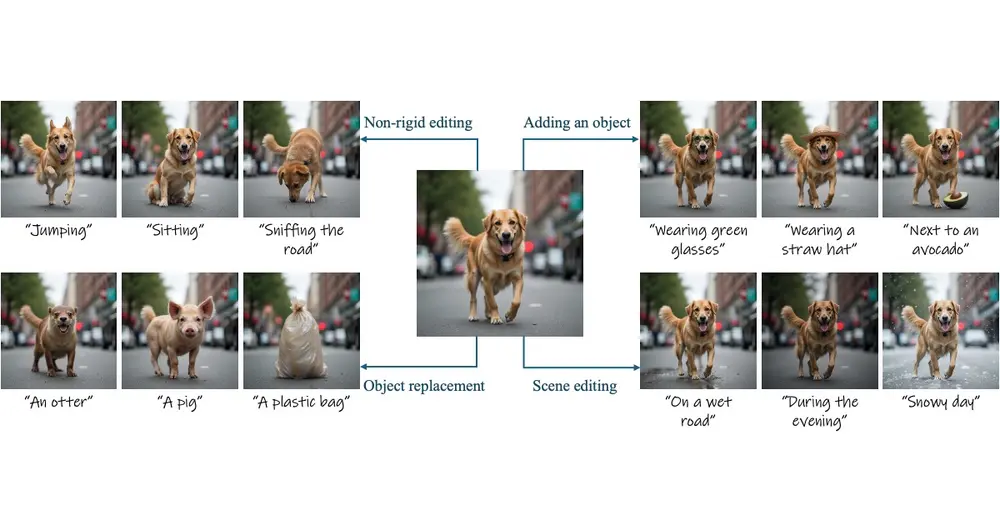
无需训练的图像编辑技术Stable Flow:执行各种类型的图像编辑操作,包括非刚性编辑、物体添加、物体替换和全局场景编辑Snap Research、耶路撒冷希伯来大学、特拉维夫大学和赖希曼大学的研究人员推出图像编辑方法Stable Flow,这是一种无需训练的图像编辑技术,能够执行各种类型的图像编辑操作,包括非刚性编辑...新技术# Stable Flow# 图像编辑1年前03950
基础世界模型The Matrix:用于生成无限长度和实时的视频在追求高质量、实时视频生成的过程中,研究人员和开发者们面临着一系列挑战。传统的视频生成模型往往因高昂的计算成本、有限的视频时长以及缺乏实时交互性而受到限制。特别是在需要长时间、高分辨率视频生成的应用场...新技术# The Matrix# 世界模型1年前03440
Reducio-DiT:通过先进压缩技术提升视频生成效率随着技术的进步,视频生成模型已经能够创造出令人惊叹的高质量视频片段。然而,这些模型在实际应用中面临着一些显著的障碍,主要集中在计算资源的需求上。目前市场上的领先模型,例如Sora、Runway Gen...新技术# Reducio-DiT# Reducio-VAE1年前03420
开源版风格参考StyleCodes:能够将图像风格表达为一个 20 符号的 base64 代码扩散模型在图像生成方面取得了显著的成功,但如何有效地控制生成图像的风格仍然是一个挑战。虽然使用示例图像可以实现风格控制,但这种方法存在一些不便:示例图像体积较大,不易于分享,且可能涉及隐私问题。为此...新技术# Midjourney# StyleCodes# 风格参考1年前04250
SSAM 2增强版SAMURAI:专门设计用于视觉物体跟踪Segment Anything Model 2 (SAM 2) 是一个在物体分割任务中表现出色的模型,但在视觉物体跟踪方面仍面临一些挑战。特别是在处理拥挤场景中快速移动或自我遮挡的物体时,SAM 2...新技术# SAMURAI# SSAM 21年前06180
SageAttention2:适用于即插即用推理加速的精确4位注意力机制尽管线性层的量化技术已经广泛应用于深度学习模型中,但在加速注意力机制方面的应用仍然有限。为了提高注意力计算的效率并保持高精度,清华大学的研究团队提出了 SageAttention2,这是一个基于低精度...新技术# SageAttention2# 推理加速1年前03130
