GS^3:从多视角点光源输入图像中实时合成高质量的新光照和视图浙江大学CAD与CG国家重点实验室推出一种新技术,用于从多视角点光源输入图像中实时合成高质量的新光照和视图。他们的方法称为 GS^3,使用基于空间和角度的高斯表示,并结合三重 splatting 过程...新技术# GS^3# 多视角点光源1年前04000
新型图像生成技术“集合自回归模型”(SAR):通过改变图像生成的顺序和方式,使得生成图像的速度和灵活性都得到了极大的提升香港中文大学MMLab 、上海人工智能实验室和南京大学的研究人员推出一种新的图像生成技术“集合自回归模型”(Set AutoRegressive Modeling,简称SAR)。你可以把它想象成一个超...新技术# SAR# 图像生成# 集合自回归模型1年前04260
新型条件图像生成模型BiGR:不仅能创作出高质量的图像,还能理解和识别图像中的内容香港大学、香港科技大学、云天励飞和香港中文大学的研究人员介绍了一种名为BiGR(Binary Generative Representation)的新型条件图像生成模型。BiGR 使用紧凑的二进制潜在...新技术# BiGR# 条件图像生成模型1年前04840
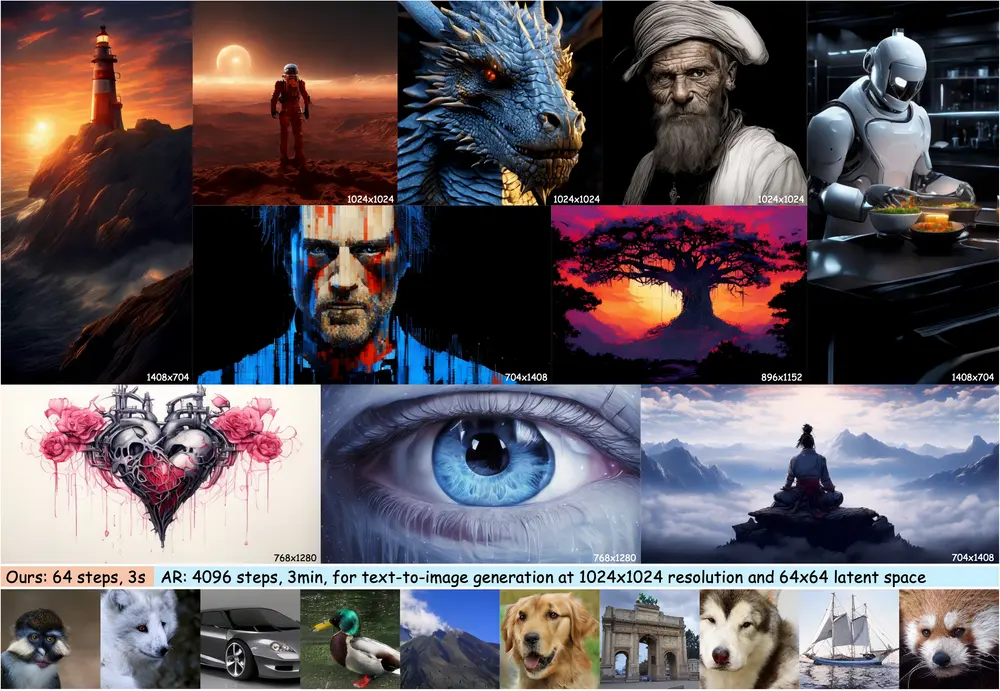
灵活视觉变换器FiT v2:根据给定的文本描述或已有的图像,生成高质量、高分辨率的新图像自然界的图像具有无穷的分辨率,而现有的扩散模型(如扩散变换器)在处理超出其训练领域的图像分辨率时常常面临挑战。为了解决这一限制,研究人员提出了一种新的视角,将图像概念化为具有动态大小的令牌序列,而不是...新技术# FiT v2# 灵活视觉变换器1年前04550
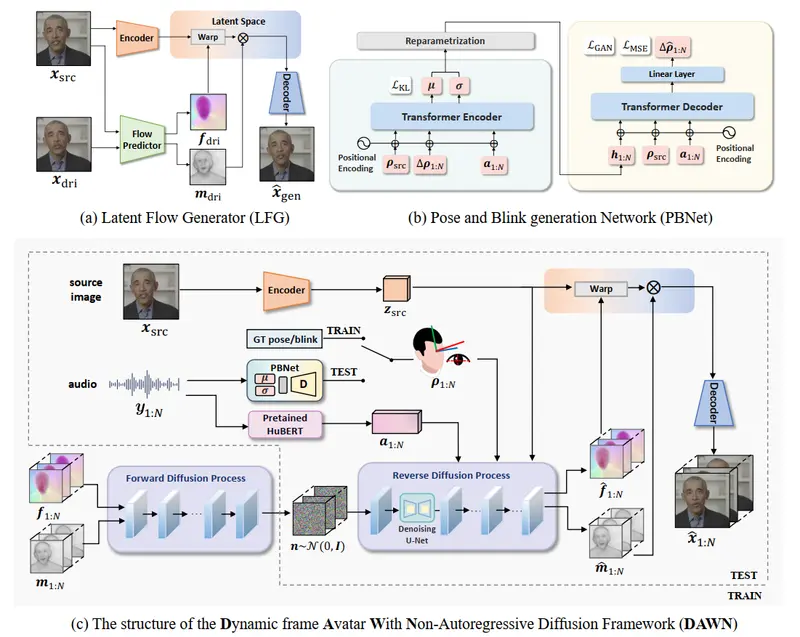
