新型自编码器WF-VAE:为提高潜在视频扩散模型中视频变分自编码器的性能而设计北大-兔展AIGC联合实验室推出新型自编码器WF-VAE,此编码器与开源视频生成项目Open-Sora Plan相关,它是为了提高潜在视频扩散模型(Latent Video Diffusion Mod...新技术# WF-VAE# 自编码器1年前02910
新型推理加速技术SmoothCache:提高DiT模型在不同模态(如图像、视频和语音合成)任务中的推理效率DiT架构因其强大的生成能力而在图像、视频和语音合成等多个领域展现出巨大潜力。然而,由于在推理过程中需要反复评估计算密集型的注意力和前馈模块,DiT架构的计算成本较高,这成为其广泛应用的一大障碍。为了...新技术# SmoothCache# 推理加速1年前02910
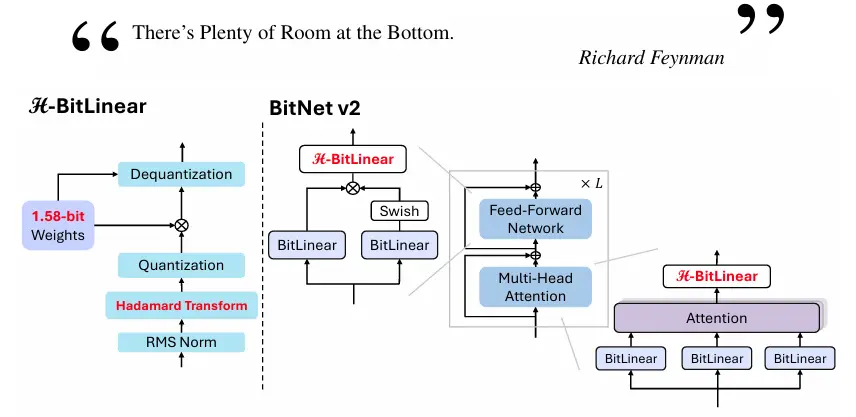
微软发布新型框架BitNet v2:为 1-bit 大型语言模型(LLMs)实现原生 4-bit 激活量化微软发布了一个名为 BitNet v2 的新型框架,旨在为 1-bit 大型语言模型(LLMs)实现原生 4-bit 激活量化。该框架通过引入 H-BitLinear 模块,解决了在低比特量化中激活值...新技术# BitNet v2# 微软11个月前02900
字节跳动推出统一的视频生成框架Phantom :通过跨模态对齐实现主体一致性的视频生成字节跳动的研究人员推出一个统一的视频生成框架Phantom ,通过跨模态对齐实现主体一致性的视频生成(Subject-to-Video, S2V),用于单主体和多主体参考,构建在现有的文本到视频和图像...新技术# Phantom# 字节跳动# 视频生成11个月前02900
1.58-bit FLUX:将FLUX.1-dev量化到1.58位权重的方法字节跳动和浦项科技大学的研究人员推出1.58-bit FLUX,这是第一个成功将最先进的文本到图像生成模型FLUX.1-dev量化到1.58位权重的方法。通过这种方法,我们能够在不损失生成质量的情况下...新技术# 1.58-bit FLUX1年前02900
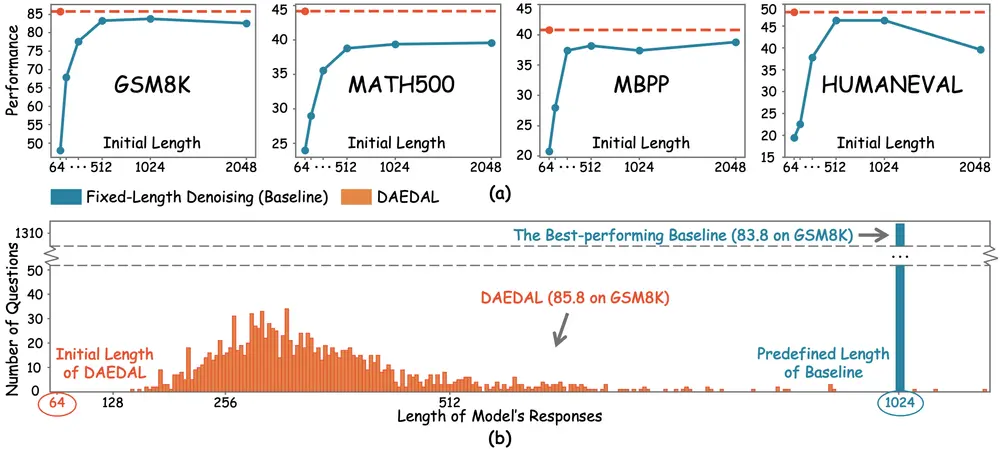
DAEDAL:无需训练的动态长度生成,释放扩散大模型新潜力在大语言模型(LLM)领域,扩散型大语言模型(Diffusion Large Language Models, DLLMs)正凭借其并行生成能力与全局上下文建模优势,成为传统自回归模型(AR)的有力竞...新技术# DAEDAL# 扩散大模型8个月前02890