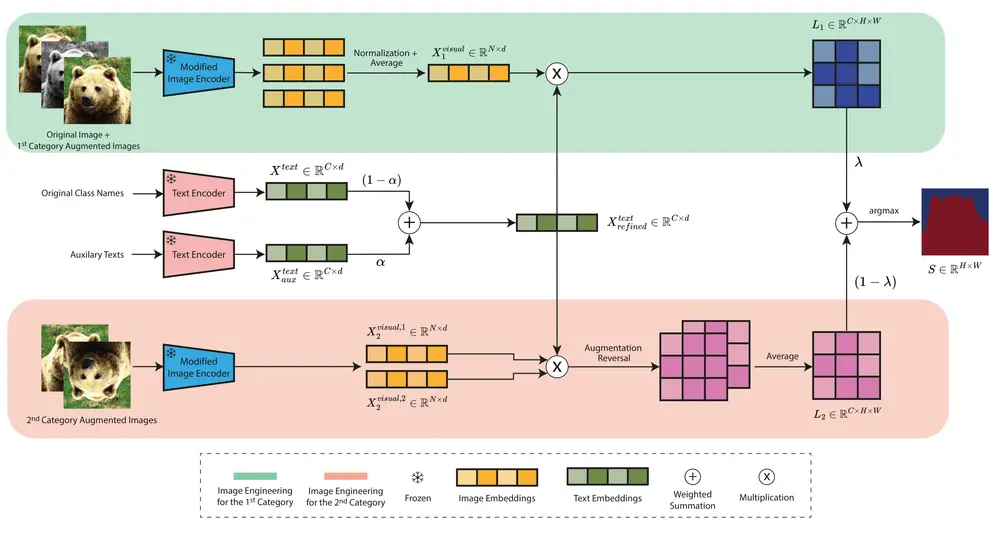
ITACLIP:通过图像、文本和架构增强提升无需训练的语义分割近年来,基础视觉语言模型(VLMs)的发展彻底改变了计算机视觉领域的研究方向。这些模型,尤其是 CLIP,不仅推动了开放词汇计算机视觉任务的研究,还在多个领域取得了显著成果。然而,尽管 VLMs 在开...新技术# ITACLIP# 语义分割1年前03790
CSpD:用于加速自回归图像生成模型的推理过程中国科学院大学、中国科学院自动化研究所和中国铁塔的研究人员介绍了一种名为“Continuous Speculative Decoding”(CSpD)的技术,用于加速自回归(Autoregressiv...新技术# CSpD# 推理加速1年前03050
新型推理加速技术SmoothCache:提高DiT模型在不同模态(如图像、视频和语音合成)任务中的推理效率DiT架构因其强大的生成能力而在图像、视频和语音合成等多个领域展现出巨大潜力。然而,由于在推理过程中需要反复评估计算密集型的注意力和前馈模块,DiT架构的计算成本较高,这成为其广泛应用的一大障碍。为了...新技术# SmoothCache# 推理加速1年前02870
视频编辑方法STABLEV2V:解决视频编辑中形状一致性问题中国科学技术大学的研究人员推出视频编辑方法STABLEV2V,旨在解决视频编辑中形状一致性问题。STABLEV2V通过一系列顺序过程来编辑视频:首先编辑第一帧视频,然后建立交付动作与用户提示之间的对齐...新技术# STABLEV2V# 视频编辑1年前05400
新型虚拟试穿技术FitDiT:专为优化DiT模型的虚拟试穿性能而设计尽管基于图像的虚拟试穿技术已取得显著进展,但在生成高保真度和适应性强的拟合图像上仍面临诸多挑战。尤其在纹理感知维护和尺寸感知拟合等关键领域,现有方法往往难以达到理想效果,这限制了技术的整体实用性。为应...新技术# FitDiT# 虚拟试穿11个月前03610
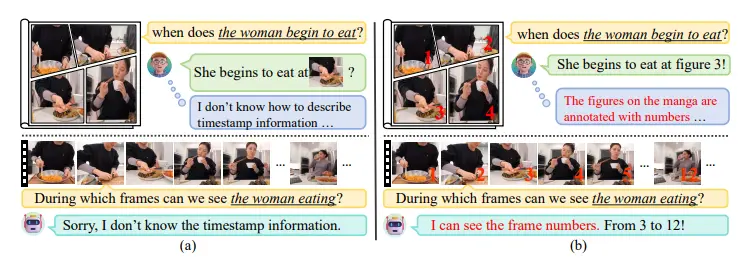
NumPro:增强视频大语言模型在视频时间定位任务中的表现东南大学、马克斯普朗克信息学研究所、腾讯微信和加州大学伯克利分校的研究人员推出了一个名为Number-Prompt(NumPro)的方法,它旨在增强视频大语言模型(Vid-LLMs)在视频时间定位(V...新技术# NumPro# 视频大语言模型1年前02760