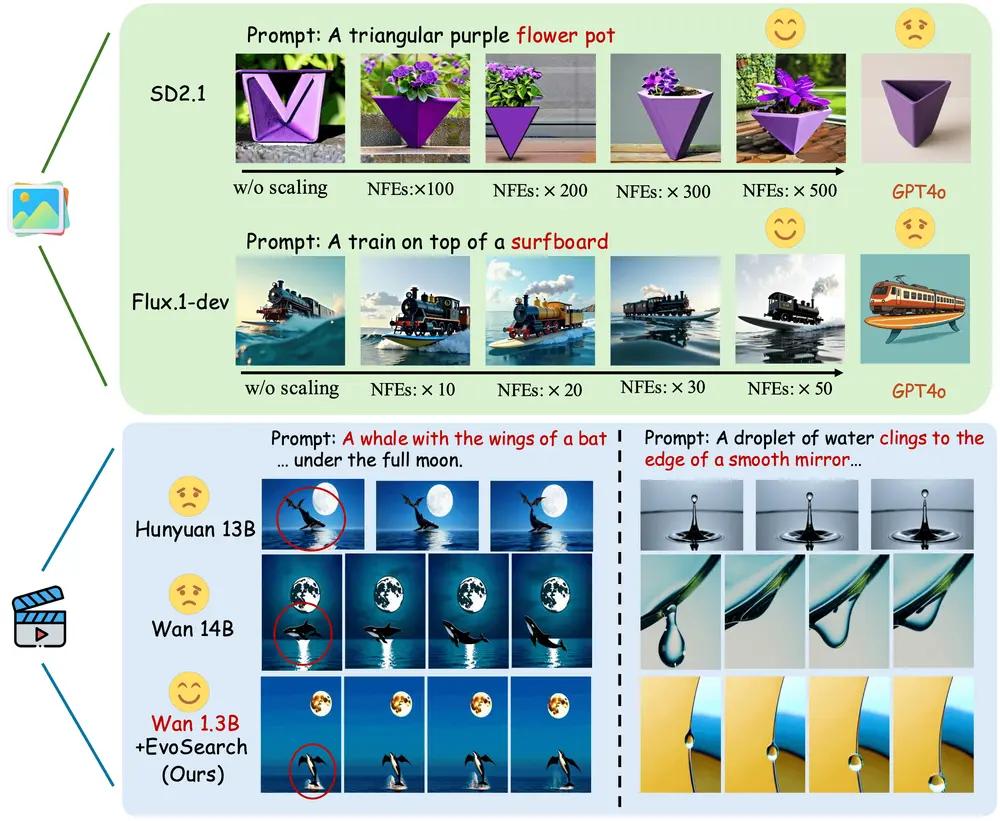
新型测试时扩展框架Evolutionary Search (EvoSearch) :通过在推理阶段分配额外计算资源来提升图像和视频生成模型的性能香港科技大学和快手的研究人员推出新型测试时扩展(Test-Time Scaling, TTS)框架Evolutionary Search (EvoSearch) ,通过在推理阶段分配额外计算资源来提升...新技术# Evolutionary Search# EvoSearch10个月前03600
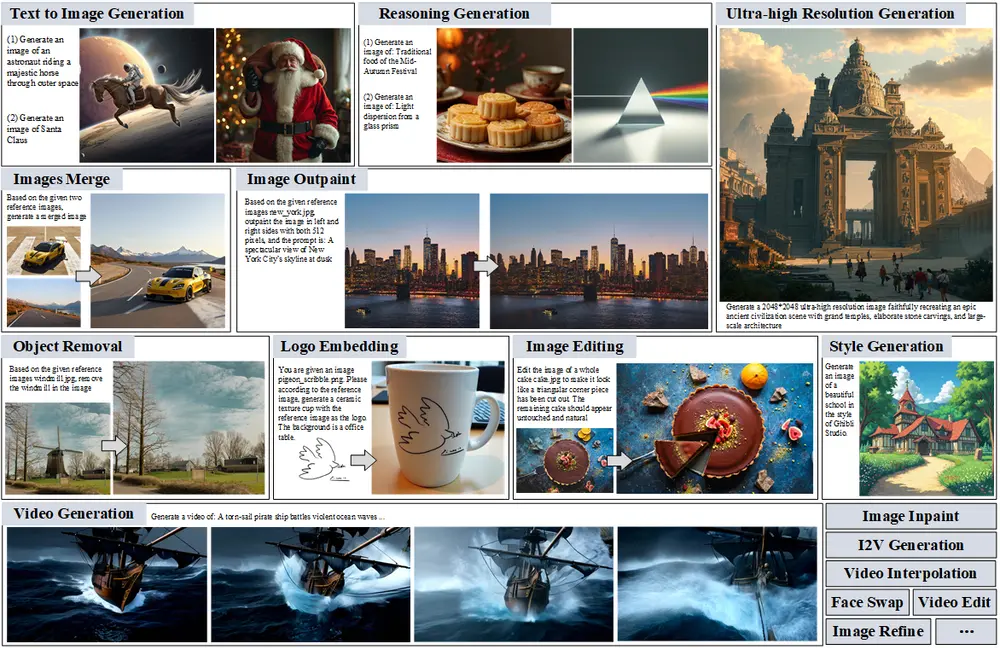
基于 ComfyUI 平台构建的协作式 AI 系统ComfyMind:打造稳定、灵活、可扩展的通用生成平台随着生成模型的飞速发展,“通用生成(General-Purpose Generation)”正成为 AI 领域的新焦点。它旨在通过一个统一系统,支持图像、视频、文本等多种模态任务的生成与编辑,为复杂创...新技术# ComfyMind# 图像生成# 视频生成10个月前03230
