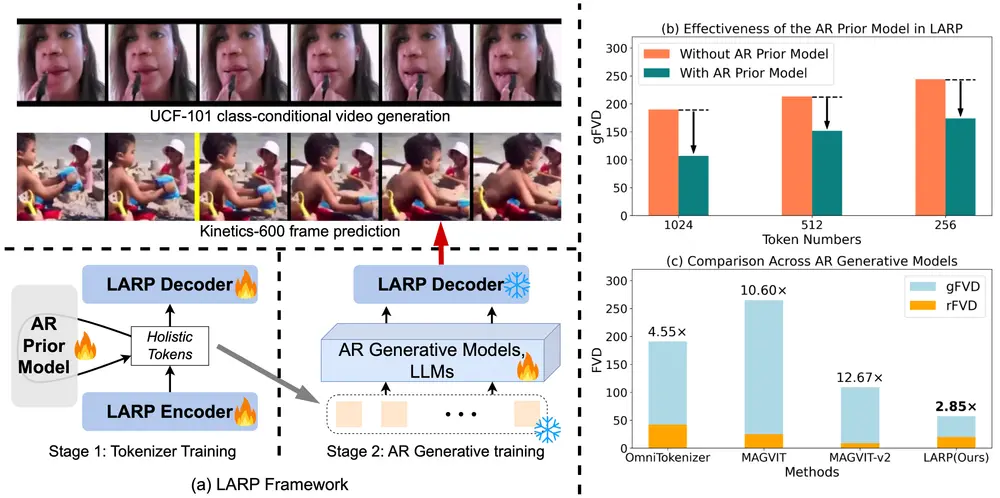
新型视频分词器LARP:专为自回归(AR)生成模型设计,用于提高视频生成任务的性能马里兰大学学院公园分校的研究人员提出了一种名为LARP(Latent Aggregation and Refinement for Perception)的新型视频分词器,它专为自回归(AR)生成模型...新技术# LARP# 视频分词器# 视频生成1年前04180
MUVERA:让多向量检索像单向量一样快的新一代高效算法在 RAG(Retrieval-Augmented Generation)系统中,信息检索是决定整体性能的关键环节。传统的单向量搜索(如基于 ElasticSearch 或 FAISS 的 MIPS...新技术# MUVERA# 向量检索8个月前04150
Golden Noise:将随机的高斯噪声转换成能够生成更高质量、与文本提示更匹配的图像的“黄金噪声”香港科技大学(广州)、穆罕默德·本·扎耶德人工智能大学和香港浸会大学的研究人员推出一种名为“Golden Noise for Diffusion Models”的学习框架,旨在提高文生图模型的性能。