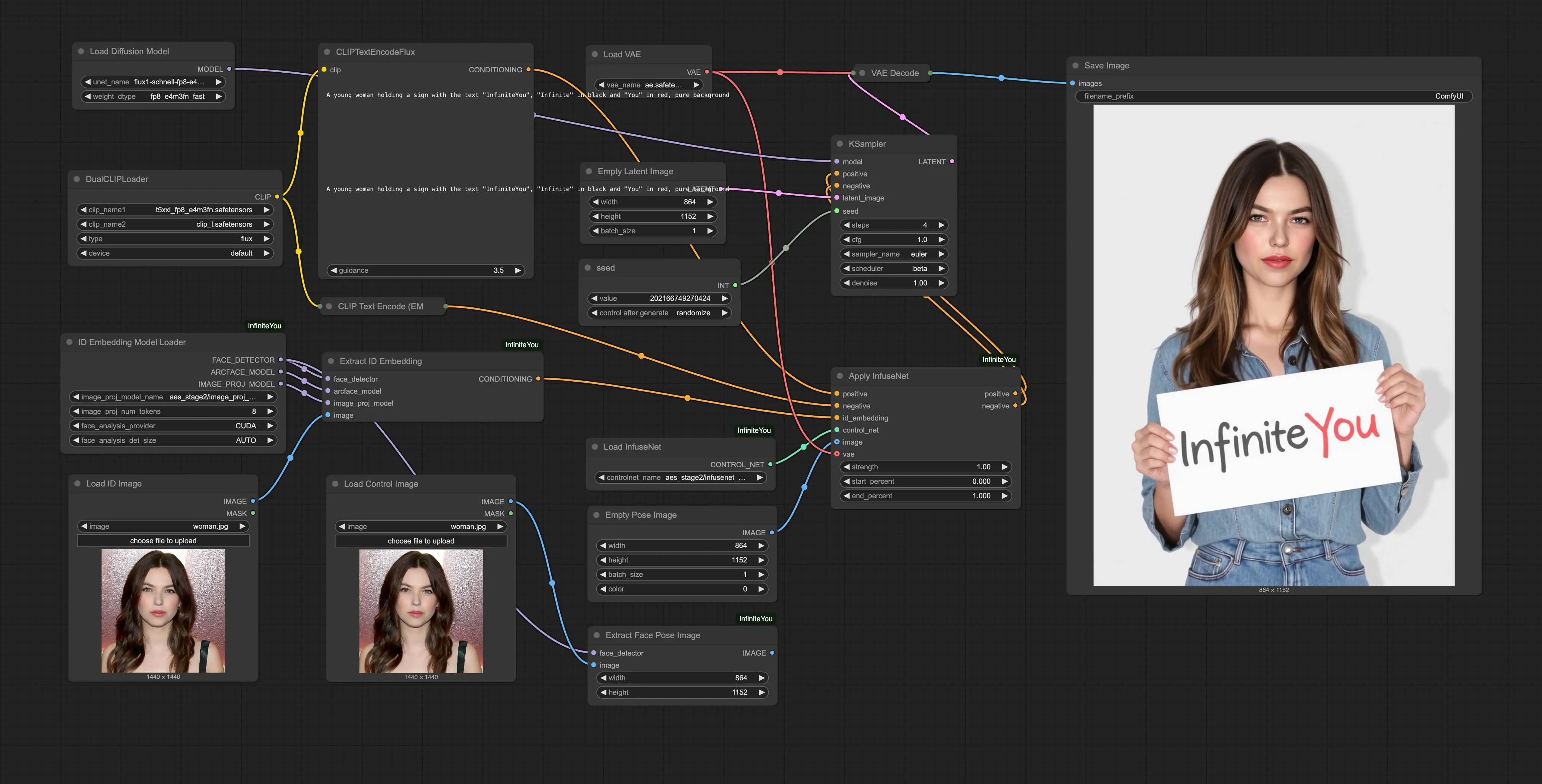
字节跳动发布 InfiniteYou官方 ComfyUI 插件ComfyUI_InfiniteYou字节跳动发布了其基于FLUX的身份保持模型InfiniteYou 的官方 ComfyUI 原生节点 —— ComfyUI_InfiniteYou,为开发者和创作者提供了更便捷的集成方式,支持在 Com...插件# ComfyUI_InfiniteYou# InfiniteYou# 字节跳动9个月前04460
字节跳动发布通用图像编辑模型SeedEdit:已经在豆包PC端及即梦网页端开启测试11月11日,字节在豆包大模型团队官网上公布最新通用图像编辑模型SeedEdit。SeedEdit支持一句话轻松改图,包括修图、换装、美化、转化风格、在指定区域添加删除元素等各类编辑操作,通过简单的自...工具# SeedEdit# 即梦# 字节跳动1年前04230
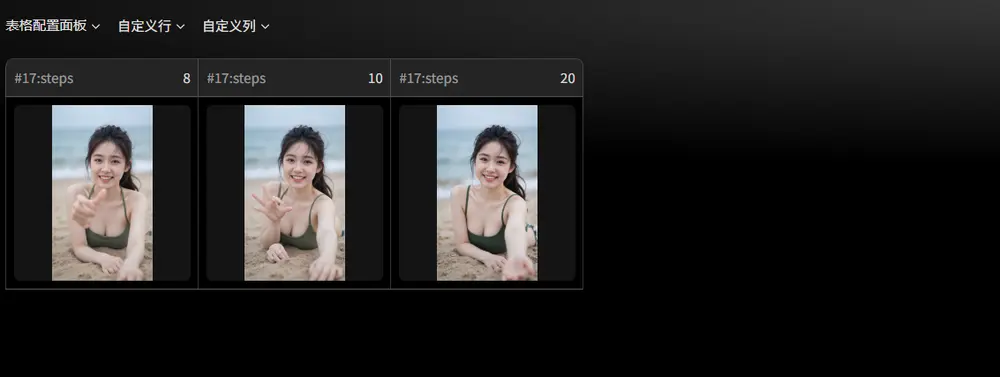
字节跳动智能创作团队推出ComfyUI批量处理扩展插件ComfyUI-Lumi-Batcher在ComfyUI进行图像、视频创作过程中,你是否也遇到过这些令人抓狂的场景? 😭 模型选择困难症晚期:反复替换模型手动跑图,3 小时都试不出最佳风格 😭 参数调试逼疯设计师:手动调整尺寸/权重/采样步...插件# ComfyUI-Lumi-Batcher# 字节跳动# 批量处理9个月前04190
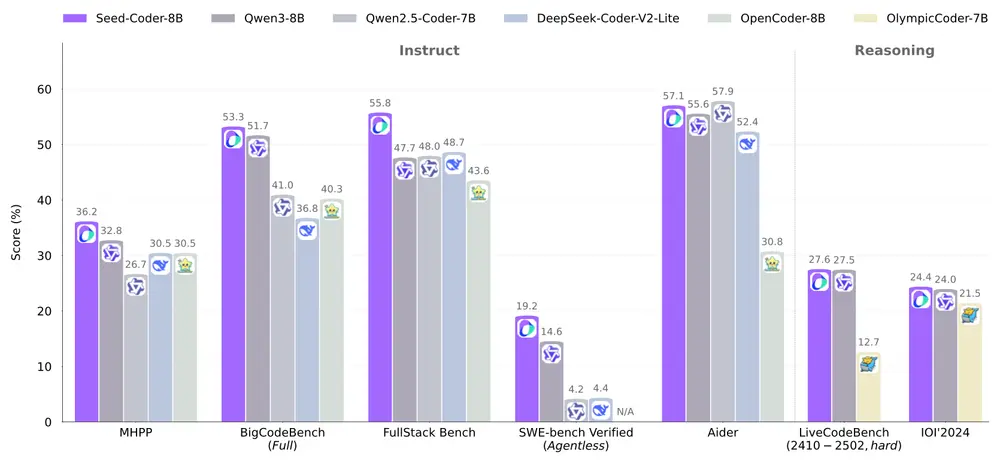