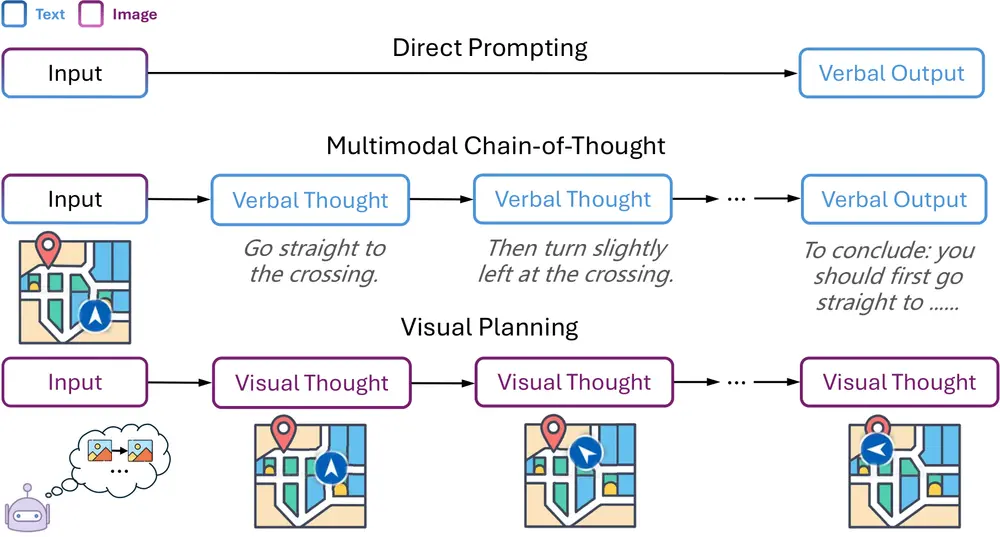
纯视觉推理新范式Visual Planning:通过纯视觉表征进行规划,无需依赖文本剑桥大学语言技术实验室、伦敦大学学院和谷歌的研究人员一种名为“Visual Planning(视觉规划)”的新范式,通过纯视觉表征进行规划,无需依赖文本。该范式受到认知科学中双重编码理论的启发,主张人...新技术# Visual Planning# 视觉推理10个月前02660
UniVG-R1:通过推理引导的多模态大语言模型实现通用视觉定位传统视觉定位方法主要关注单图像场景,依赖于简单文本引用。然而,在现实世界中,处理隐含和复杂的指令,尤其是在涉及多图像的情况下,是一个重大挑战,主要原因是缺乏跨多模态上下文的高级推理能力。 项目主页:h...新技术# UniVG-R1# 多模态大语言模型# 视觉定位10个月前02400
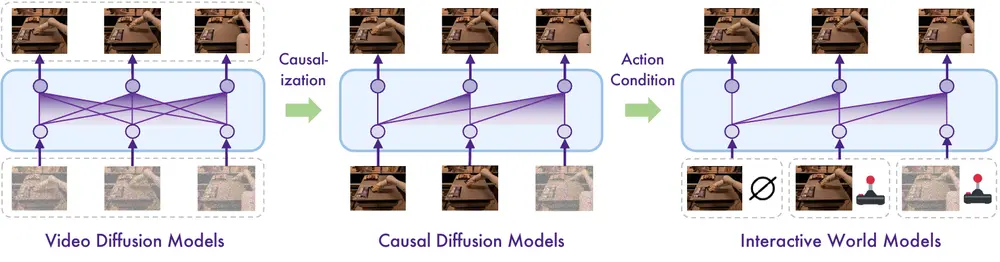
Vid2World:将预训练的视频扩散模型转化为交互式世界模型清华大学软件学院、清华大学交叉信息研究所和重庆大学计算机学院的研究人员推出 Vid2World,将预训练的视频扩散模型(Video Diffusion Models)转化为交互式世界模型(Intera...