新型个性化图像生成方法Infinite-ID:保持特定身份特征的同时,根据用户的文本描述生成高质量的图像来自中国科学技术大学和悉尼大学的研究人员推出新型个性化图像生成方法Infinite-ID,它能够在保持特定身份特征的同时,根据用户的文本描述生成高质量的图像。这是一个全新的ID-语义解耦范式,专门用于...新技术# Infinite-ID# 个性化图像生成2年前05130
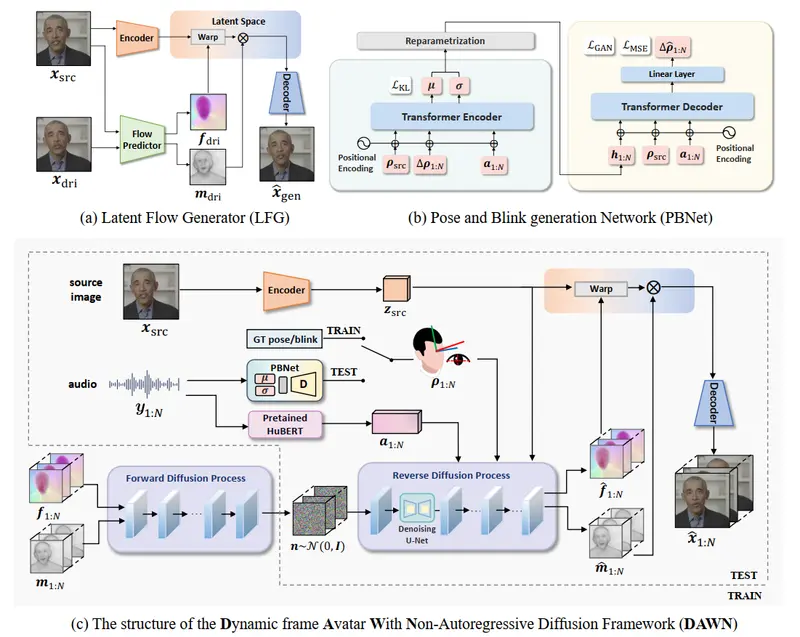
非自回归扩散框架的动态帧化身DAWN:根据单一的肖像图像和语音音频剪辑生成生动、逼真的头部动画视频中国科学技术大学和科大讯飞研究院的研究人员推出新框架DAWN,它能够根据单一的肖像图像和语音音频剪辑生成生动、逼真的头部动画视频。这项技术的核心在于使用非自回归(NAR)扩散模型来一次性生成动态长度的...新技术# DAWN# 头部动画1年前05110
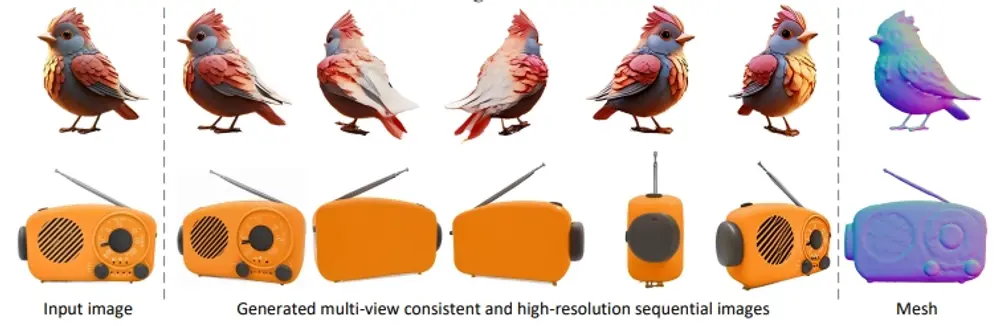
新型高分辨率图像到3D生成框架Hi3D:将单张2D图片转换成具有高分辨率纹理细节的3D模型复旦大学计算机学院、新加坡管理大学和智象未来的研究人员推出新型高分辨率图像到3D生成框架Hi3D,Hi3D 的目标是将单张2D图片转换成具有高分辨率纹理细节的3D模型。这就像给一个平面的照片施魔法,让...新技术# 3D# 3D模型# Hi3D2年前05110
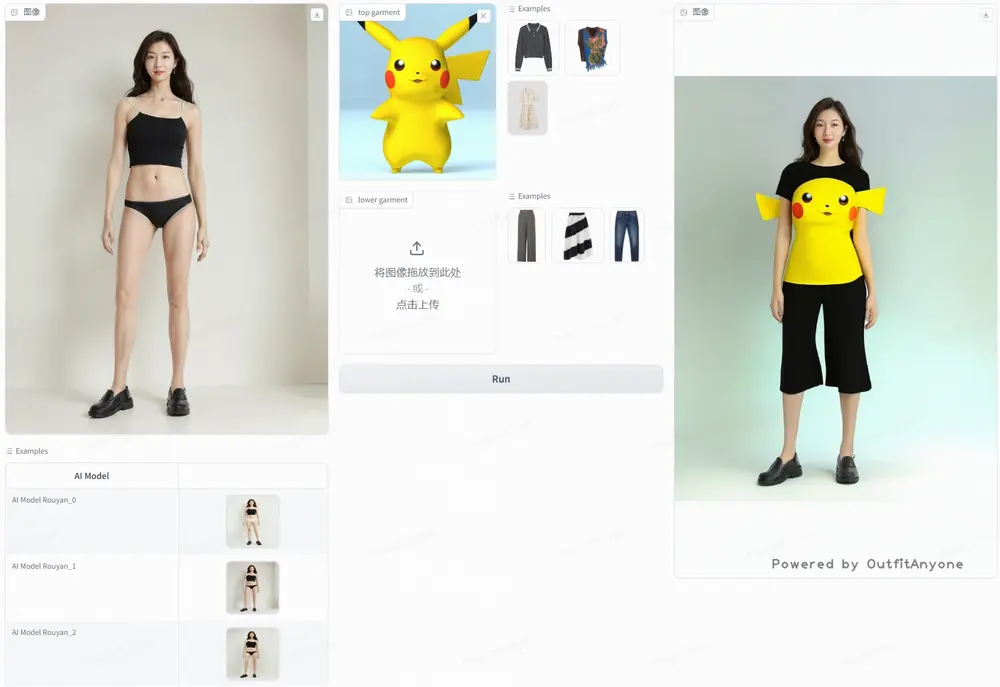
基于扩散模型的2D虚拟试穿框架OutfitAnyone:通过上传自己的照片和想要试穿的衣服图片,就能在线看到衣服穿在自己身上的样子阿里巴巴和中国科学技术大学的研究人员推出新的虚拟试穿技术OutfitAnyone,它是一个基于扩散模型的2D虚拟试穿框架。Outfit Anyone 通过利用双流条件扩散模型解决了这些局限性,使其能够...新技术# OutfitAnyone# 虚拟试穿2年前05110