这...新技术# Golden Noise# 黄金噪声1年前04130
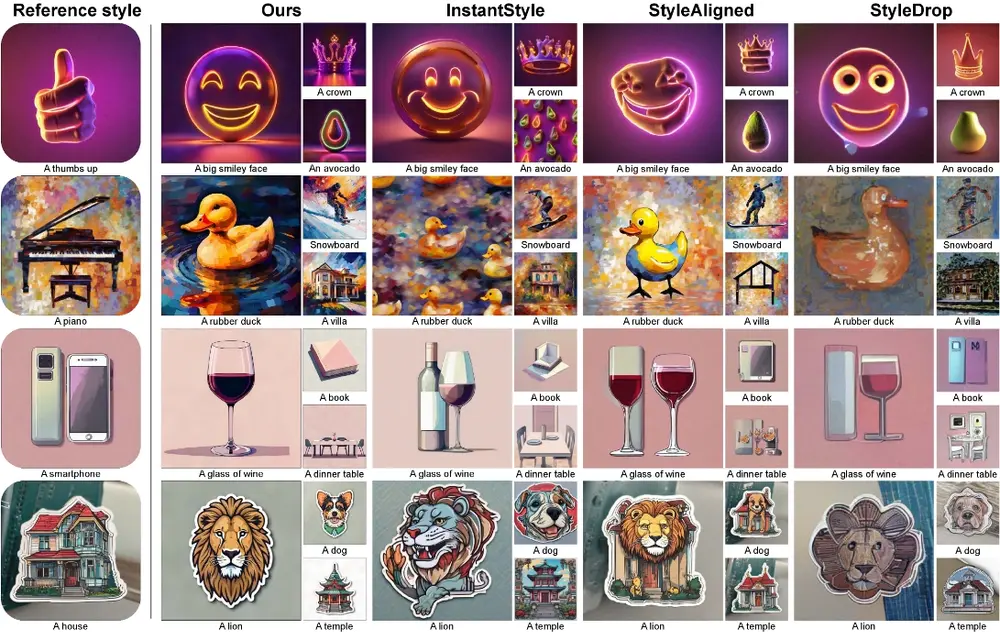
不需要额外的训练!用于个性化调整扩散模型的新方法RB-Modulation德克萨斯大学奥斯汀分校、谷歌和谷歌 DeepMind的研究人员推出一种用于个性化调整扩散模型的新方法RB-Modulation,RB-Modulation 建立在一个新颖的随机最优控制器基础上,其中样...新技术# RB-Modulation2年前04120
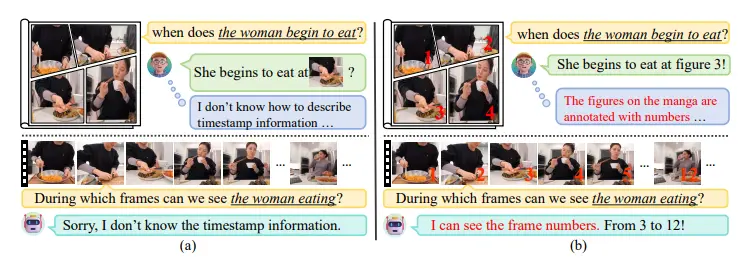
NumPro:增强视频大语言模型在视频时间定位任务中的表现东南大学、马克斯普朗克信息学研究所、腾讯微信和加州大学伯克利分校的研究人员推出了一个名为Number-Prompt(NumPro)的方法,它旨在增强视频大语言模型(Vid-LLMs)在视频时间定位(V...新技术# NumPro# 视频大语言模型1年前04110