新技术# Vid2World# 交互式世界模型# 视频扩散模型10个月前03070
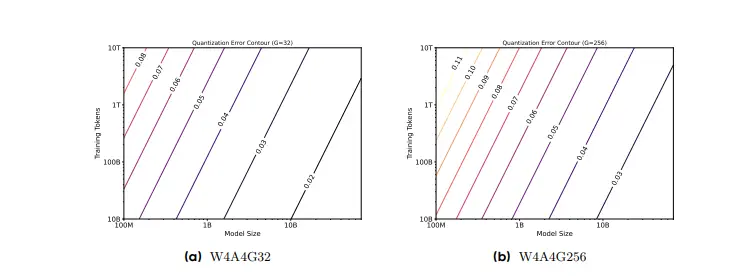
针对大语言模型(LLMs)的量化感知训练(QAT)的统一缩放定律香港大学和字节跳动的研究人员介绍了一种针对大语言模型(LLMs)的量化感知训练(QAT)的统一缩放定律。量化是一种减少模型权重和激活精度的方法,以降低内存使用和计算成本。尽管现有的量化方法在中等精度...新技术# 大语言模型# 量化感知训练10个月前02810
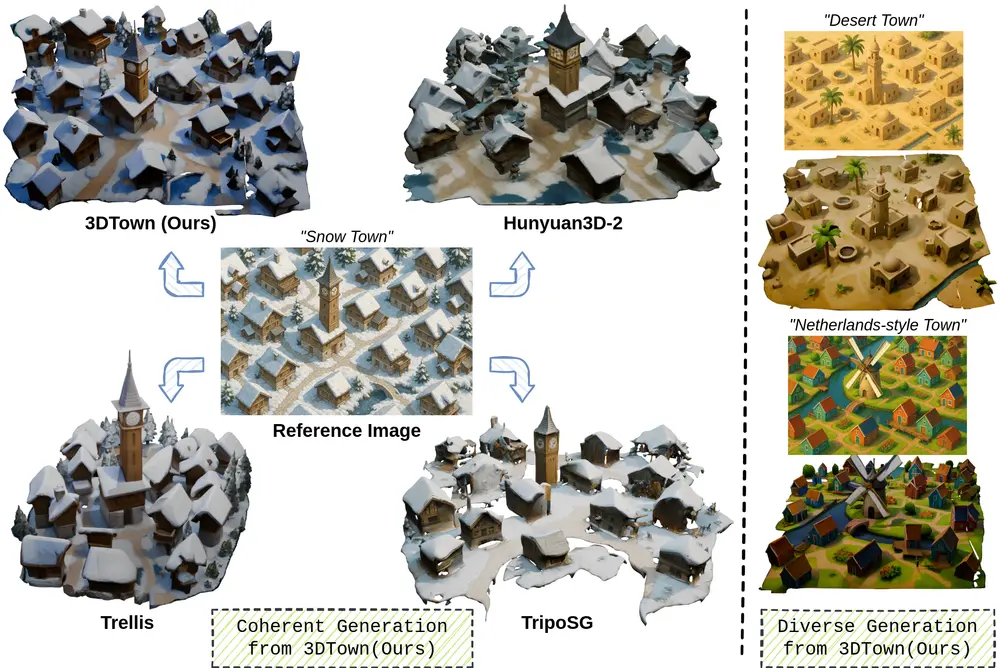
3DTown框架:从单张俯视图像生成逼真且连贯的三维(3D)场景加州大学圣克鲁兹分校、哥伦比亚大学和Cybever AI的研究人员推出 3DTown框架,从单张俯视图像生成逼真且连贯的三维(3D)场景。传统的详细3D场景获取方法通常需要昂贵的设备、多视角数据或人工...新技术# 3DTown# 3D场景10个月前01910
