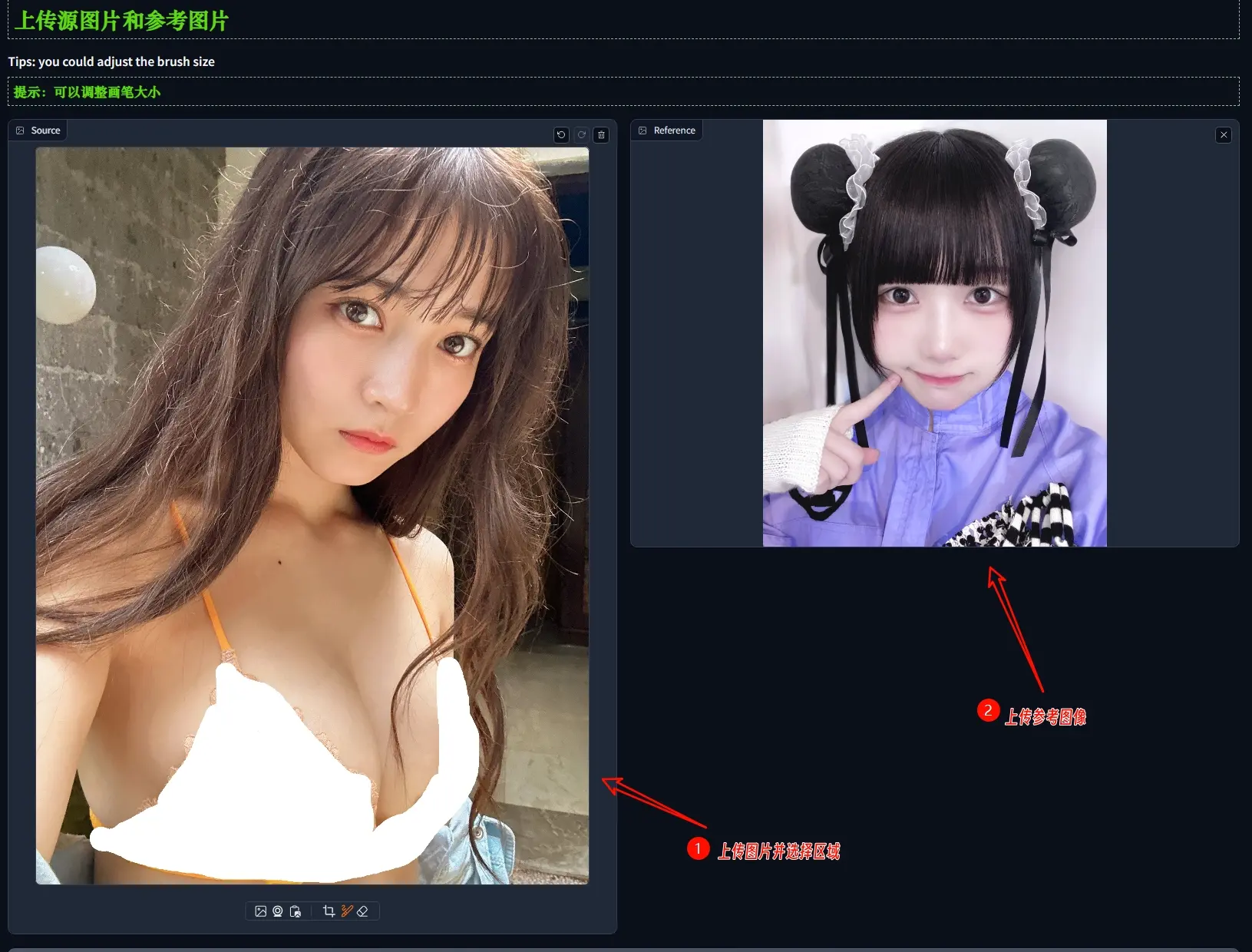
图像编辑技术MimicBrush:允许用户指定源图像中需要编辑的区域,并提供一个参考图像,来展示编辑后期望的效果香港大学、阿里巴巴集团和蚂蚁集团的研究人员推出图像编辑技术MimicBrush,它通过模仿(imitative editing)的方式,让用户能够更加方便地发挥创造力进行图像编辑。简单来说,Mimic...新技术# MimicBrush# 图像编辑2年前06370
新型多模态大语言模型INF-LLaVA:专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力厦门大学的研究人员推出新型多模态大语言模型INF-LLaVA,它专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力。在人工智能领域,处理高分辨率图像一直是一个挑战,因为这些图像包含的细...新技术# INF-LLaVA# 多模态大语言模型2年前06360
谷歌推出贪婪生长方法(Greedy Growing):用来训练大规模、高分辨率的基于像素的图像扩散模型谷歌发布论文讨论了一个非常有趣的话题:如何通过一种称为“贪婪生长”(Greedy Growing)的方法来训练大规模、高分辨率的基于像素的图像扩散模型,且无需级联超分辨率组件。简单来说,就是科学家们找...新技术# Greedy Growing# 谷歌# 贪婪生长2年前06360