无需图像数据的方法Diff-Instruct*(DI*):用于构建符合人类偏好的一步式文生图模型,同时保持生成高度逼真图像的能力北京大学、小红书和卡内基梅隆大学的研究人员推出一种无需图像数据的方法Diff-Instruct*(DI*),用于构建符合人类偏好的一步式文本到图像生成模型,同时保持生成高度逼真图像的能力。研究团队将人...新技术# Diff-Instruct*(DI*)# 一步式文生图模型1年前02890
Meta AI 推出高效图像生成新方法Token-Shuffle:在 Transformer 中减少图像 Token自回归(AR)模型在语言生成领域取得了巨大成功,但在高分辨率图像合成中的应用却面临严峻挑战。与文本不同,图像需要数千个 token 来表示,导致计算成本呈二次方增长。这使得大多数基于 AR 的多模态模...新技术# Meta AI# Token-Shuffle# 图像生成11个月前02880
NeuralSVG:用于从文本提示生成矢量图形特拉维夫大学和麻省理工学院的研究人员推出了一种名为 NeuralSVG 的新方法,用于从文本提示生成矢量图形(SVG)。该方法通过隐式神经表示(NeRFs)和分数蒸馏采样(SDS)技术,生成具有层次结...新技术# NeuralSVG1年前02880
Nested Attention:用于在文本到图像模型中实现概念个性化特拉维夫大学和Snap的研究人员推出一种名为 “Nested Attention” 的新机制,用于在文本到图像模型中实现概念个性化。该机制通过在模型的现有交叉注意力层中注入丰富且具有表现力的图像表示...新技术# Nested Attention1年前02880
视频风格化方法StyleMaster:能够对视频进行艺术化生成和风格转换香港科技大学和快手的研究人员推出视频风格化方法StyleMaster,它能够对视频进行艺术化生成和风格转换。StyleMaster通过结合全局和局部的风格表示,实现了对视频内容的风格化处理,同时保持了...新技术# StyleMaster# 视频风格化1年前02880
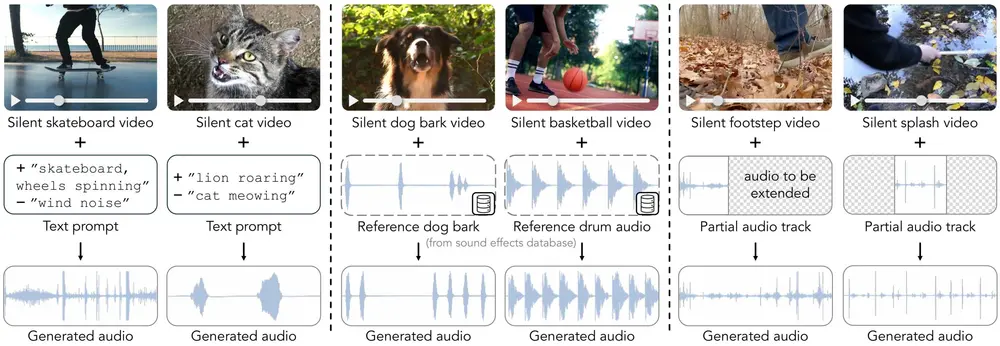
视频引导音效生成模型MultiFoley:根据多种模态的控制信号(包括文本、音频和视频)来生成与视频同步的声音效果在影视制作、游戏开发和多媒体内容创作中,为视频添加恰当的音效是提升观众体验的重要环节。然而,创造既符合视觉场景又具有艺术感的音效往往需要耗费大量时间和专业技能。为了应对这一挑战,密歇根大学与Adobe...新技术# MultiFoley# 视频引导音效生成模型1年前02880