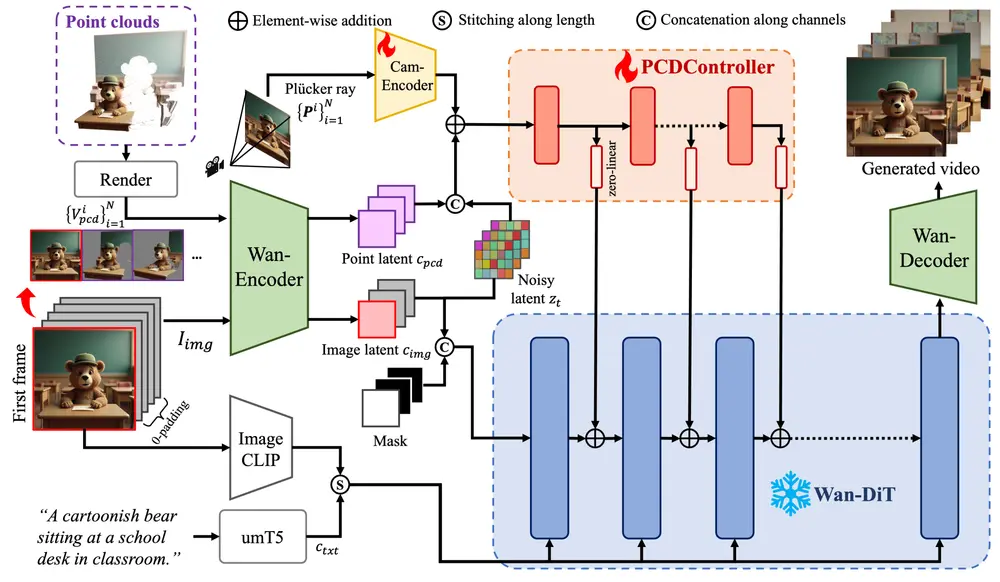
视频生成控制框架Uni3C:通过统一的3D增强方法精确控制视频生成中的相机和人物动作阿里巴巴达摩院、复旦大学和湖畔实验室的研究人员推出Uni3C框架,通过统一的3D增强方法精确控制视频生成中的相机和人物动作。 项目主页:https://ewrfcas.github.io/Uni3C ...新技术# Uni3C# 视频生成10个月前03880
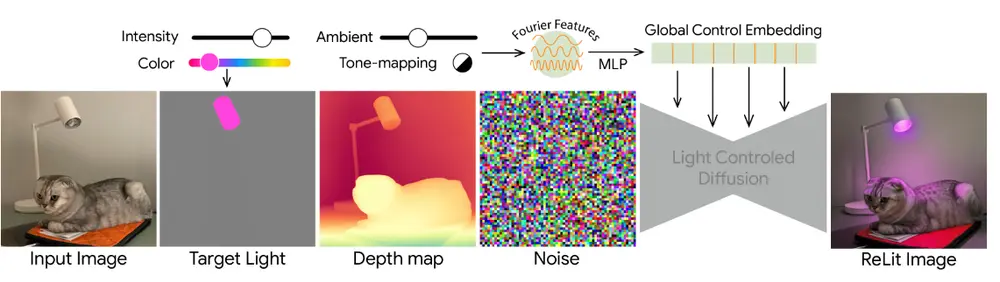
谷歌推出LightLab:基于扩散模型的AI工具,实现单张图像中的精细光照控制在图像后期处理中,操控光照条件一直是一个复杂且具有挑战性的任务。传统方法依赖于3D图形技术,通过多次捕获重建场景的几何结构和属性,并利用物理光照模型模拟新的光照效果。尽管这些技术提供了对光源的明确控制...新技术# LightLab# 光照控制# 谷歌10个月前03450
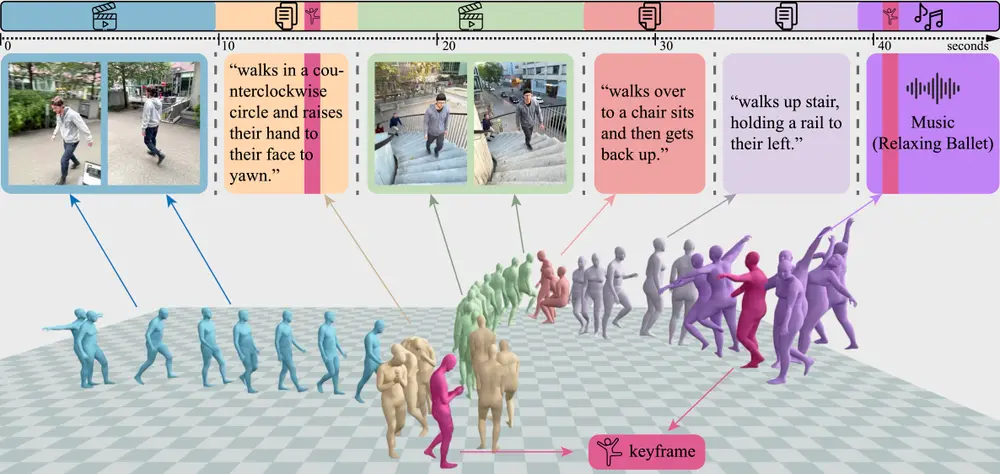