非自回归扩散框架的动态帧化身DAWN:根据单一的肖像图像和语音音频剪辑生成生动、逼真的头部动画视频中国科学技术大学和科大讯飞研究院的研究人员推出新框架DAWN,它能够根据单一的肖像图像和语音音频剪辑生成生动、逼真的头部动画视频。这项技术的核心在于使用非自回归(NAR)扩散模型来一次性生成动态长度的...新技术# DAWN# 头部动画1年前05130
EvolveDirector 框架:通过使用公开可用的资源来训练一个能够与高级文生图模型相媲美的模型近年来,生成模型在生成高质量图像方面取得了显著进展,但大多数模型依赖于专有的高质量数据集,并且有些模型保留了其参数,只提供可访问的应用程序编程接口(APIs)。这限制了这些模型在下游任务中的应用。为了...新技术# EvolveDirector# 文生图模型1年前04800
角色图像动画化Animate-X:基于潜在扩散模型(LDM)的通用动画框架,让图像上的角色动起来近年来,角色图像动画技术取得了显著进展,即从参考图像和目标姿态序列生成高质量视频。然而,大多数现有方法仅适用于人体,对拟人化角色(如卡通角色、游戏角色等)的泛化效果不佳。这种限制主要归因于对运动的建模...新技术# Animate-X# 角色图像动画化1年前03790
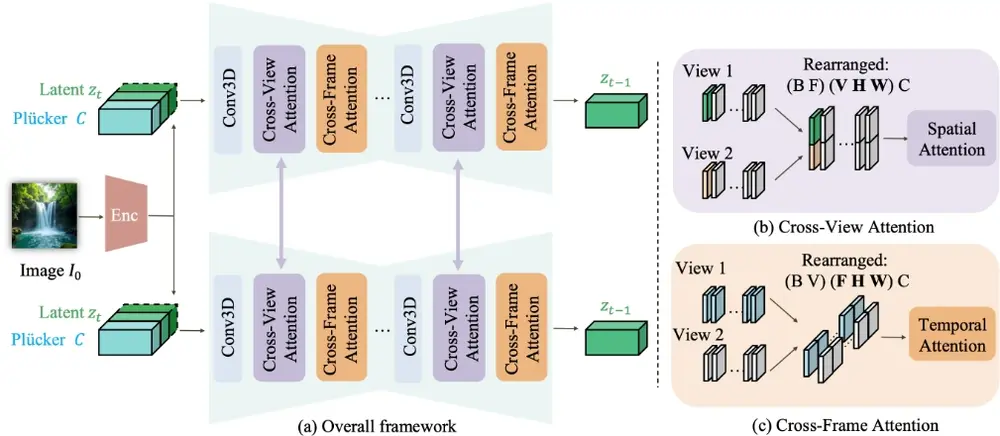
新型框架Cavia:生成具有相机控制功能的多视角视频德克萨斯大学奥斯汀分校、苹果和谷歌的研究人员推出新型框架Cavia,它能够生成具有相机控制功能的多视角视频。简单来说,Cavia可以根据一张图片和一些相机运动的指令,生成一系列从不同角度和时间点观察的...新技术# Cavia1年前04860
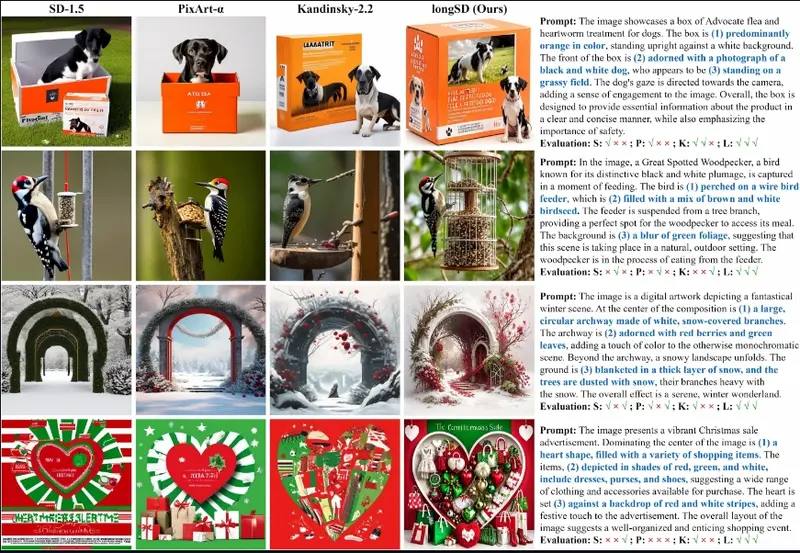
