
加州大学圣克鲁兹分校、哥伦比亚大学和Cybever AI的研究人员推出 3DTown框架,从单张俯视图像生成逼真且连贯的三维(3D)场景。传统的详细3D场景获取方法通常需要昂贵的设备、多视角数据或人工建模,而3DTown提供了一种轻量级的替代方案,通过单张俯视图像生成复杂的3D场景,这在实际应用中具有重要意义。
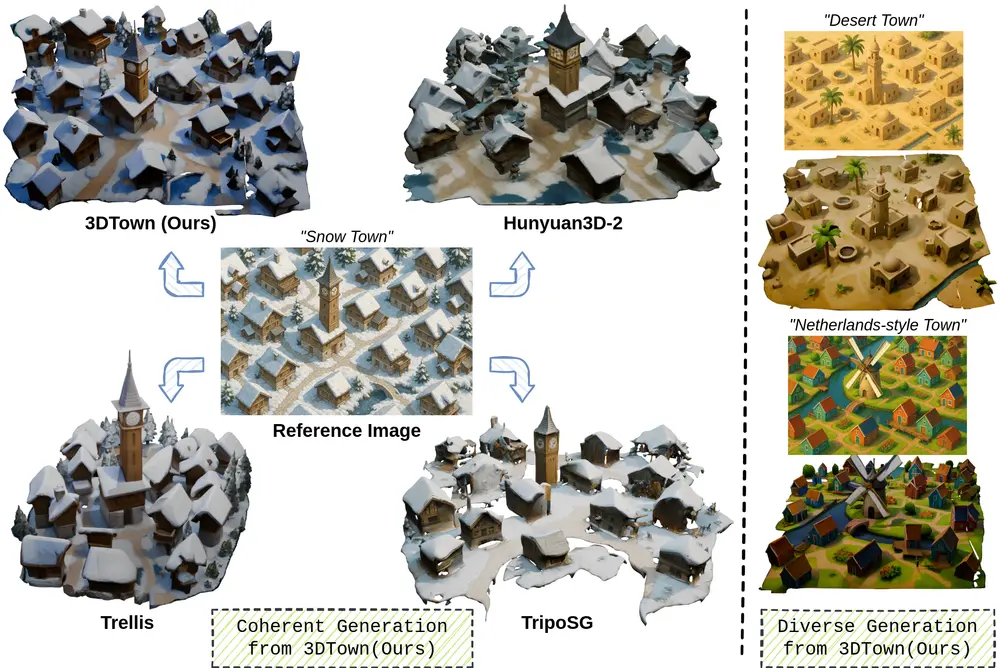
例如,给定一张俯视图,3DTown能够生成具有几何、纹理和布局一致性的3D城镇场景,相比其他图像到3D生成模型具有显著优势。
主要功能
- 3D场景生成:从单张俯视图像生成高分辨率、高质量的3D场景。
- 多风格支持:能够生成多种风格的3D场景,如“雪村”、“沙漠城镇”等。
- 无需3D训练数据:无需3D监督或微调,直接利用预训练的2D到3D生成器。
主要特点
- 区域化生成:将场景分解为重叠区域,独立生成每个区域,提高局部对齐和分辨率。
- 空间感知3D修复:通过掩码修正流(rectified flow)填充缺失几何结构,同时保持结构连续性。
- 无需训练:整个框架无需额外训练或微调,直接利用预训练模型进行零样本(zero-shot)场景资产合成。
工作原理
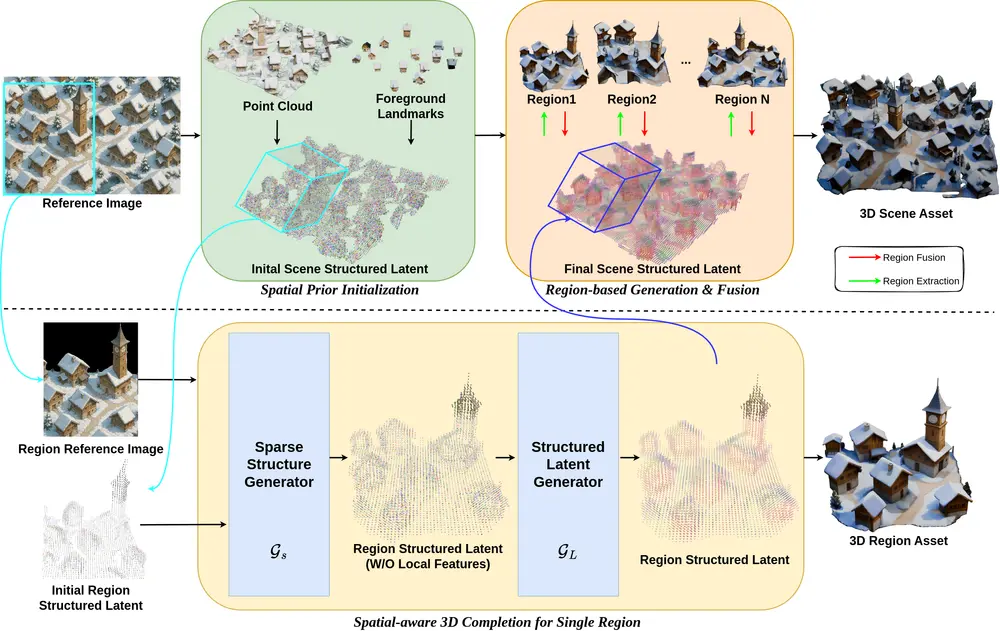
- 结构化潜在表示:使用结构化潜在表示来构建场景,其中每个活动体素的位置和相关潜在特征向量共同定义了场景的结构和外观。
- 空间先验初始化:通过单目深度估计和地标检测估计粗略的3D结构,形成空间先验,为场景生成提供一致的结构基础。
- 区域化生成与融合:将场景划分为重叠区域,对每个区域进行独立生成,并通过掩码修正流进行空间感知的3D修复,最后将更新后的区域潜在表示融合到场景潜在表示中,确保全局一致性。
- 最终场景解码:使用预训练的对象解码器从完整的场景结构化潜在表示中解码出3D场景资产。
测试结果
- 定量分析:在几何质量、布局连贯性和纹理保真度方面,3DTown显著优于现有的几种图像到3D生成方法,如Trellis、Hunyuan3D-2和TripoSG。例如,在人类偏好测试中,3DTown在几何质量上的胜率比Trellis高出37个百分点(68.5% vs. 31.5%),在布局连贯性上比Hunyuan3D-2高出55个百分点(87.9% vs. 12.1%)。
- 定性分析:3DTown生成的场景具有清晰的结构、连贯的布局和逼真的表面细节,与参考俯视图像高度一致。相比之下,Trellis生成的结构过于简化且缺乏细节,Hunyuan3D-2存在布局失真和几何幻觉问题,TripoSG则经常引入重复对象并忽略参考图像中的布局证据。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