新型文本到图像生成技术GrounDiT:利用DiT实现了无需训练的空间定位能力,实现更精细的用户控制韩国科学技术研究院推出新型文本到图像生成技术GrounDiT(GROUNDIT),它通过利用DiT实现了无需训练的空间定位能力,用于在文本到图像生成中实现更精细的用户控制。这项技术特别关注于在图像生成...新技术# GrounDiT# 文生图模型1年前04100
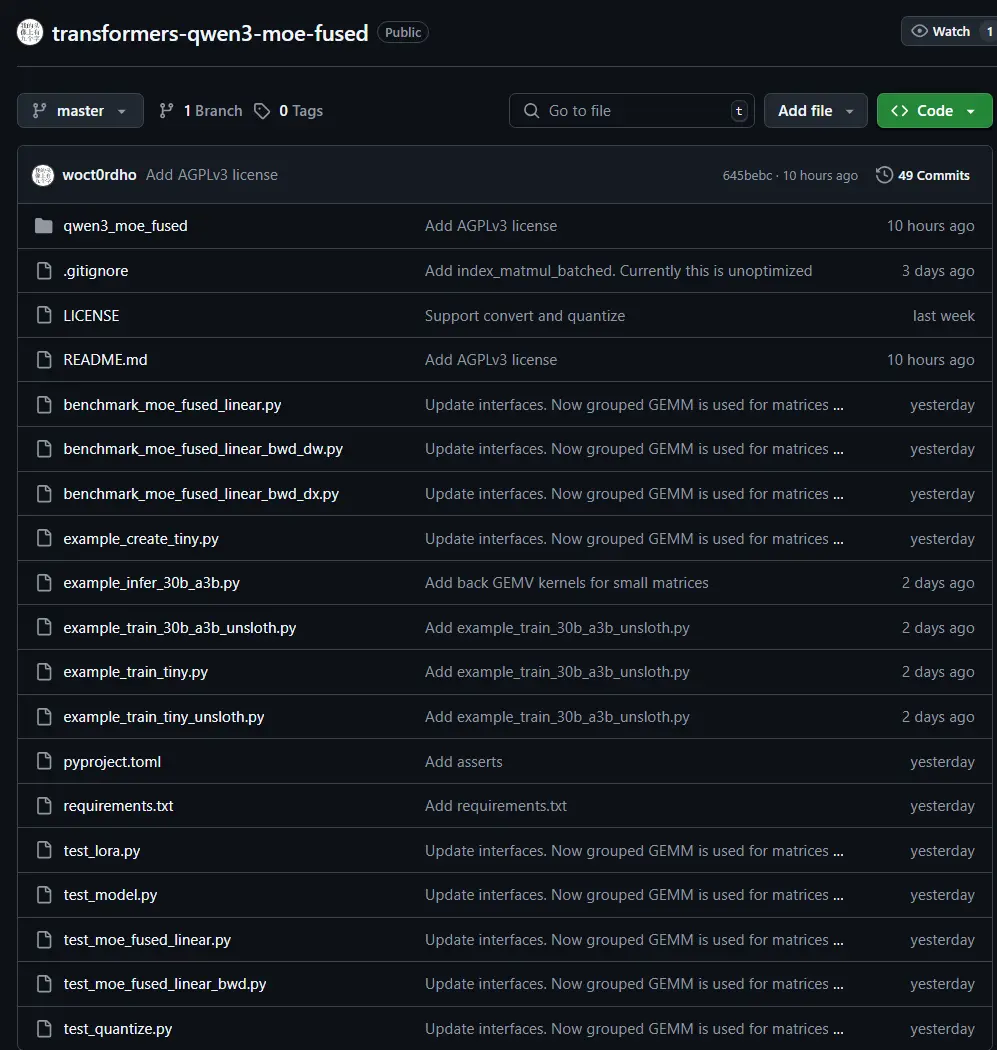
Qwen3 MoE Fused:显著提升 Qwen3 推理速度的融合专家计算方案Qwen3 MoE Fused 是一个面向 Qwen3 MoE 模型 的高性能推理优化项目,由开发者 woct0rdho 发起并实现。该项目通过重构 MoE(Mixture of Experts)中专...新技术# Qwen3 MoE Fused9个月前04090
Video-T1:视频生成任务中引入测试时扩展(TTS)技术,以提升生成视频的质量和与文本提示的一致性清华大学和腾讯的研究人员推出 Video-T1,在视频生成任务中引入测试时扩展(Test-Time Scaling, TTS)技术,以提升生成视频的质量和与文本提示的一致性。