英伟达推出图像生成模型家族Edify Image:能够生成高保真度的图像内容,并且具有像素级完美准确性英伟达推出图像生成模型家族Edify Image,它们能够生成高保真度的图像内容,并且具有像素级完美准确性。Edify Image利用了一系列级联的像素空间扩散模型,这些模型通过一个新颖的拉普拉斯扩散...新技术# Edify Image# 图像生成# 英伟达1年前06350
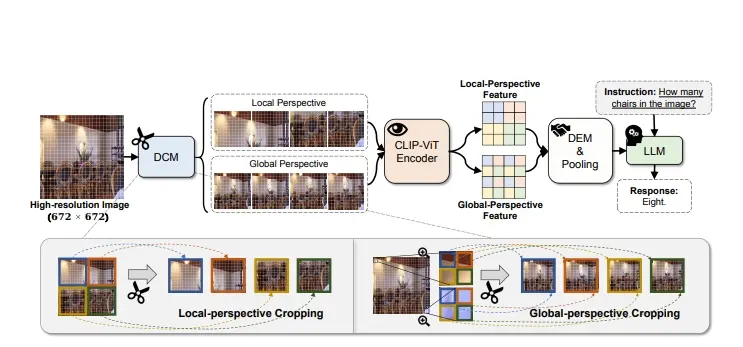
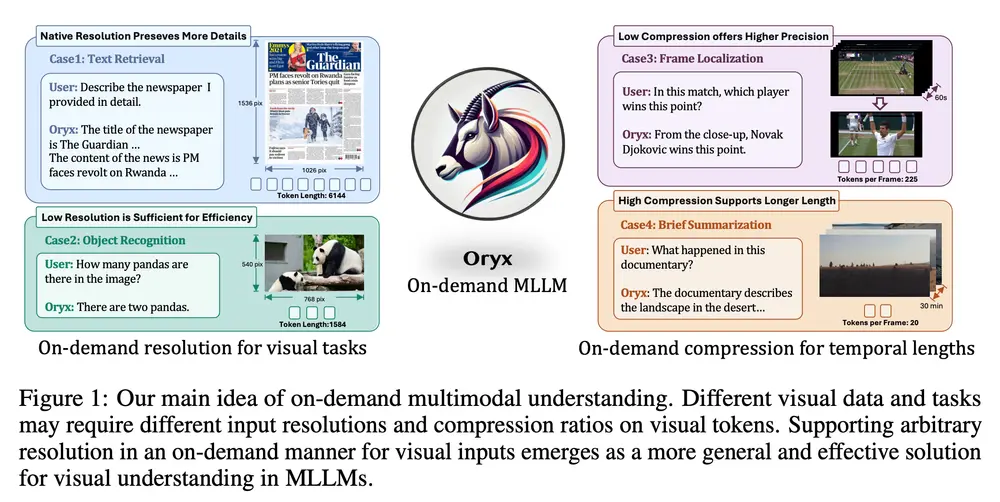
多模态大语言模型Oryx:专门设计用于理解和处理视觉数据,如图像、视频和3D场景清华大学、腾讯和南洋理工大学 S-Lab的研究人员推出多模态大语言模型Oryx,它专门设计用于理解和处理视觉数据,如图像、视频和3D场景。Oryx模型的特点是能够根据需要处理任意空间大小和时间长度的视...新技术# Oryx# 多模态大语言模型2年前06350
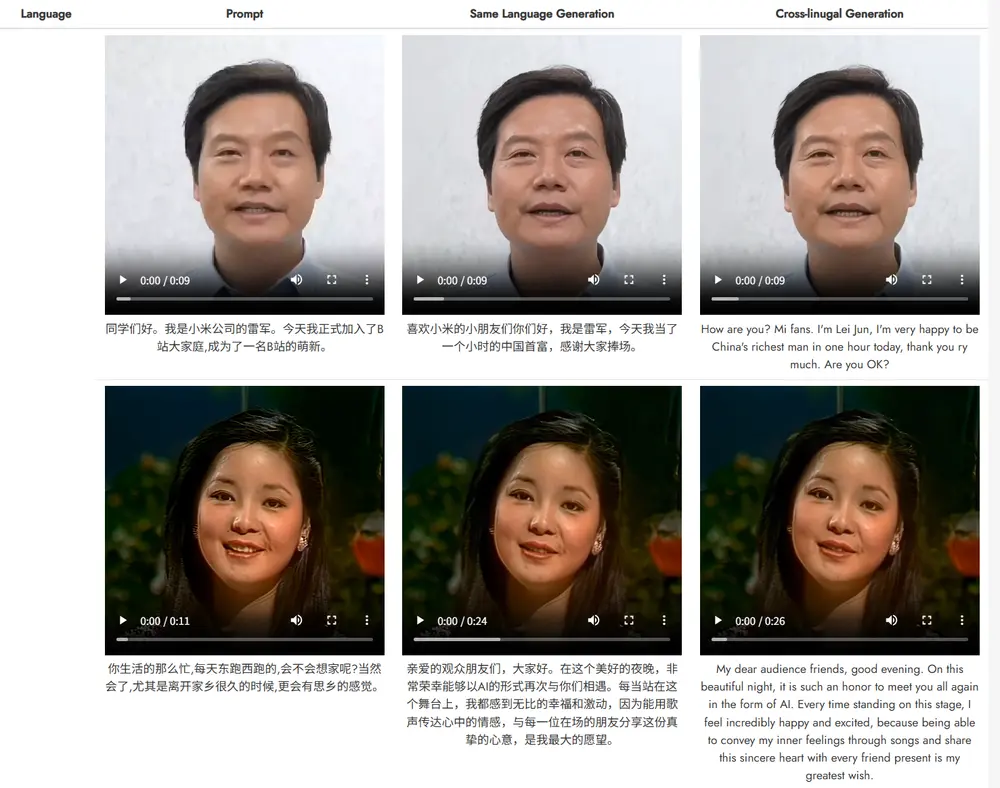
新型实时文本驱动的说话头像生成框架OmniTalker :在零样本场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格阿里通义实验室推出新型实时文本驱动的说话头像生成框架OmniTalker ,能够在零样本(zero-shot)场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格。