英伟达发布人体运动的通用模型Genmo:实现从视频、2D 关键点、文本描述、音乐和3D 关键帧等多种条件信号中生成和估计高质量的人类运动英伟达研究团队开发的统一框架 GENMO,用于人类运动建模。GENMO 的目标是将人类运动估计(estimation)和生成(generation)任务整合到一个框架中,从而实现从视频、2D 关键点...新技术# Genmo# 人体运动# 英伟达10个月前02870
西湖大学和浙江大学的研究人员推出统一框架UCGM:用于训练、采样和理解连续生成模型西湖大学和浙江大学的研究人员推出统一框架UCGM,用于训练、采样和理解连续生成模型。UCGM通过一个统一的训练目标和采样算法,将多步生成模型(如扩散模型和流匹配模型)与少步生成模型(如一致性模型)结合...新技术# UCGM# 统一框架10个月前03060
新型参考式人类图像补全框架CompleteMe:通过参考图像来补全被遮挡或缺失的人类图像区域,同时保留独特的细节信息加州大学默塞德分校和Adobe Research的研究人员推出新型参考式人类图像补全框架CompleteMe,旨在通过参考图像来补全被遮挡或缺失的人类图像区域,同时保留独特的细节信息,如特定的服装图案...新技术# CompleteMe10个月前04570