字节跳动推出Seed-Coder:轻量级开源代码大模型,性能媲美更大规模模型字节跳动近日发布了全新的开源代码大语言模型(LLM)系列——Seed-Coder,标志着其在开源大语言模型生态系统中的首次重要贡献。这一系列模型以轻量化和高性能为核心特点,包括基础模型、指令模型和推理...大语言模型# Seed-Coder# 代码大模型# 字节跳动11个月前04150
字节跳动发布 Seedream 4.0:首次支持多模态生图,同一模型实现 文生图、图像编辑、组图生成字节跳动正式推出 Seedream 4.0(即梦图片4.0),新一代图像创作模型。该模型在前代 Seedream 3.0 和 SeedEdit 3.0 的基础上,全面增强逻辑理解与多模态推理能力,首次...图像模型# Seedream 4.0# 即梦图片4.0# 字节跳动7个月前04120
字节跳动开源UMO:统一多身份优化框架,让AI准确“认出”每个人在图像定制领域,个性化生成已逐渐从“一个人一个风格”迈向“多人协同场景”的复杂需求。然而,当一张图中需要同时呈现多个真实人物时,模型常常出现“张冠李戴”——面部特征混淆、身份错位,导致输出失真。这不仅...图像模型# UMO# 字节跳动7个月前04080
字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新:聊天与构建器的融合、上下文能力的拓展等字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新,这些改进将极大地提升开发体验,重塑 AI 开发的未来。 1. 聊天与构建器的融合 Trae v1.3.0版本将聊天(Chat)和构建器(Bui...早报# Trae# 字节跳动11个月前04070
