用于长视频生成的双速学习系统SLOWFAST-VGEN:模仿了人类大脑中慢速学习和快速学习相结合的互补学习系统人类拥有一个独特的学习系统,它既能从普遍的世界规律中缓慢学习,也能迅速地将新的经历转化为情景记忆。这种能力使我们在面对新情况时能灵活应对,同时保持对已知世界的深刻理解。然而,现有的视频生成技术大多聚焦...新技术# SLOWFAST-VGEN# 长视频生成1年前05080
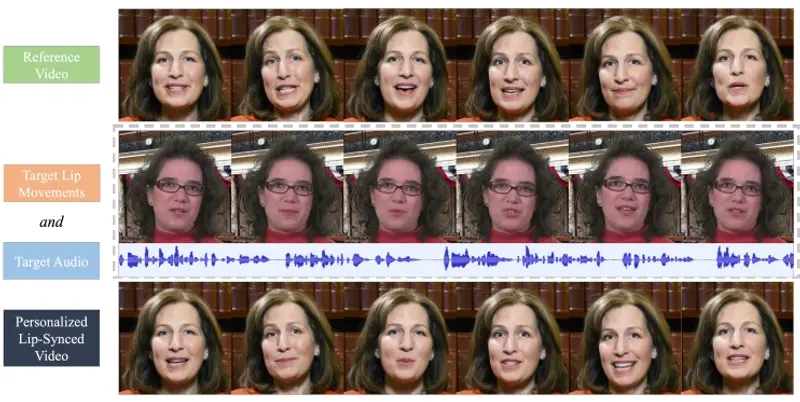
用于视觉配音的先进框架PersonaTalk:实现高保真和个性化的视觉配音在音频驱动的视觉配音中,合成准确的口型同步同时保持和突出说话者的“个性”是一个巨大的挑战。现有方法往往未能捕捉到说话者的独特说话风格或保留面部细节。为了解决这一问题,字节跳动提出了 PersonaTa...新技术# PersonaTalk# 视觉配音1年前04890
无需训练的新策略FasterCache:加速高质量视频生成的视频生成模型的推理视频生成是当前 AI 领域的一个热点研究方向,特别是基于扩散模型的方法。然而,这些模型的推理速度通常较慢,限制了它们在实际应用中的效率。香港大学、南洋理工大学 S-Lab 和上海人工智能实验室的研究人...新技术# FasterCache# 视频生成1年前06640
CAMI2V:引入物理约束提升文生视频模型中的相机控制精度浙江大学计算机科学与技术学院的研究团队推出一个名为CAMI2V(Camera-Controlled Image-to-Video Diffusion Model)的模型,它是一个基于扩散模型的图像到视...新技术# CAMI2V# 文生视频# 相机控制1年前04460
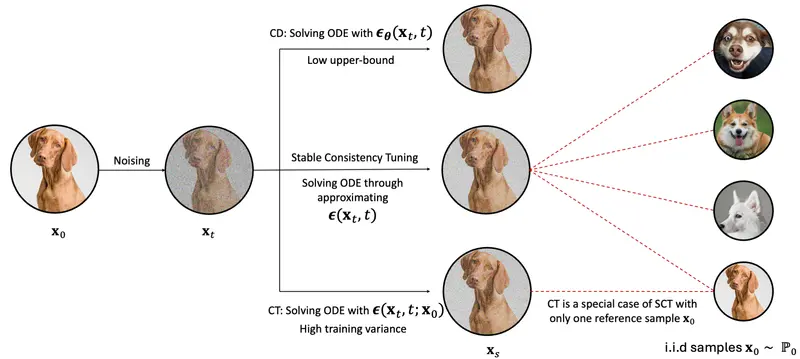
