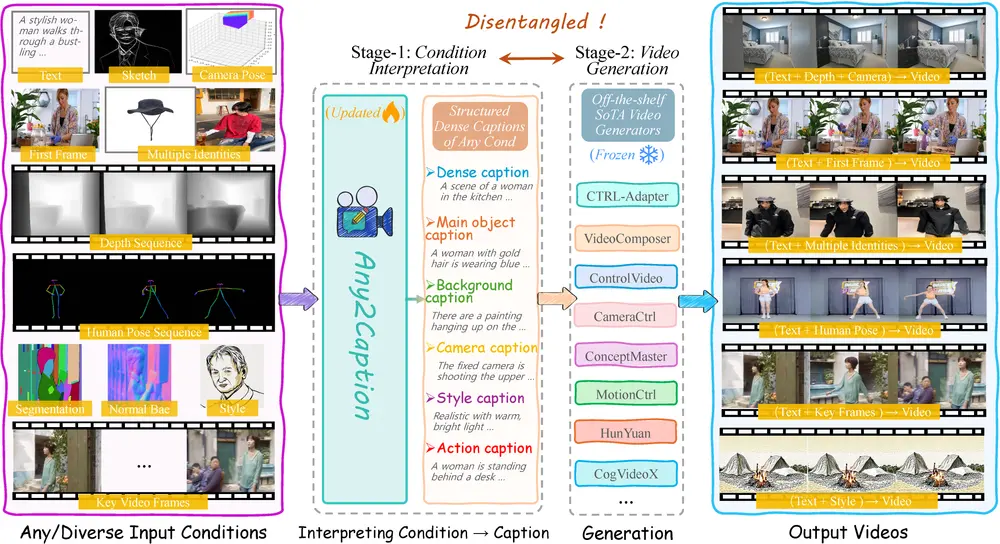
Any2Caption:通过将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为结构化的详细字幕,从而实现可控的视频生成快手和新加坡国立大学的研究人员推出新型框架 Any2Caption ,通过将多样化的输入条件(如文本、图像、视频、人体姿态、相机运动等)转化为结构化的详细字幕,从而实现可控的视频生成。这一框架的核心思...新技术# Any2Caption# 视频生成12个月前02960
多代理协作框架GENMAC:实现复杂的文本到视频生成,特别是针对组合性文本提示的生成香港大学、清华大学和微软研究院的研究人员推出多代理协作框架GENMAC,旨在实现复杂的文本到视频生成,特别是针对组合性文本提示的生成。传统的文本到视频生成模型在处理复杂场景时常常面临挑战,例如多个对象...新技术# GENMAC# 文生视频1年前02960
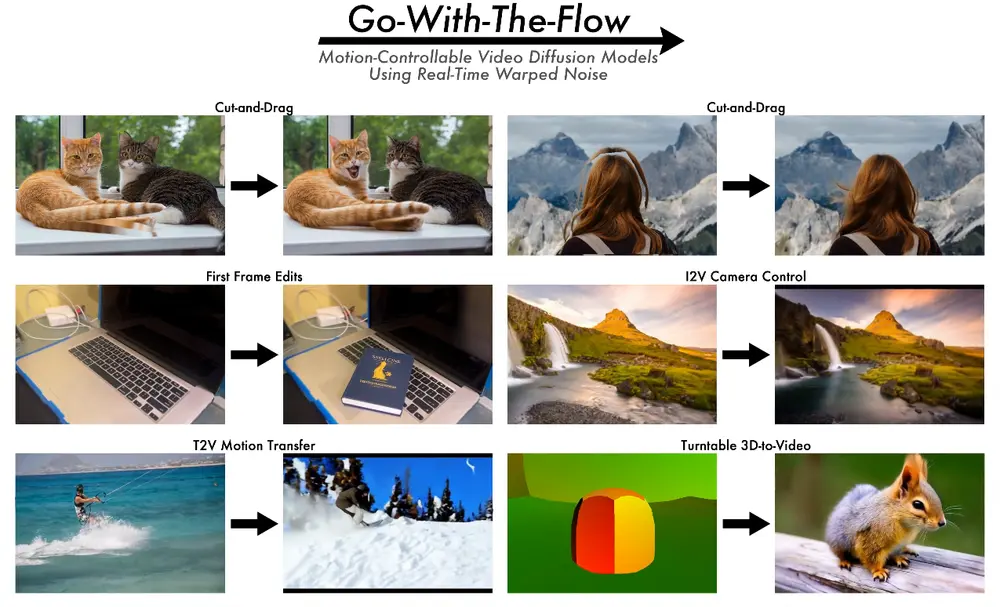
Go-with-the-Flow:通过实时扭曲噪声实现对视频生成的运动控制Netflix Eyeline Studios、Netflix、石溪大学、马里兰大学和斯坦福大学的研究人员推出一种简单高效的控制视频扩散模型运动模式的方法Go-with-the-Flow ,通过实时扭...新技术# Go-with-the-Flow1年前02950