用于长视频生成的双速学习系统SLOWFAST-VGEN:模仿了人类大脑中慢速学习和快速学习相结合的互补学习系统人类拥有一个独特的学习系统,它既能从普遍的世界规律中缓慢学习,也能迅速地将新的经历转化为情景记忆。这种能力使我们在面对新情况时能灵活应对,同时保持对已知世界的深刻理解。然而,现有的视频生成技术大多聚焦...新技术# SLOWFAST-VGEN# 长视频生成1年前05080
视觉模型PLLaVA:能够理解视频中的内容,包括动作、场景、人物穿着等,并能够生成详细描述这些内容的字幕来自新加坡国立大学、纽约大学和字节跳动的研究人员推出用于视频密集字幕生成的先进模型PLLaVA(Pooling LLaVA),此模型的主要功能是能够理解视频中的内容,包括动作、场景、人物穿着等,并能够...新技术# PLLaVA# 视觉模型2年前05080
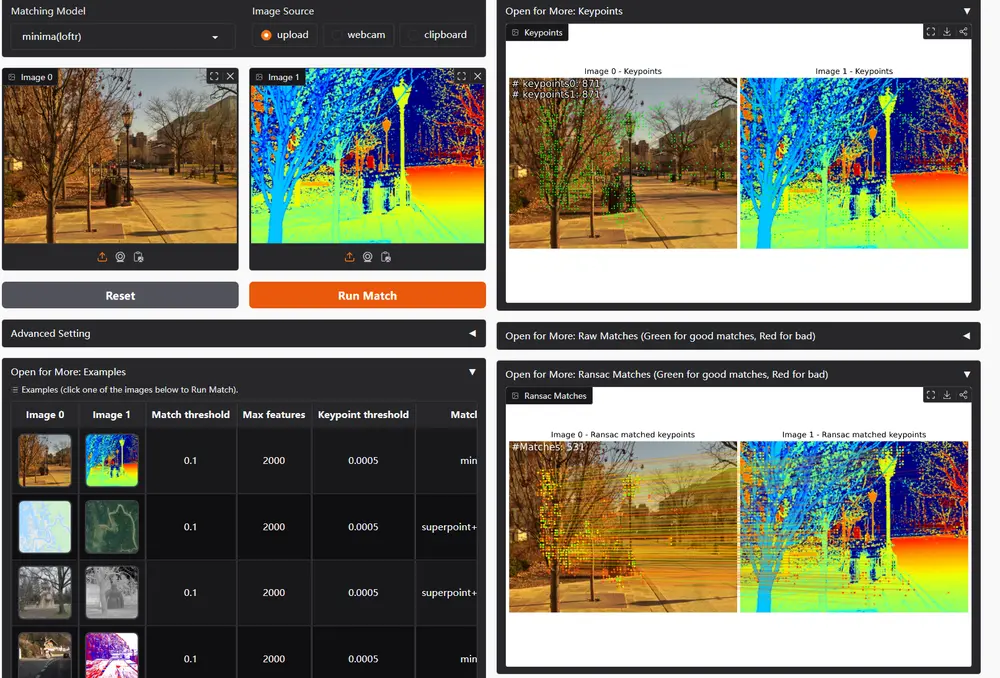
图像匹配框架MINIMA:解决跨视图和跨模态的情况下,多模态感知中的图像匹配问题华中科技大学和武汉大学的研究人员推出一个统一的图像匹配框架MINIMA,即模态不变图像匹配。这项研究旨在解决多模态感知中的图像匹配问题,特别是在跨视图和跨模态的情况下。例如,在自动驾驶中,需要将可见光...新技术# MINIMA# 图像匹配框架1年前05070
视频生成通用世界模型WorldDreamer:可以完成自然场景和自动驾驶场景多种视频生成任务来自清华和极佳科技的研究人员联手推出了全新的视频生成通用世界模型WorldDreamer。它可以完成自然场景和自动驾驶场景多种视频生成任务,例如文生视频、图生视频、视频编辑、动作序列生视频等。 项目主...新技术# WorldDreamer# 视频生成2年前05060
