人像视频编辑方法PortraitGen:可以根据多模态提示对人像视频进行一致且富有表现力的编辑中国科学技术大学的研究人员推出人像视频编辑方法PortraitGen,该方法可以根据多模态提示对人像视频进行一致且富有表现力的编辑。例如,给定一段人物跳舞的视频,PortraitGen 可以根据文字提...新技术# PortraitGen# 人像视频编辑2年前04050
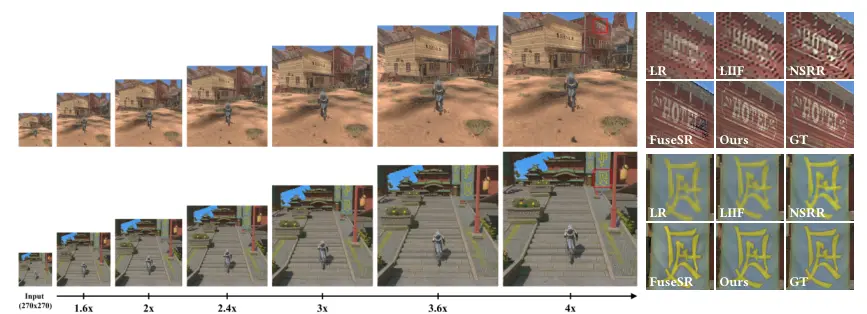
超分辨率渲染新技术框架DFASRR:实现任意比例的超分辨率渲染,以实时生成高清晰度图像南京大学计算机软件新技术国家重点实验室的研究人员介绍了一种名为“DFASRR(Deep Fourier-based Arbitrary-scale Super-resolution for Real...新技术# DFASRR# 超分辨率渲染1年前04040
ReferEverything:专为视频中通过自然语言描述的概念进行分割而设计来自卡内基梅隆大学、伊利诺伊大学香槟分校和丰田研究所的研究者们共同提出了一种名为ReferEverything(Reference Expression Modeling)的创新框架,专为视频中通过自...新技术# ReferEverything# 分割模型1年前04040
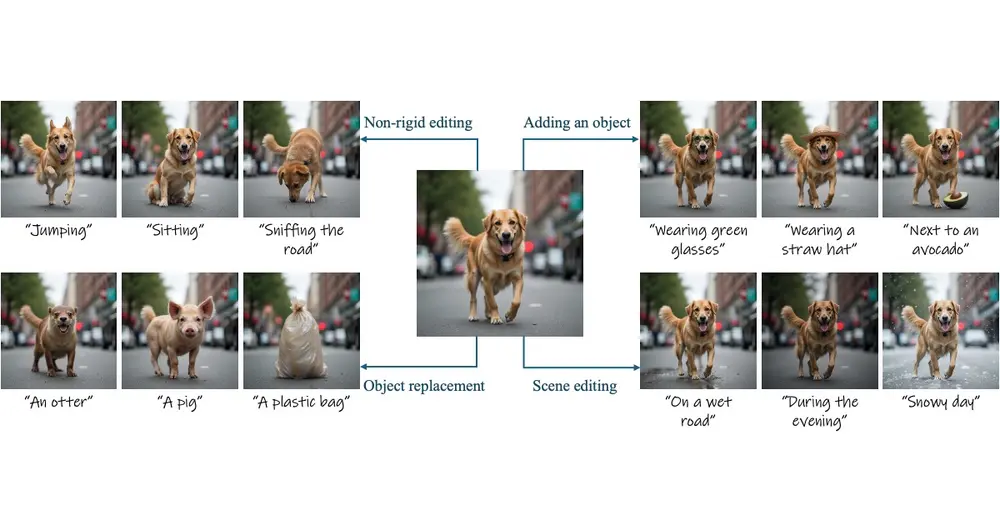
无需训练的图像编辑技术Stable Flow:执行各种类型的图像编辑操作,包括非刚性编辑、物体添加、物体替换和全局场景编辑Snap Research、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出图像编辑方法Stable Flow,这是一种无需训练的图像编辑技术,能够执行各种类型的图像编辑操作,包括非刚性编辑...新技术# Stable Flow# 图像编辑1年前04030
基于区域描述的精确布局组合文生图方法RAG:将复杂的场景分解为单独的区域,并为每个区域提供相应的文本描述,然后生成一张精确布局的图片南京大学、InstantX、Liblib AI、香港科技大学与中国移动的研究团队共同提出了一种名为RAG(Region-Aware Generation)的新方法,它是一种基于区域描述的精确布局组合文...新技术# RAG# 区域提示1年前04030
大规模视频动作数据集EgoVid-5M:专为第一人称视角(egocentric)视频生成而设计阿里巴巴集团智能计算研究院、中国科学院自动化研究所、清华大学和中国科学院大学的研究人员推出大规模视频动作数据集EgoVid-5M,专为第一人称视角(egocentric)视频生成而设计。该数据集包含了...新技术# EgoVid-5M# 视频动作数据集1年前04030
字节跳动推出 X-UniMotion:首个能精准复刻手部动作的视频生成模型字节跳动研究团队发布了一项令人瞩目的视频生成新成果 —— X-UniMotion。该模型能够基于参考人物和驱动动作视频,实现对全身动作(尤其是复杂手部动作)的高精度复现,几乎看不出瑕疵,尤其在手部细节...新技术# X-UniMotion# 字节跳动9个月前04020
ReCapture:从单个用户视频生成具有新颖摄像机轨迹的新视频最近的视频建模技术取得了显著进展,使得在生成的视频中可以控制摄像机轨迹。然而,这些方法通常不能直接应用于用户提供的视频,因为这些视频不是由视频模型生成的。为了解决这一问题,谷歌和新加坡国立大学的研究人...新技术# ReCapture# 摄像机轨迹1年前04020
腾讯混元推出新型框架 Hunyuan-GameCraft:为游戏环境生成高动态、交互式的视频内容腾讯混元项目组和华中科技大学的研究人员推出新型框架 Hunyuan-GameCraft,为游戏环境生成高动态、交互式的视频内容。Hunyuan-GameCraft 能够从单张图像和对应的提示出发,生成...新技术# Hunyuan-GameCraft# 腾讯混元9个月前04000
GS^3:从多视角点光源输入图像中实时合成高质量的新光照和视图浙江大学CAD与CG国家重点实验室推出一种新技术,用于从多视角点光源输入图像中实时合成高质量的新光照和视图。他们的方法称为 GS^3,使用基于空间和角度的高斯表示,并结合三重 splatting 过程...新技术# GS^3# 多视角点光源1年前04000
StdGEN:从单张图像生成高质量3D角色StdGEN 是由腾讯AI实验室、清华大学和北京航空航天大学的研究人员联合推出的一种创新管道,它能够从单张图片中生成语义分解的高质量3D角色模型。这项技术在虚拟现实、游戏和电影制作等领域有着广泛的应用...新技术# 3D# StdGEN1年前03990
Enhance-A-Video:利用时间注意力温度调整提升DiT架构模型的视频生成质量尽管基于DiT架构模型的视频生成技术取得了显著进展,现有模型在捕捉关键细节方面仍面临挑战。为了提高视频质量,视频增强成为一种直观的方法,其主要目标是: 保持帧间一致性:确保相邻帧之间的视觉和语义一致性...新技术# CogVideoX-2B# DiT架构模型# Enhance-A-Video1年前03970