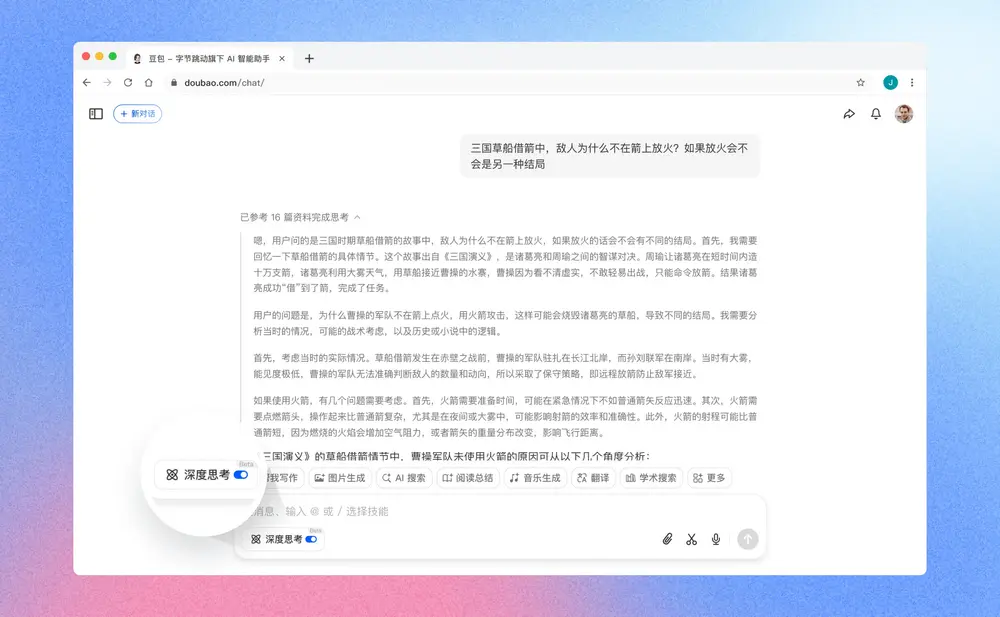
字节跳动旗下AI助手豆包上线「深度思考」推理模式在2025年3月5日,字节跳动旗下的AI助手豆包宣布正式上线了名为「深度思考」的推理模式。这一更新全面覆盖了问答、搜索、写作和阅读等应用场景,旨在为用户提供更加透明和详细的AI决策过程展示。用户只需简...早报# 字节跳动# 推理模式# 深度思考1年前03800
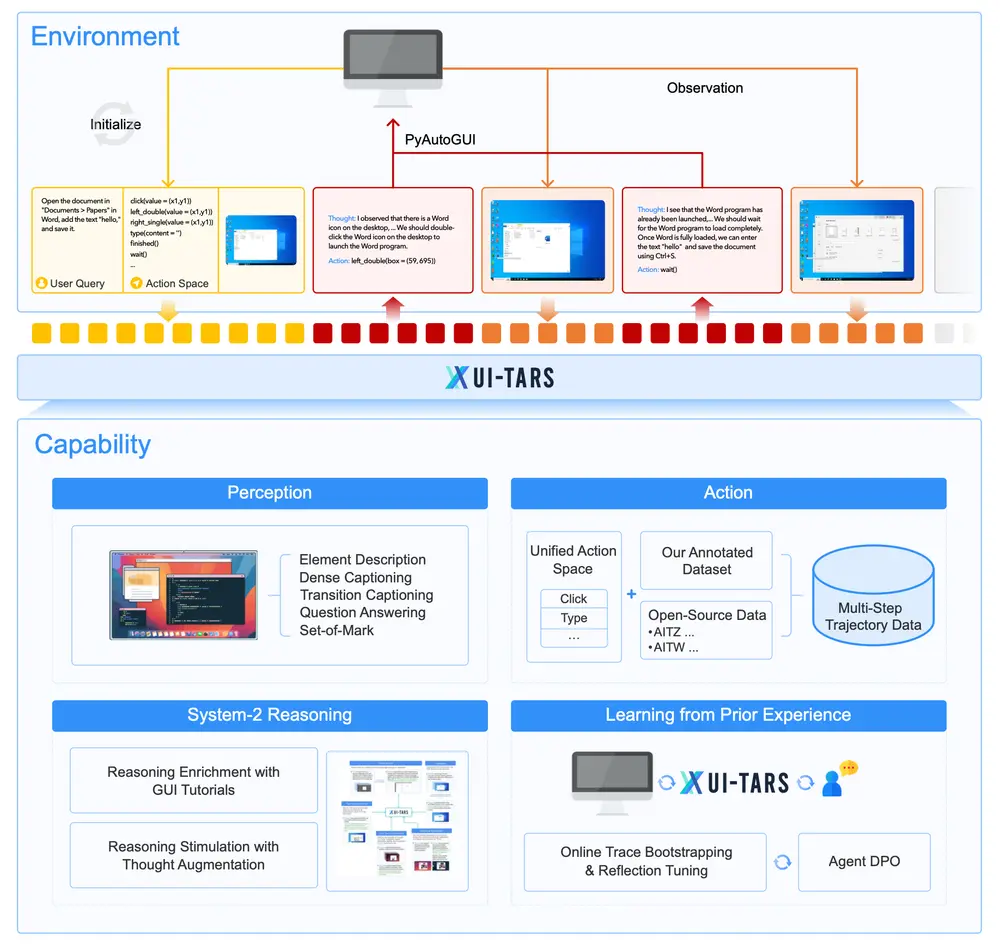
新型自动化 GUI交互模型 UI-TARS:能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠标操作)字节跳动与清华大学的研究人员推出新型自动化 GUI(图形用户界面)交互模型 UI-TARS,它是一种原生的 GUI 代理模型,能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠...多模态模型# UI-TARS# 字节跳动12个月前03800