苹果推出基于最优传输理论的通用框架ACT:用于控制大型生成模型的生成过程大型生成模型(如大语言模型LLMs和文本到图像扩散模型T2Is)的能力不断增强,但其日益广泛的部署也引发了对可靠性和安全性的担忧。为了解决这些问题,研究人员提出了通过引导模型激活来控制模型生成的方法...新技术# ACT# 大语言模型# 文生图模型1年前05050
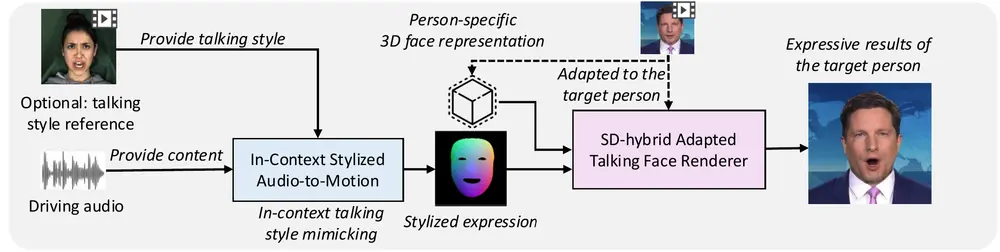
MimicTalk:用于实现特定说话人的高表现力的虚拟人视频合成说话人脸生成(Talking Face Generation, TFG)的目标是将目标身份的脸部动画化,以创建逼真的说话视频。个性化TFG是这一任务的一个重要变体,强调生成的视频在静态外观和动态说话风...新技术# MimicTalk# 虚拟人1年前05050
StyleCineGAN:从单张风景静图生成循环播放的动态图像韩国科学技术院推出StyleCineGAN,它能够自动从单张风景静图生成循环播放的动态图像,也就是所谓的“cinemagraph”,让普通用户和专业人士都能够轻松创建高质量的cinemagraph,无...新技术# StyleCineGAN# 动态图像2年前05040
FouriScale:从预训练的扩散模型中生成高质量的高分辨率图像来自香港中文大学-商汤科技联合实验室、香港中文大学感知与交互智能研究中心、中山大学、商汤科技研究院 和北京航空航天大学的研究团队提出了一种创新的、无需额外训练的方法—FouriScale,它旨在从预训...新技术# FouriScale# 扩散模型2年前05040