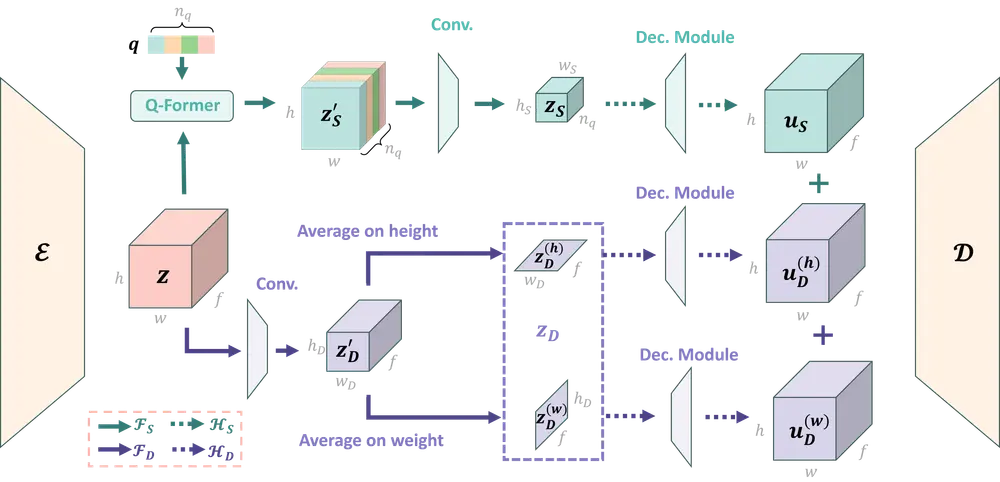
微软亚洲研究院推出新型视频自编码器VidTwin北京大学、微软亚洲研究院和香港中文大学(深圳)的研究人员推出一种新型视频自编码器(Video Autoencoder,简称Video AE),名为VidTwin。VidTwin的核心创新在于将视频分解...新技术# VidTwin# 视频自编码器1年前02970
新型采样引导方法STG:提升视频扩散模型生成质量扩散模型(DMs)近年来在生成高质量图像、视频和3D内容方面取得了显著进展。然而,现有的采样引导技术如分类器引导(CFG)虽然提高了生成内容的质量,但也带来了多样性和运动性的下降。自动引导方法虽然缓解...新技术# STG1年前02970