字节跳动发布OneReward 框架:用单一奖励模型革新多任务图像编辑在图像生成领域,AI 已经能完成许多复杂操作:补全残缺画面、扩展图像边界、移除干扰物体,甚至在图中添加可读文本。但这些任务通常由不同模型分别处理——每个任务有自己的训练流程、评估标准和奖励机制。 这带...图像模型# FLUX.1-Fill-dev-OneReward# OneReward# 字节跳动7个月前03480
字节跳动推出具备长期记忆的多模态智能体 M3-Agent字节跳动 Seed 团队推出新型多模态智能体框架M3-Agent ,首次实现了以实体为中心、支持长期记忆积累的自主推理能力。 项目主页:https://m3-agent.github.io GitHu...多模态模型# M3-Agent# 多模态智能体# 字节跳动8个月前03440
字节跳动Pico团队推出新型框架EX-4D:从单目视频生成高质量的极端视角 4D 视频字节跳动Pico团队推出新型框架EX-4D,旨在从单目视频生成高质量的极端视角 4D 视频。该框架通过深度防水网格(Depth Watertight Mesh, DW-Mesh)表示法,有效处理边界遮...新技术# EX-4D# 字节跳动9个月前03440
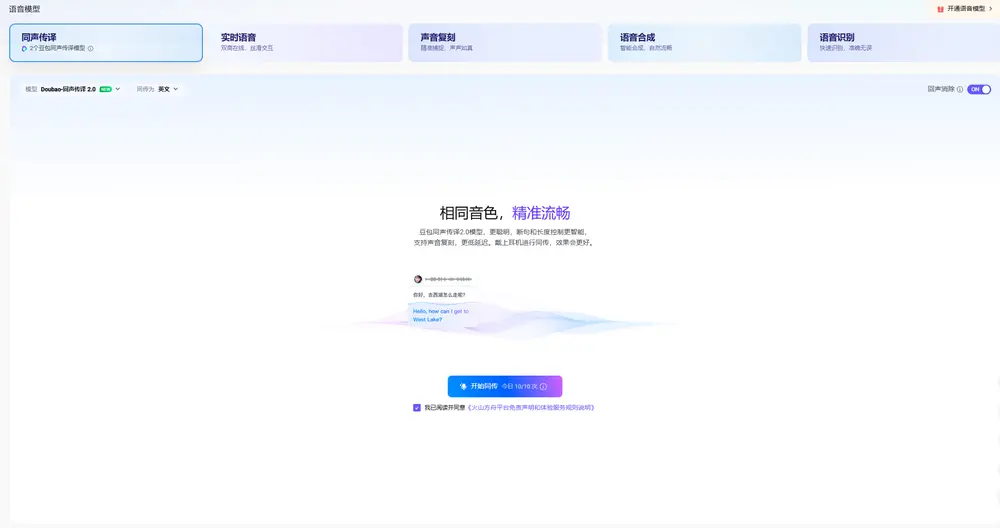
字节跳动发布 Seed LiveInterpret 2.0:首个中英同传延迟与准确率接近人类水平的端到端语音翻译系统在跨语言实时沟通的长期挑战中,机器能否真正替代人类同声传译?字节跳动 Seed 团队给出了迄今为止最接近“是”的答案。 今日,字节跳动正式发布 Seed LiveInterpret 2.0 —— 一款...语音模型# Seed LiveInterpret 2.0# 同声传译模型# 字节跳动8个月前03370
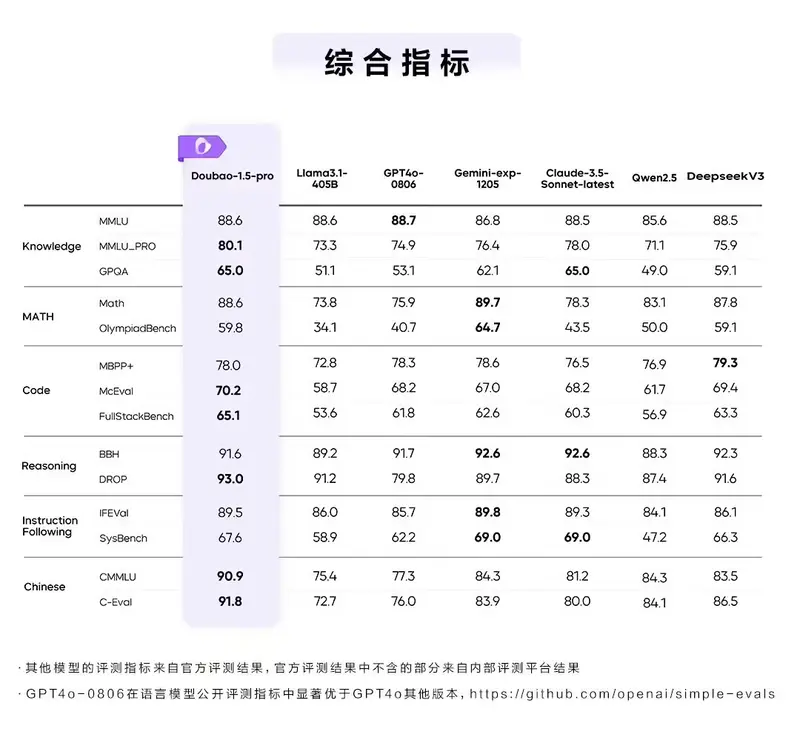
字节跳动发布豆包大模型 1.5 Pro,性能超越 GPT-4o 和 Claude 3.5 Sonnet字节跳动今日正式发布了其最新的豆包大模型 1.5 Pro(Doubao-1.5-pro),该模型在多个测评基准上,包括知识、代码、推理和中文等方面,展现了优于 GPT-4o 和 Claude 3.5 ...早报# 字节跳动# 豆包大模型 1.5 Pro1年前03270
