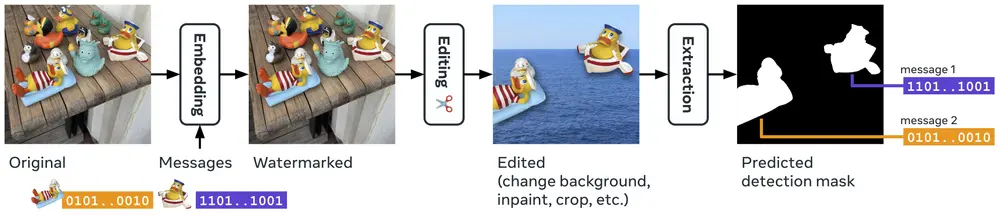
Meta推出局部图像水印的深度学习模型WAM图像水印技术在保护数字内容的版权和完整性方面发挥着重要作用。然而,传统的图像水印方法并未针对处理小面积水印区域进行优化,这限制了其在实际应用中的使用,例如图像的部分可能来自不同来源或已被编辑。Meta...新技术# WAM# 图像水印1年前06730
英伟达推出图像生成模型家族Edify Image:能够生成高保真度的图像内容,并且具有像素级完美准确性英伟达推出图像生成模型家族Edify Image,它们能够生成高保真度的图像内容,并且具有像素级完美准确性。Edify Image利用了一系列级联的像素空间扩散模型,这些模型通过一个新颖的拉普拉斯扩散...新技术# Edify Image# 图像生成# 英伟达1年前05910
英伟达推出Add-it:基于文本指令在图像中添加对象的创新方法英伟达、特拉维夫大学和巴伊兰大学的研究人员推出一个名为Add-it的系统,它是一种无需训练的方法,可以在图像中根据文本提示添加对象。这种方法扩展了预训练扩散模型的注意力机制,以整合来自三个关键来源的信...新技术# Add-it# 英伟达1年前03390
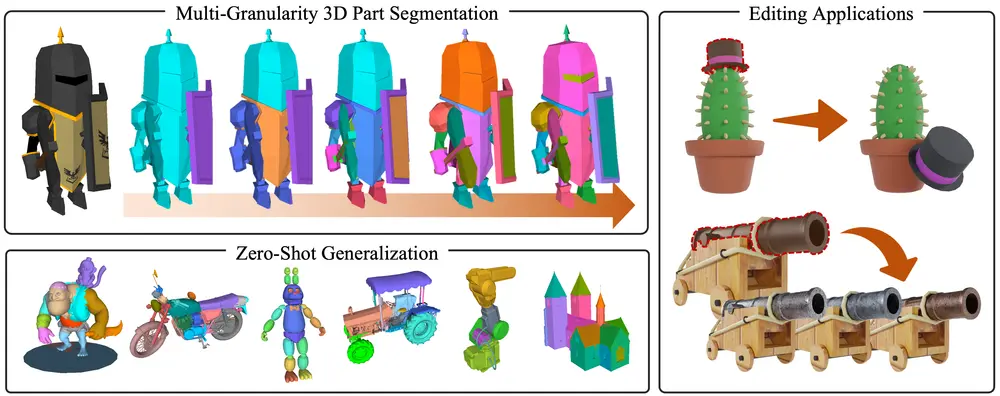
SAMPart3D:可扩展的零样本3D部件分割框架3D部件分割是3D感知中的一项关键任务,在机器人、3D生成和3D编辑等应用中发挥着重要作用。最近的方法利用强大的视觉语言模型(VLMs)进行2D到3D的知识蒸馏,实现了零样本的3D部件分割。然而,这些...新技术# 3D部件分割框架# SAMPart3D1年前03820
StdGEN:从单张图像生成高质量3D角色StdGEN 是由腾讯AI实验室、清华大学和北京航空航天大学的研究人员联合推出的一种创新管道,它能够从单张图片中生成语义分解的高质量3D角色模型。这项技术在虚拟现实、游戏和电影制作等领域有着广泛的应用...新技术# 3D# StdGEN9个月前03710
大型多模态模型VideoGLaMM:专为用户提供的文本输入进行视频中细粒度像素级定位而设计视频与文本之间的细粒度对齐是一个具有挑战性的问题,因为视频中存在复杂的空间和时间动态。现有的基于视频的大型多模态模型(LMMs)虽然可以处理基本对话,但在视频中进行精确的像素级定位方面存在困难。 大型...新技术# VideoGLaMM# 大型多模态模型1年前04730
可控图像到视频生成框架SG-I2V:用于在图像到视频的生成过程中实现对象和相机运动的控制图像到视频生成技术已经取得了显著的进步,能够生成高度逼真的视频。然而,调整生成视频中的特定元素,如物体运动或相机移动,通常需要繁琐的试错过程,例如使用不同的随机种子重新生成视频。最近的技术通过微调预训...新技术# SG-I2V# 视频生成1年前04650
DimensionX框架:从单张图像生成逼真的3D和4D场景,实现对空间和时间维度的可控生成香港科技大学、清华大学和生数科技的研究人员推出一个名为DimensionX的框架,它能够从单张图片生成高逼真度的3D和4D场景,并且通过视频扩散技术(video diffusion)实现对空间和时间维...新技术# DimensionX1年前06020
新的4位量化方法SVDQuant:通过量化权重和激活值为4位来加速模型的推理过程,同时保持图像质量扩散模型因其在生成高保真图像方面的卓越能力而备受关注。然而,这些模型在内存和计算方面的要求非常高,这限制了它们在消费级设备和需要低延迟的应用中的部署。为了解决这些问题,研究人员提出了多种技术,包括后训...新技术# SVDQuant# 量化方法10个月前06680
ReCapture:从单个用户视频生成具有新颖摄像机轨迹的新视频最近的视频建模技术取得了显著进展,使得在生成的视频中可以控制摄像机轨迹。然而,这些方法通常不能直接应用于用户提供的视频,因为这些视频不是由视频模型生成的。为了解决这一问题,谷歌和新加坡国立大学的研究人...新技术# ReCapture# 摄像机轨迹1年前03790
专门为I2V模型量身定制的大规模数据集TIP-I2V:包含了超过170万独特的用户提供的文本和图像提示AI驱动的视频生成领域正在迅速发展,图像到视频(I2V)模型因其视觉一致性和增强的可控性而处于前沿。然而,一个显著的差距一直存在:缺乏专门的数据集来理解图像到视频提示的独特需求。为了填补这一空白,悉尼...新技术# TIP-I2V# 图生视频模型1年前03260
基于注意力的运动扩散模型MotionCLR:无需额外的训练实现人体动作生成人类运动生成的交互式编辑是一个重要的研究领域,特别是在动画、游戏和虚拟现实等应用中。然而,现有的运动扩散模型存在两个主要问题: 缺乏对词级文本-运动对应关系的显式建模:这限制了模型在细粒度编辑方面的能...新技术# MotionCLR# 人体动作生成1年前03360