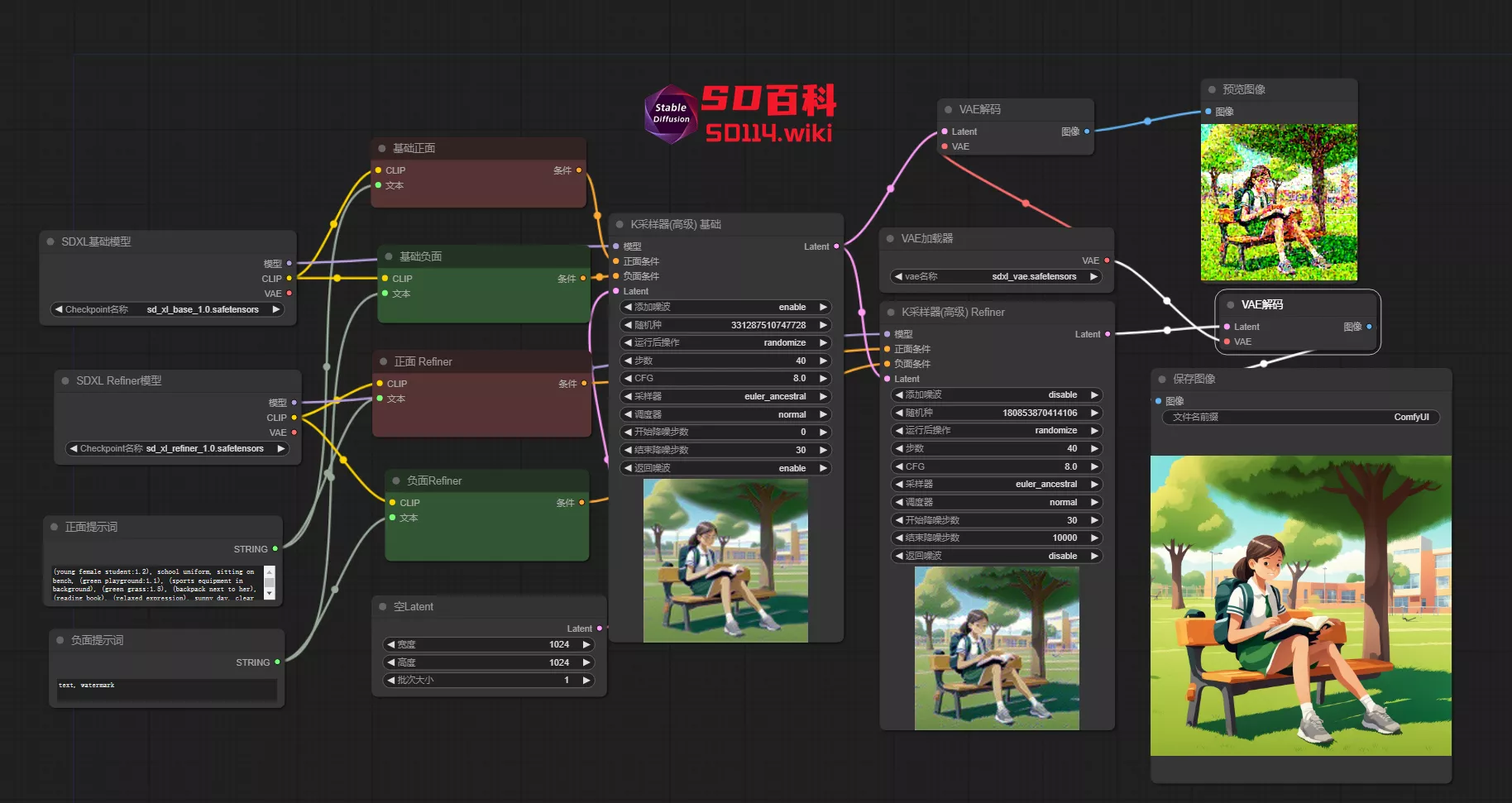
文生图
之前已经在界面(基础工作流创建)为大家讲解了如何创建最基础的工作流,但基础工作流只能加载SD1.5模型,那SDXL模型、Lora模型该如何在ComfyUI上运行呢?今天就来给大家讲解一下。
Lora
LoRA是微软技术人员于2021年为解决大语言模型微调而开发的一项技术,用于大语言模型在特定任务或领域上的高效适应,这是一种既节省资源又保持高性能的解决方案。更具体信息,请查看:Stable Diffusion绘画中常用的LoRA模型是什么?