通过在推理阶段增加计算资源...新技术# TTS# Video-T1# 测试时扩展12个月前04090
新型图生视频模型VidCRAFT3:能够同时控制相机运动、物体运动和光照方向复旦大学、浙江大学、华为诺亚方舟实验室、西湖大学的研究人员推出新型高质量图像到视频生成模型VidCRAFT3 ,能够同时控制相机运动、物体运动和光照方向。它通过解耦这些视觉元素的控制,实现了对生成视频...新技术# VidCRAFT3# 视频生成1年前04090
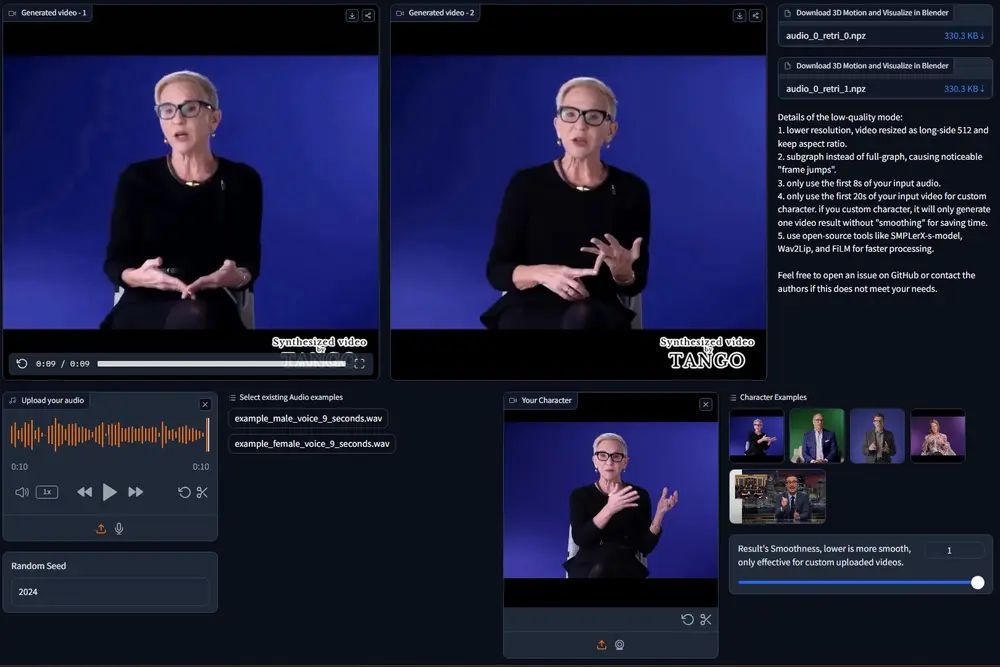
用于生成同步语音体态手势视频的框架 TANGO:把新的语音和已有的视频动作结合起来,生成高保真的、与语音同步的身体手势视频东京大学和CyberAgent 人工智能实验室的研究人员推出了一个用于生成同步语音体态手势视频的框架 TANGO,它可以从一个几分钟长的参考视频(里面有一个说话者的身体动作)和目标语音音频出发,生...新技术# TANGO# 同步语音体态手势1年前04070