字节跳动推出 X-UniMotion:首个能精准复刻手部动作的视频生成模型字节跳动研究团队发布了一项令人瞩目的视频生成新成果 —— X-UniMotion。该模型能够基于参考人物和驱动动作视频,实现对全身动作(尤其是复杂手部动作)的高精度复现,几乎看不出瑕疵,尤其在手部细节...新技术# X-UniMotion# 字节跳动9个月前04050
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动9个月前04040
字节跳动推出人像动画技术X-Portrait 2:创建富有表现力和逼真的角色动画和视频素材人像动画技术提供了一种超低成本且高效的方式,用于创建富有表现力和逼真的角色动画和视频素材。用户只需提供一个静态人像图像和一个驱动表演视频,模型就可以使用这些输入生成视频,通过将驱动表情转移到人像中的主...新技术# X-Portrait 2# 人像动画# 字节跳动1年前03960
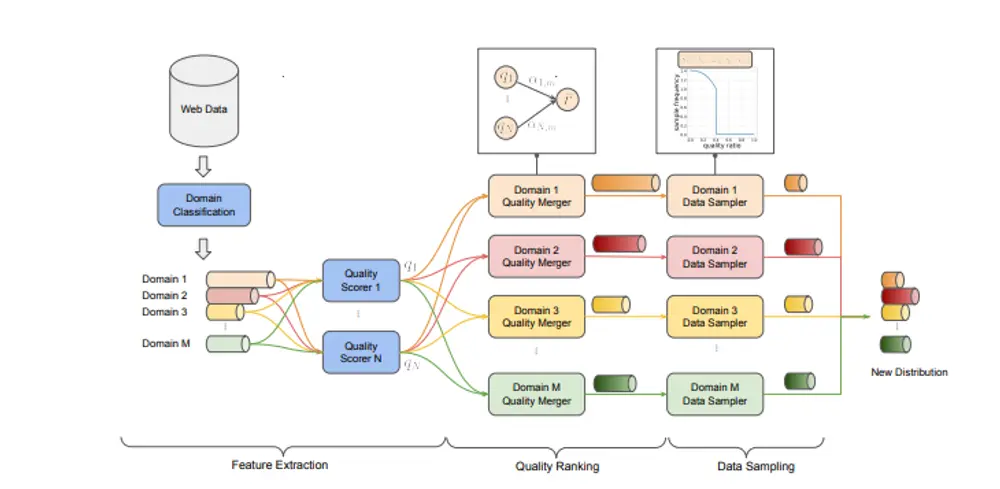
字节跳动推出统一优化数据质量与多样性的LLM预训练框架QuaDMix大语言模型(LLM)的性能和泛化能力在很大程度上依赖于其预训练数据的质量和多样性。然而,传统的数据整理方法往往将质量和多样性视为独立的目标,先进行质量过滤,再平衡领域分布。这种顺序优化忽略了两者之间的...新技术# QuaDMix# 字节跳动11个月前03890
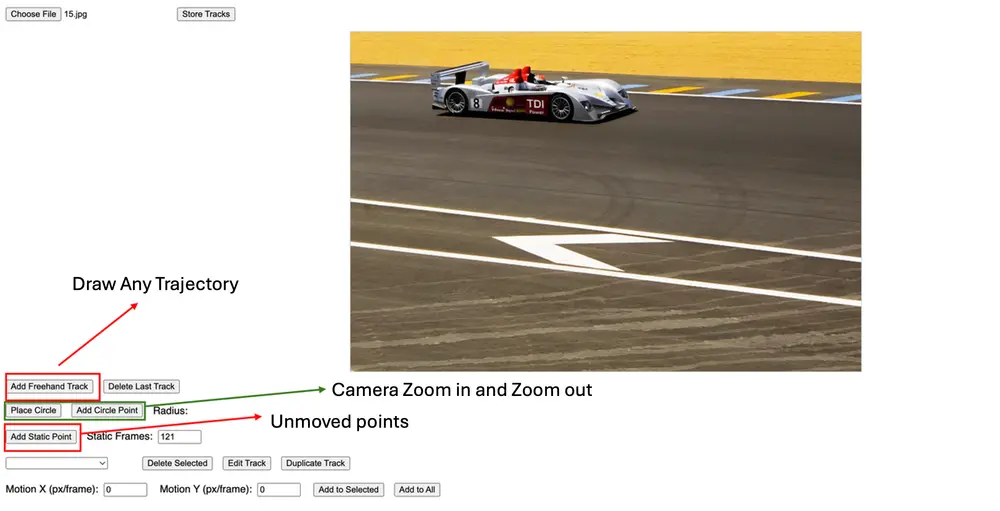
字节跳动推出全新视频生成框架 ATI:用“画轨迹”控制视频运动,对象、视角、局部变形一应俱全!字节跳动 AI 实验室发布了一项令人眼前一亮的视频生成技术 —— ATI(Any Trajectory Instruction),它让普通人也能通过“画轨迹”的方式,精准控制视频中物体的运动、镜头的移...视频模型# ATI# ATI-Wan2.1 14B# 字节跳动10个月前03850