Self-Forcing++:一种无需长视频训练即可生成高质量长视频的新方法近年来,扩散模型在图像和短片视频生成方面取得了突破性进展。然而,当扩展到长视频生成(如数十秒甚至数分钟)时,现有方法普遍面临一个核心问题:质量随长度增加而显著下降。 这主要源于两个限制: 计算成本高...新技术# Self Forcing# 字节跳动6个月前03260
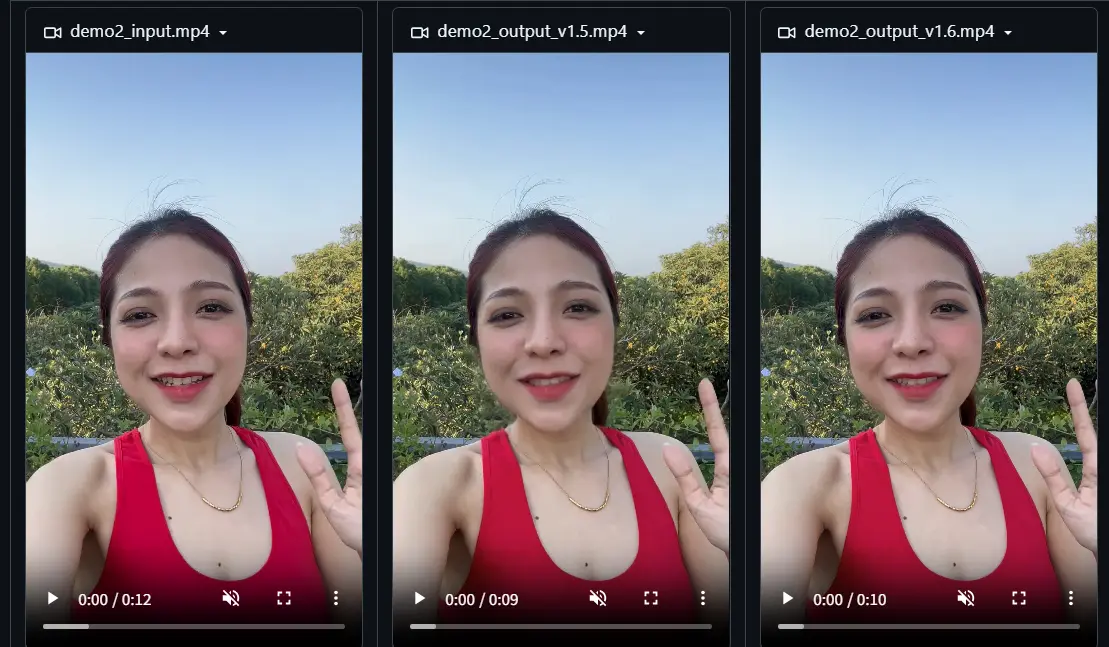
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动10个月前03260
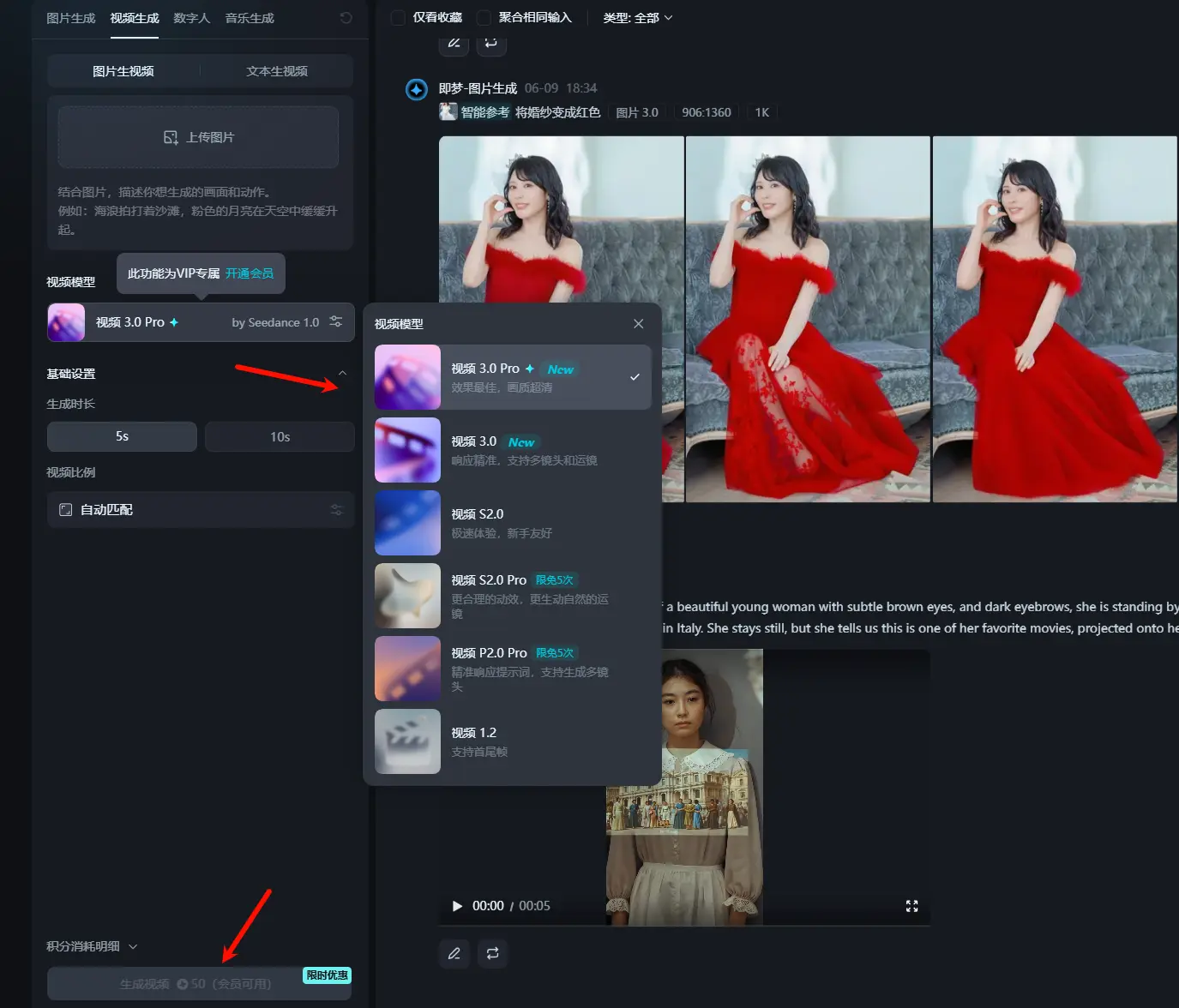
字节跳动推出视频生成模型 Seedance 1.0,视频生成迈入“电影级”体验字节跳动正式发布了其最新的视频生成模型 Seedance 1.0。