新框架SCT:旨在理解和改进一致性模型香港中文大学和卡内基梅隆大学的研究人员提出了一个名为Stable Consistency Tuning(SCT)的新框架,旨在理解和改进一致性模型(Consistency Models)。一致性模型是...新技术# SCT# 一致性模型1年前04520
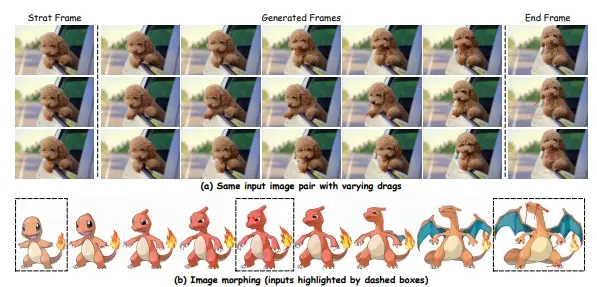
交互式帧插值工具Framer:根据用户的创造力生成两个图像之间平滑过渡的帧帧插值是生成两个图像之间平滑过渡帧的技术,广泛应用于视频处理、动画制作和内容创作等领域。传统的帧插值方法通常依赖于固定的算法,难以实现对局部运动的精细控制。浙江大学和蚂蚁集团的研究人员提出了Frame...新技术# Framer# 帧插值1年前07110
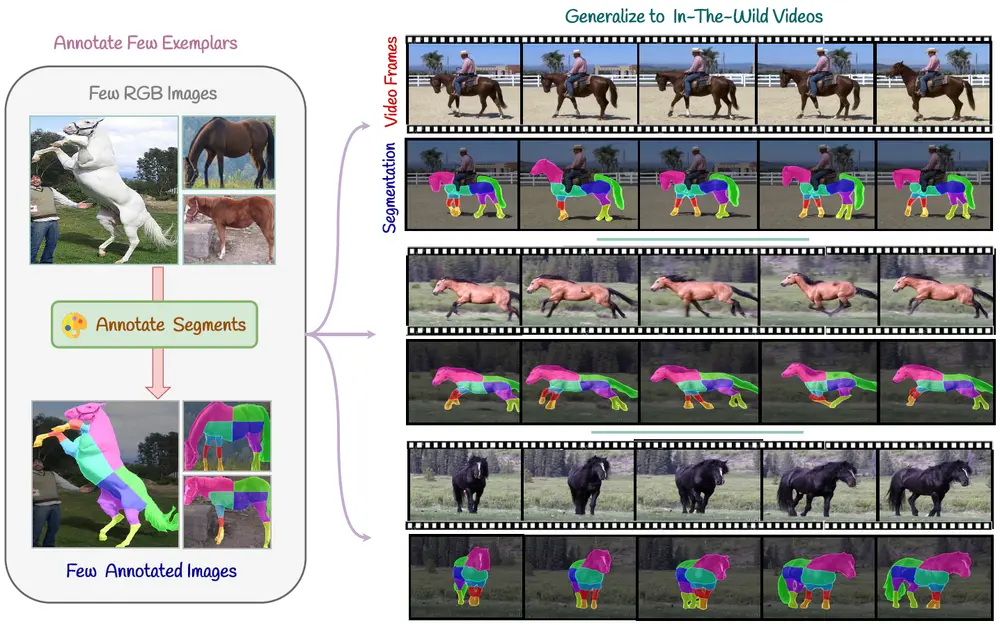
视频对象分割技术SMITE:解决视频内对象的分割问题,特别是在需要任意粒度(即对象可以被分割成不同数量的片段)的情况下视频对象分割是一项具有挑战性的任务,每个像素必须被准确标记,并且这些标签必须在帧之间保持一致。当分割具有任意粒度时,难度会进一步增加,这意味着段的数量可以任意变化,并且掩模仅基于一个或几个样本图像定义...新技术# SMITE# 视频对象分割1年前06840
RankDPO:提高模型在遵循文本提示和视觉质量方面的表现直接偏好优化(DPO)已成为一种强大的方法,用于将文本到图像(T2I)模型与人类反馈对齐。然而,成功应用DPO需要大量的资源来收集和标注大规模数据集,例如数百万张生成的人类偏好注释的配对图像。此外,随...新技术# RankDPO1年前05170
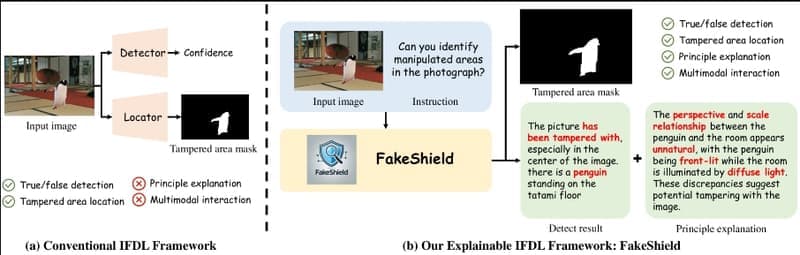