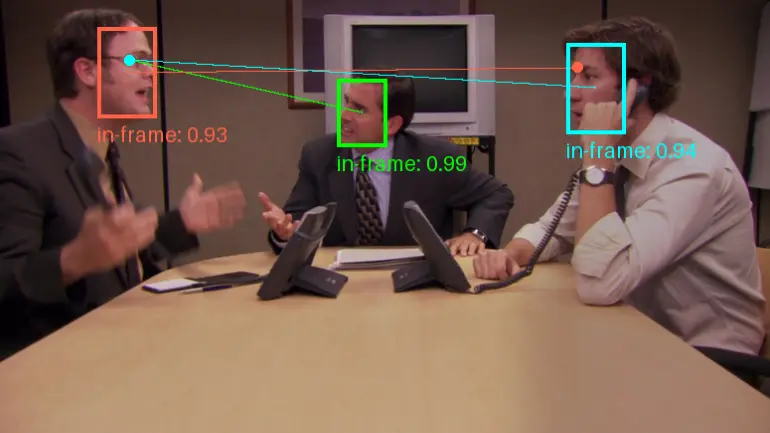
新型Transformer框架Gaze-LLE:用于估计人在场景中注视的目标位置佐治亚理工学院和伊利诺伊大学厄巴纳-香槟分校的研究人员推出新型Transformer框架,它用于估计人在场景中注视的目标位置。这项技术的核心在于预测一个人在观看什么,这需要对个体的外观和场景内容进行推...新技术# Gaze-LLE1年前02950
端到端的训练框架Mimir:通过大语言模型增强文本到视频生成蚂蚁集团和清华大学的研究人员提出了Mimir,这是一个端到端的训练框架,旨在解决当前视频扩散模型在文本理解方面的不足,并充分利用大语言模型(LLMs)的强大文本处理能力。Mimir通过引入精心设计的标...新技术# Mimir# 大语言模型1年前02950
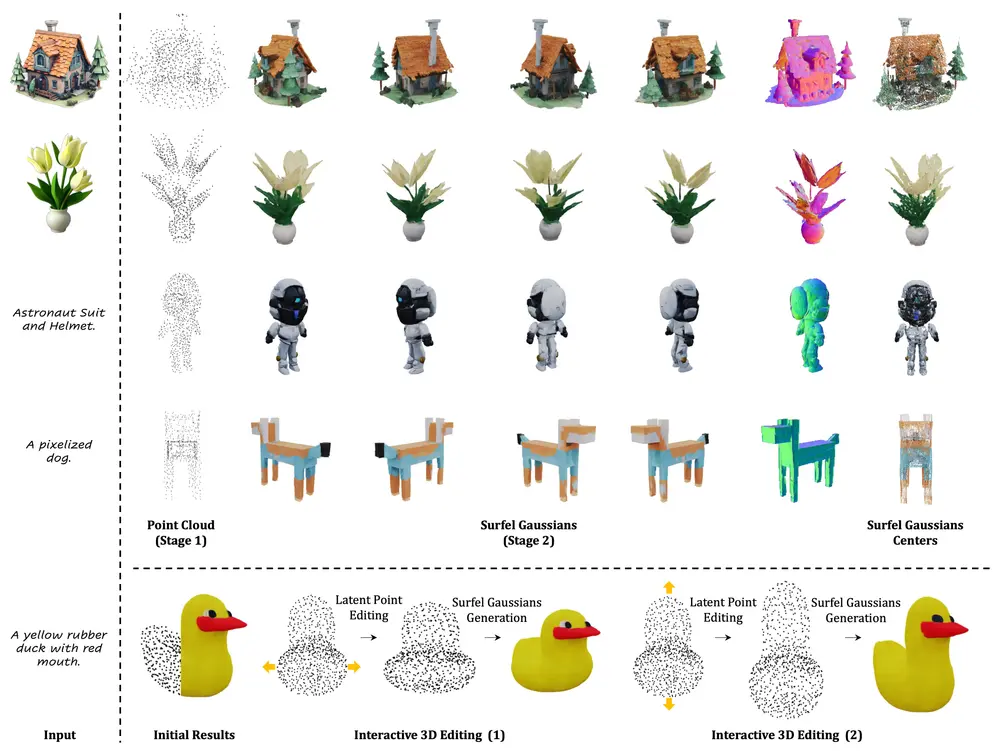
新型3D生成框架GaussianAnything:根据单视图图像或文本条件生成高质量且可编辑的3D模型新加坡南洋理工大学、上海人工智能实验室和北京大学的研究人员推出新型3D生成框架GaussianAnything,它能够根据单视图图像或文本条件生成高质量且可编辑的3D模型。这个框架通过一个级联的3D扩...新技术# 3D生成框架# GaussianAnything1年前02950