在了解完基础工作流创建和LoRA模型后,LoRA模型的节点该如何添加呢?其实只需在基础工作流上添加一个LoRA模型加载节点即可,大家也不需要一步一步的添加,直接点击右侧面板的加载默认按钮,就会加载一个基础工作流。
1、添加 LoRA 节点
只需要右键 → 新建节点 →加载器→ LoRA加载器,即可添加 LoRA 节点
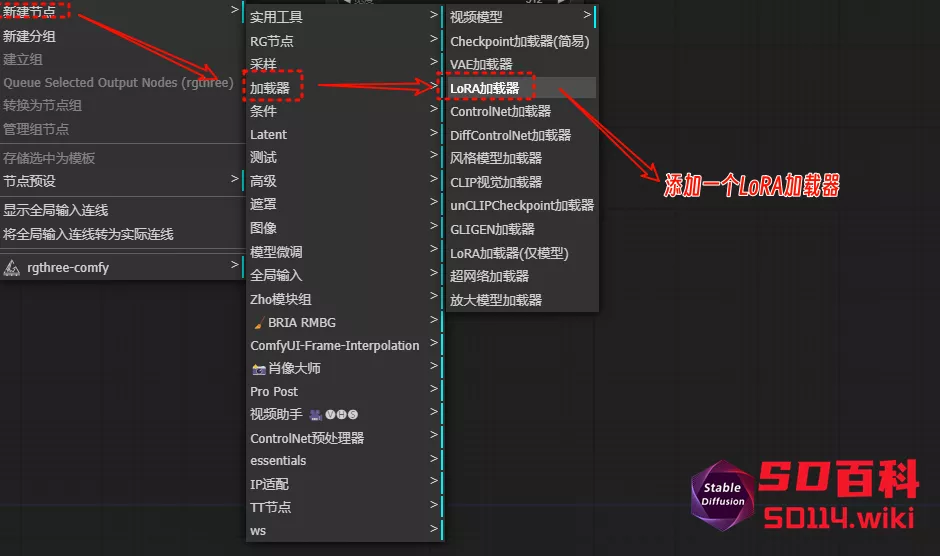