OmniTalker ...新技术# OmniTalker# 通义实验室11个月前06330
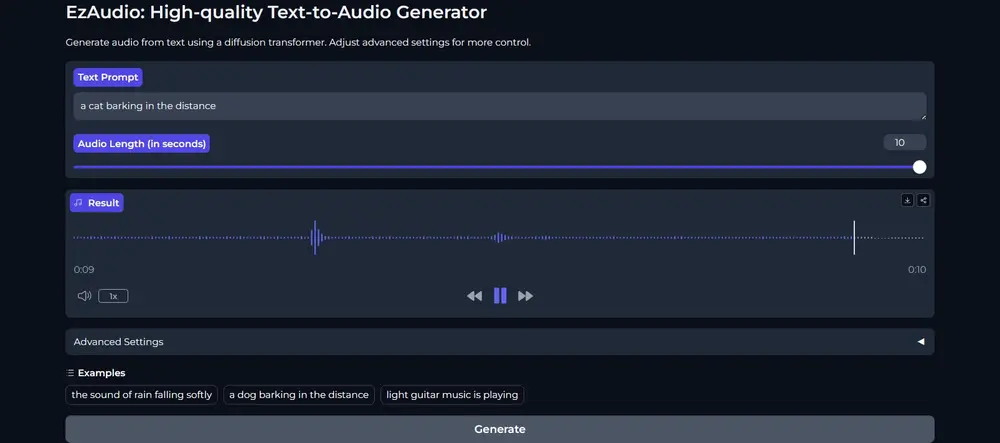
新型高品质文本音频生成器EzAudio:将文本描述转换成相应的音频内容约翰·霍普金斯大学和腾讯人工智能实验室的研究人员推出一种新型的文本到音频(Text-to-Audio,简称T2A)生成技术EzAudio,这项技术的目标是将文本描述转换成相应的音频内容,比如将“一只狗...新技术# EzAudio# 文本音频生成器2年前06320
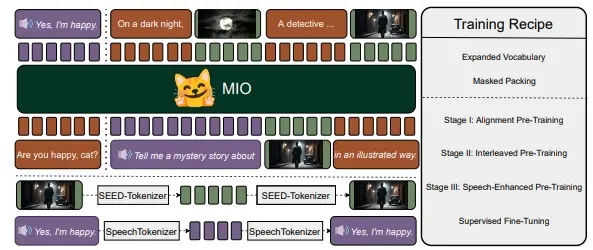
基于多模态token的新型基础模型MIO:能够以端到端、自回归的方式理解和生成语音、文本、图像和视频北京航空航天大学、01.AI、香港理工大学、AIWaves、阿尔伯塔大学、滑铁卢大学、曼彻斯特大学、中国科学院自动化研究所、北京大学和香港科技大学的研究人员推出一个基于多模态token的新型基础模型M...新技术# MIO# 多模态1年前06310