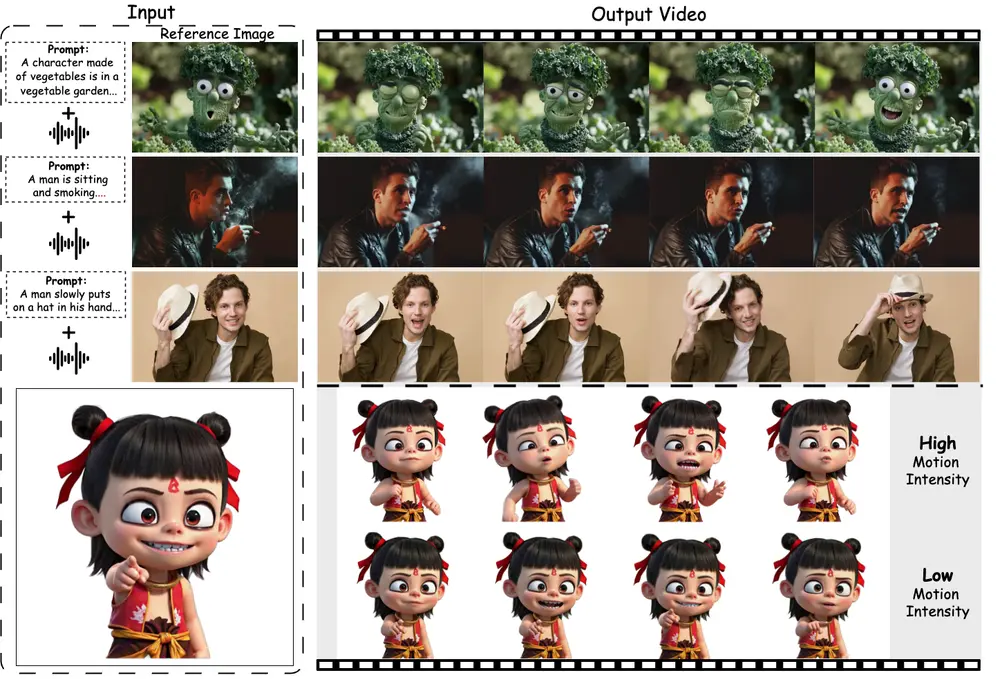
动态肖像生成框架FantasyTalking:从单张静态肖像图像生成逼真的、可动画化的动态肖像阿里巴巴和北京邮电大学的研究人员推出动态肖像生成框架FantasyTalking,从单张静态肖像图像生成逼真的、可动画化的动态肖像,使其能够根据音频信号进行自然的表情、口型和肢体动作的生成。 项目主页...新技术# FantasyTalking# 动态肖像11个月前02930
文本驱动的风格迁移方法StyleStudio:根据文本提示将特定风格的参考图像与目标内容图像结合起来西湖大学 AGI 实验室、复旦大学、南洋理工大学和香港科技大学(广州)的研究人员推出文本驱动的风格迁移方法StyleStudio,它可以根据文本提示将特定风格的参考图像与目标内容图像结合起来。这种方法...新技术# StyleStudio# 风格迁移1年前02930
SPOTLIGHT:通过扩散模型实现对虚拟对象插入图像时的光影控制拉瓦尔大学、Depix Technologies和芝加哥丰田技术学院的研究人员推出SPOTLIGHT,它用于通过扩散模型实现对虚拟对象插入图像时的光影控制。这种方法的核心在于,通过指定对象的期望阴影...新技术# SPOTLIGHT1年前02930