该模型已集成在字节旗下 AI 创作平台“即梦”中,并以“视频生成3.0 Pro”版本面向用户开放(需会员权限使用)。目前,每生成一个5...视频模型# Seedance 1.0# 字节跳动# 视频生成模型10个月前03180
字节跳动发布统一加速多模态理解与生成的新框架Hyper-Bagel随着多模态大模型在图文理解、文本到图像生成、图像编辑等任务中表现日益强大,其高昂的推理成本也逐渐成为落地瓶颈。传统的自回归解码与扩散去噪过程需要大量迭代计算,在长上下文或多轮交互场景下响应迟缓。 为此...图像模型# Hyper-Bagel# 字节跳动6个月前03140
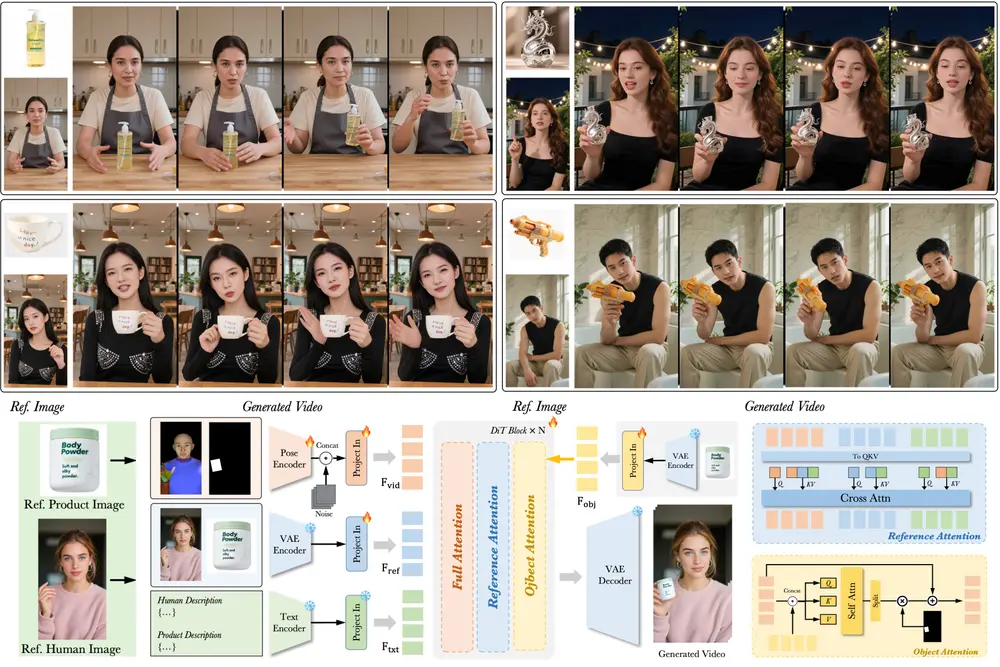
DreamActor-H1:字节跳动推出高保真人类-产品演示视频生成框架在电商广告、虚拟试穿、交互式媒体等场景中,如何高效生成高质量的人类-产品演示视频,一直是视觉生成领域的重要挑战。 近日,字节跳动 AI 实验室提出了一种全新的视频生成框架——DreamActor-H1...新技术# DreamActor-H1# 字节跳动9个月前03110