新型文本到音频生成模型Tango 2:提高音频生成的质量和与文本的匹配度新加坡科技设计大学和密歇根大学的研究人员推出新型文本到音频生成模型Tango 2,它通过直接偏好优化(Direct Preference Optimization, DPO)来提高音频生成的质量和与文...新技术# Tango 2# 文本到音频生成模型2年前06310
新型框架Uni3C:通过3D增强技术实现对视频生成中相机和人体运动的精确控制阿里达摩院、复旦大学和湖畔实验室的研究人员推出新型框架Uni3C,旨在通过3D增强技术实现对视频生成中相机和人体运动的精确控制。Uni3C通过将相机控制和人体运动控制统一到一个框架中,解决了现有方法中...新技术# Uni3C# 人体运动# 视频生成11个月前06300
RF-Solver和RF-Edit:提高校正流模型在图像和视频编辑中的反演精度基于校正流的DiT模型,如FLUX和OpenSora,在图像和视频生成领域展示了卓越的性能。然而,这些模型在反演过程中存在不准确的问题,这限制了它们在图像和视频编辑等下游任务中的有效性。为了解决这一问...新技术# RF-Edit# RF-Solver1年前06300
文本反转Textual Inversion:通过少量的图像和自然语言描述来创建新的“伪词”来指导图像生成使用文本到图像生成模型(Text-to-Image Models)来个性化地创造图像,这些模型能够根据自然语言描述生成图像,但通常难以精确地表达特定的独特概念。 项目主页 GitHub 来自特拉维夫大...新技术# Textual Inversion# 文本反转# 英伟达2年前06290