个性化图像生成的高效、轻量级框架DreamCache:在不需要额外微调的情况下,通过特征缓存实现快速的个性化图像生成在数字内容创作日益丰富的今天,个性化图像生成技术正逐渐成为各行业创新的关键。这项技术依赖于文本到图像的生成模型,它们能够识别并捕捉参考对象的核心特征,从而在各种情境中实现可控的图像生成。然而,现有的方...新技术# DreamCache# 个性化图像生成1年前02930
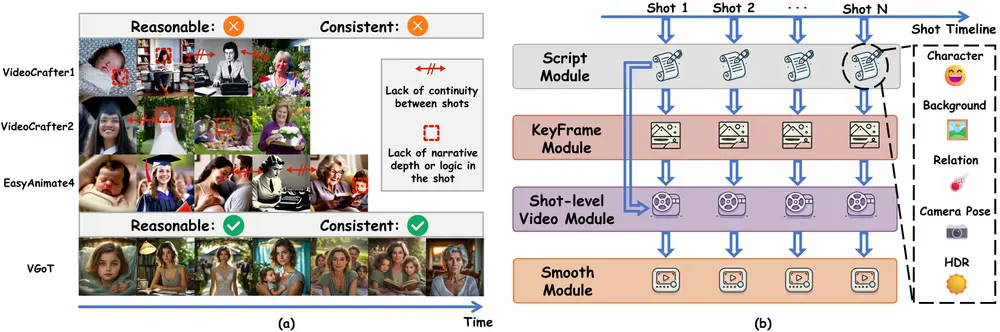
新型多镜头视频生成框架VGoT:专门针对多镜头视频生成任务设计香港科技大学、北京大学、香港大学、新加坡国立大学、中佛罗里达大学和Everlyn Al的研究人员推出新型多镜头视频生成框架VGoT,旨在解决从简短的用户输入脚本生成多镜头、电影风格视频的挑战,通过一个...新技术# VGoT# 多镜头视频1年前02910
RollingDepth:将单图像深度估计转化为高效的视频深度估计随着大型基础模型的发展和合成训练数据的广泛应用,单图像深度估计技术取得了显著进展,这重新激发了研究者对视频深度估计的兴趣。然而,直接将单图像深度估计器应用于视频每一帧的方法存在明显缺陷,如时间连续性忽...新技术# RollingDepth# 视频深度1年前02910