加州大学默塞德分校和Adobe Research的研究人员推出新型参考式人类图像补全框架CompleteMe,旨在通过参考图像来补全被遮挡或缺失的人类图像区域,同时保留独特的细节信息,如特定的服装图案、配饰或纹身等。
例如,有一张人物照片,其中部分身体被遮挡(例如,人物的上半身被遮住了),而另一张参考图像显示了同一个人物的完整上半身。通过 CompleteMe,可以利用参考图像中的信息来补全被遮挡部分,生成一张完整且细节一致的图像。

主要功能
- 参考式图像补全:通过参考图像来补全被遮挡或缺失的人类图像区域。
- 细节保留:能够保留参考图像中的独特细节,如服装图案、配饰、纹身等。
- 语义一致性:确保补全后的图像在语义上与参考图像保持一致。
主要特点
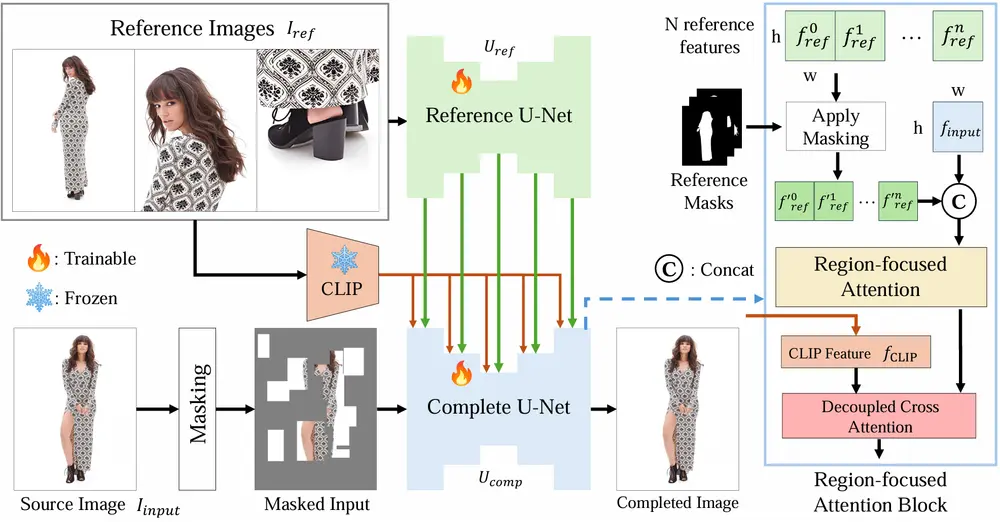
- 双U-Net架构:采用参考U-Net(Reference U-Net)和补全U-Net(Complete U-Net)的双U-Net架构,分别处理参考图像和补全任务。
- 区域聚焦注意力(RFA)模块:通过显式引导模型关注参考图像中的相关区域,显著提升细节捕捉和语义对应能力。
- 灵活的输入方式:支持单张参考图像或多张参考图像,还可以结合文本提示进行补全。
工作原理
- 参考特征编码:参考U-Net从多张参考图像中提取详细的空间特征,并通过CLIP模型提取全局语义特征。
- 区域聚焦注意力(RFA)模块:将参考特征与输入图像特征结合,通过区域聚焦注意力机制,显式地将注意力集中在参考图像的相关区域,建立精确的对应关系。
- 补全过程:补全U-Net将处理后的参考特征与输入图像特征融合,生成补全后的图像。
测试结果
- 定量评估:在自建的基准数据集上,CompleteMe在多个评估指标上均优于现有方法,例如:
- CLIP-I(图像相似度):97.18
- DINO(相似度):96.29
- DreamSim(感知相似度):0.0419
- LPIPS(感知差异):0.0588
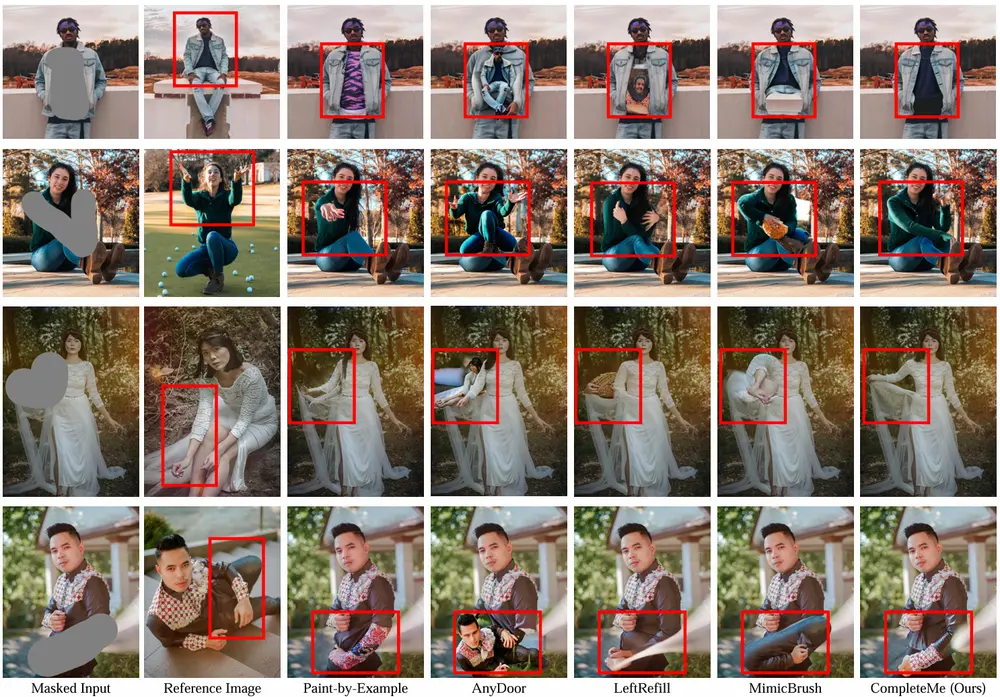
- 定性评估:通过与非参考方法(如LOHC、BrushNet)和参考方法(如Paint-by-Example、AnyDoor、LeftRefill、MimicBrush)的对比,CompleteMe能够更准确地保留参考图像中的细节信息。
- 用户研究:在用户研究中,CompleteMe在“质量”和“身份一致性”两个维度上均获得了显著更高的用户偏好。
应用场景
- 照片编辑:修复被遮挡或损坏的人物照片。
- 虚拟试穿:在虚拟试穿应用中,补全被遮挡的服装部分。
- 动画制作:在动画制作中,补全角色的缺失部分,保持动画的连贯性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