多模态框架FakeShield:通过多模态大语言模型评估图像的真实性,用于检测AI及PS图片生成式AI的快速发展为内容创作带来了巨大便利,但同时也使得图像篡改变得更加容易且难以检测。当前的图像伪造检测和定位(IFDL)方法虽然通常有效,但仍面临两大挑战: 黑箱性质:检测原理未知,难以理解和解...新技术# FakeShield# 多模态框架1年前06540
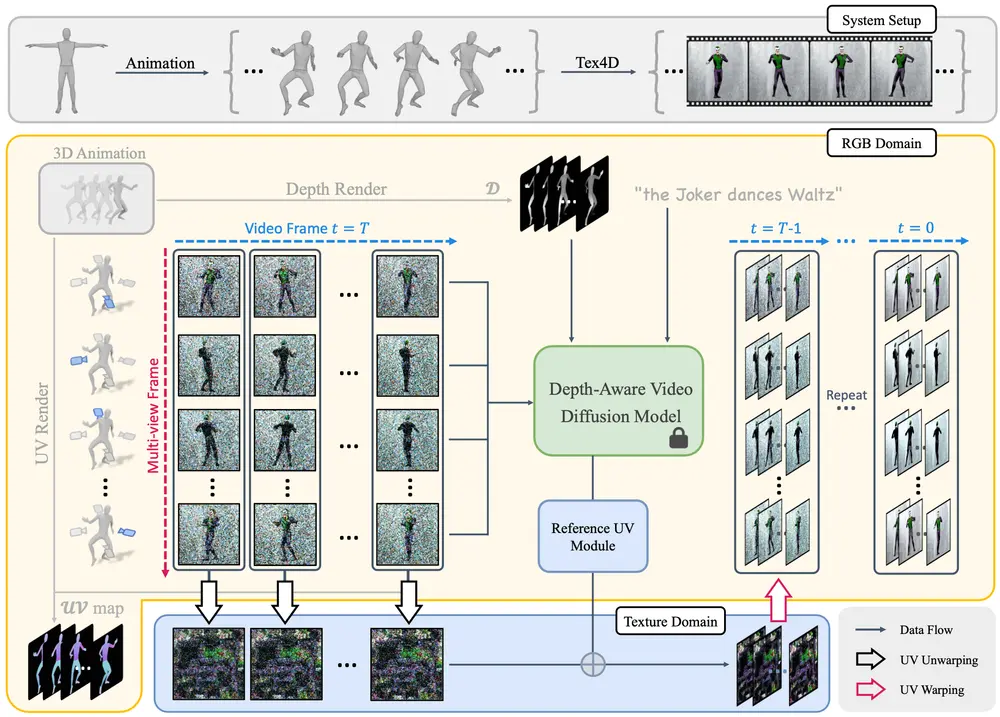
4D 场景纹理化Tex4D:使用视频扩散模型为未纹理化的动画网格序列生成多视图、时间一致的 4D 纹理来自香港中文大学(深圳)、NVIDIA 和加州大学默塞德分校的研究人员开发了 Tex4D,这是一种零样本方法,使用视频扩散模型为未纹理化的动画网格序列生成多视图、时间一致的 4D 纹理。简单来说,如果...新技术# 4D 场景# 4D 纹理# Tex4D1年前03780
FlexGen框架:能够根据单一视角的图像、文本提示或两者的结合来灵活生成可控制且一致的多视图图像来自香港科技大学(广州)、香港科技大学和趣玩的研究人员开发了一个名为FlexGen的框架,它能够根据单一视角的图像、文本提示或两者的结合来灵活生成可控制且一致的多视图图像。想象一下,你给FlexGen...新技术# FlexGen1年前04590
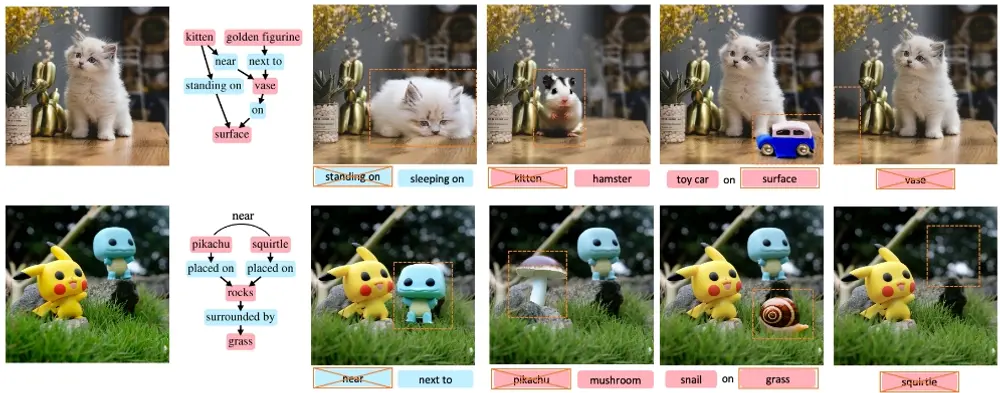
结合了大语言模型与文生图模型的新框架SGEdit:用于基于场景图的精确和灵活的图像编辑场景图提供了一种结构化、层次化的图像表示方式,其中节点和边分别代表图像中的对象及其相互关系。这种方式不仅能够帮助用户更直观地理解图像内容,还能作为图像编辑的有效接口,极大提升了编辑工作的准确性和灵活性...新技术# SGEdit# 图像编辑# 大语言模型1年前04640