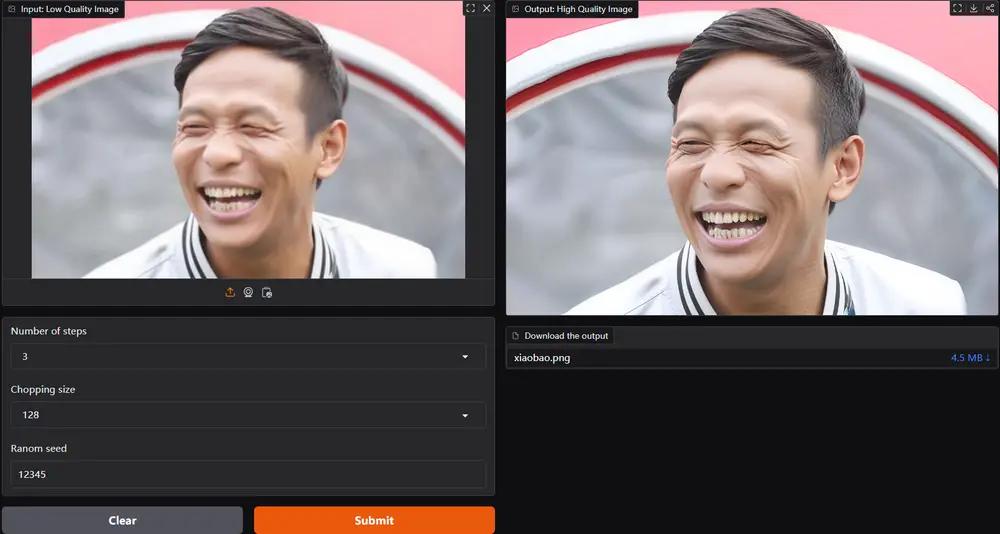
图像超分辨率技术InvSR:基于扩散反转(Diffusion Inversion)来提高图像的分辨率南洋理工大学(NTU)S-Lab提出了一种新的图像超分辨率(Super-Resolution, SR)技术——InvSR,旨在利用大型预训练扩散模型中封装的丰富图像先验来提高SR性能。传统的超分辨率方...新技术# InvSR# 图像超分辨率1年前04060
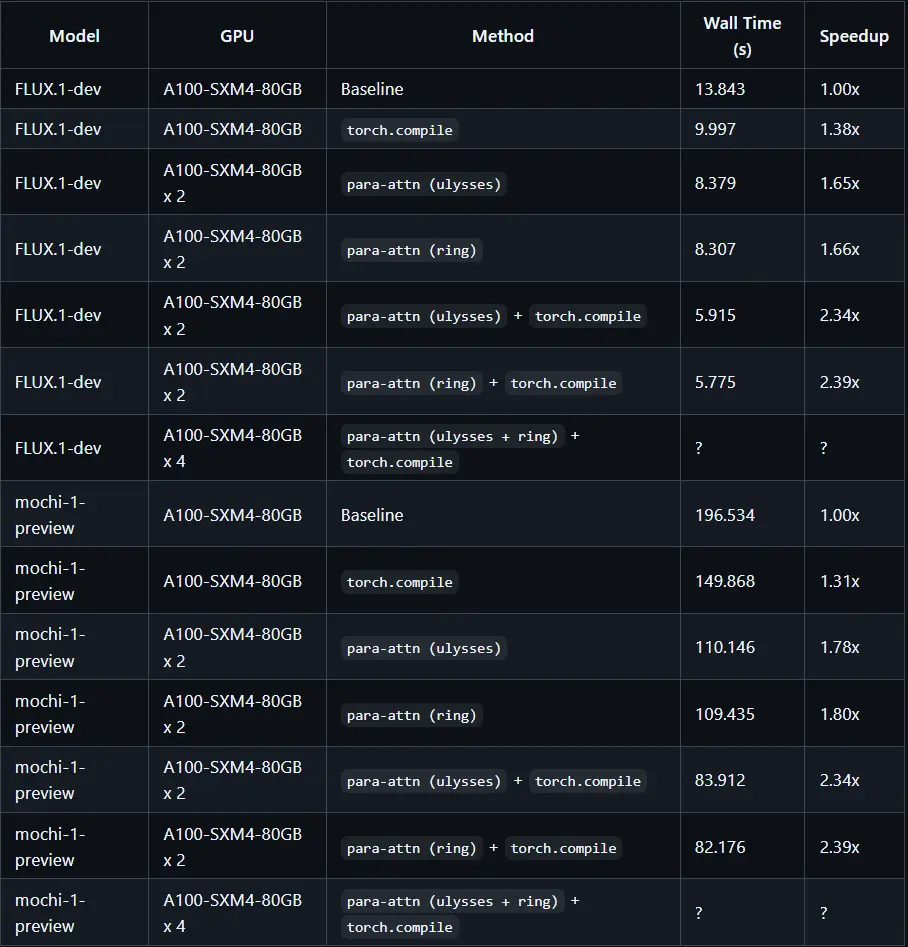
ParaAttention:通过上下文并行注意力机制,使用多个GPU加速FLUX和Mochi模型的推理ParaAttention是一种创新的上下文并行注意力机制,旨在通过多个GPU加速FLUX和Mochi模型的推理。通过支持torch.compile和多种并行策略,ParaAttention提供了高效...新技术# ParaAttention# 推理加速1年前04060