LongAlign:改进文生图模型的长文本对齐文生图模型的快速发展使它们能够从给定的文本生成前所未有的结果。然而,随着文本输入变长,现有的编码方法如 CLIP 面临限制,并且将生成的图像与长文本对齐变得具有挑战性。为了解决这些问题,香港大学、新加...新技术# LongAlign# 文生图模型# 长文本对齐1年前08140
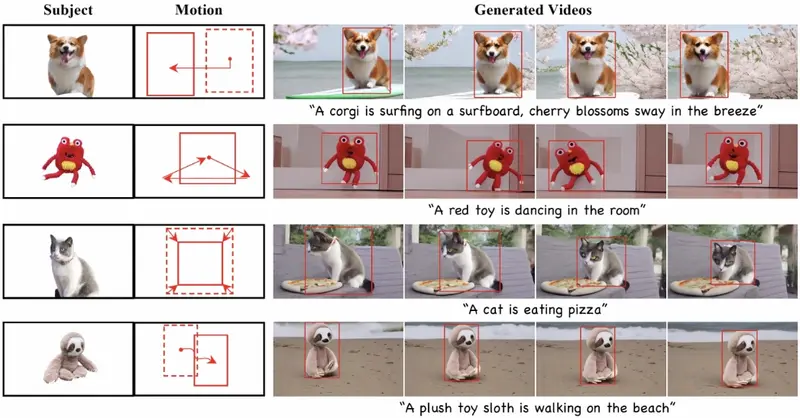
零样本视频定制框架DreamVideo-2:根据单一图像和一系列界定框序列生成具有特定主题和运动轨迹的视频复旦大学、阿里巴巴、南洋理工大学和密歇根州立大学的研究人员推出一个零样本视频定制框架DreamVideo-2,能够根据单一图像和一系列界定框(bounding box)序列生成具有特定主题和运动轨迹的...新技术# DreamVideo-2# 视频定制1年前06690
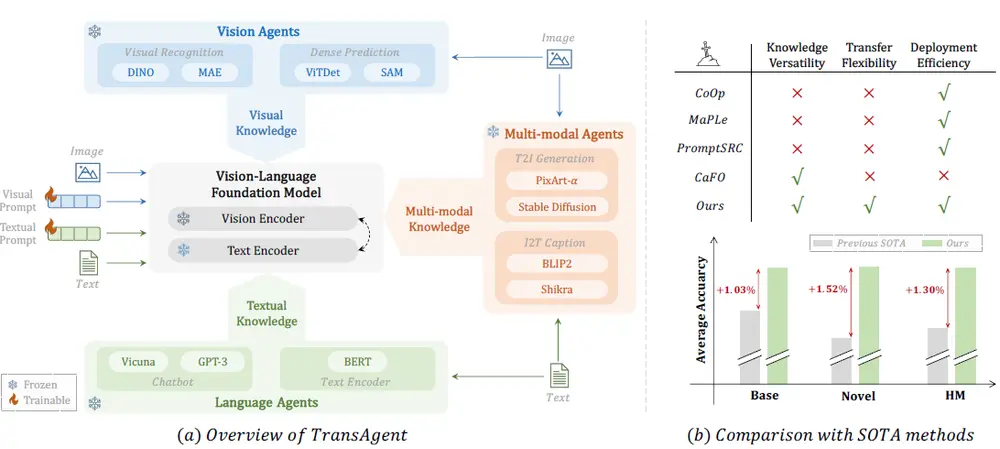
TransAgent 框架:提升视觉-语言基础模型(比如CLIP)在新领域中的泛化能力中国科学院深圳先进技术研究院、中国科学院大学、上海人工智能实验室和上海交通大学的研究人员推出一个通用且简洁的 TransAgent 框架,它的目标是提升视觉-语言基础模型(比如CLIP)在新领域中的泛...新技术# CLIP模型# TransAgent 框架1年前04900
条件对比对齐CCA:提升自回归(AR)视觉生成模型的样本质量无分类器引导(CFG)是提高视觉生成模型样本质量的关键技术。然而,在自回归(AR)多模态生成中,CFG 在语言和视觉内容之间引入了设计不一致性,这与统一不同模态的视觉 AR 设计理念相矛盾。受语言模型...新技术# CCA# 条件对比对齐# 视觉生成模型1年前06080