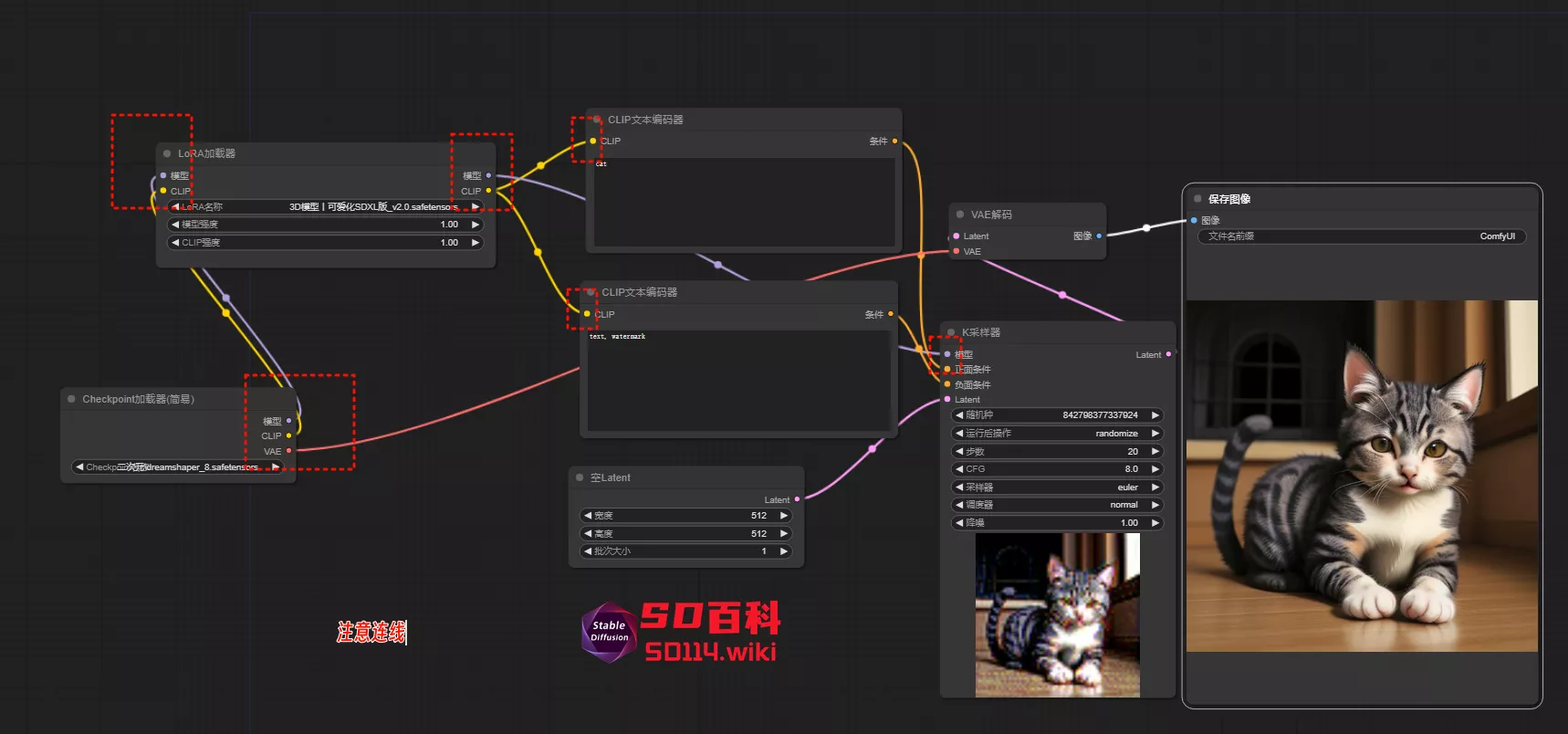
2、连接节点
节点左侧与 大模型相连,右侧与 CLIP 和 K采样器 相连,连线的规则也已经在界面(基础工作流创建)里为大家讲解过
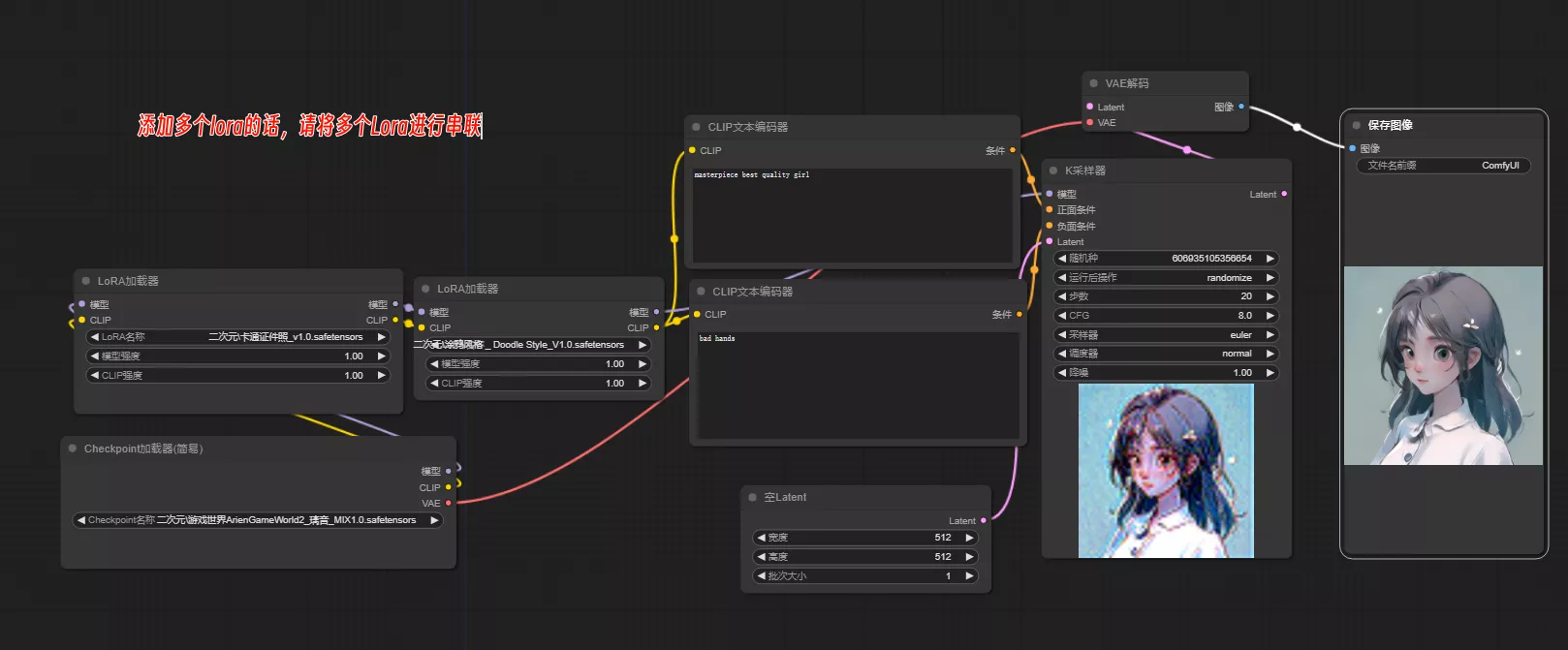
如果要添加多个Lora,请看下图,使用串联方法连接
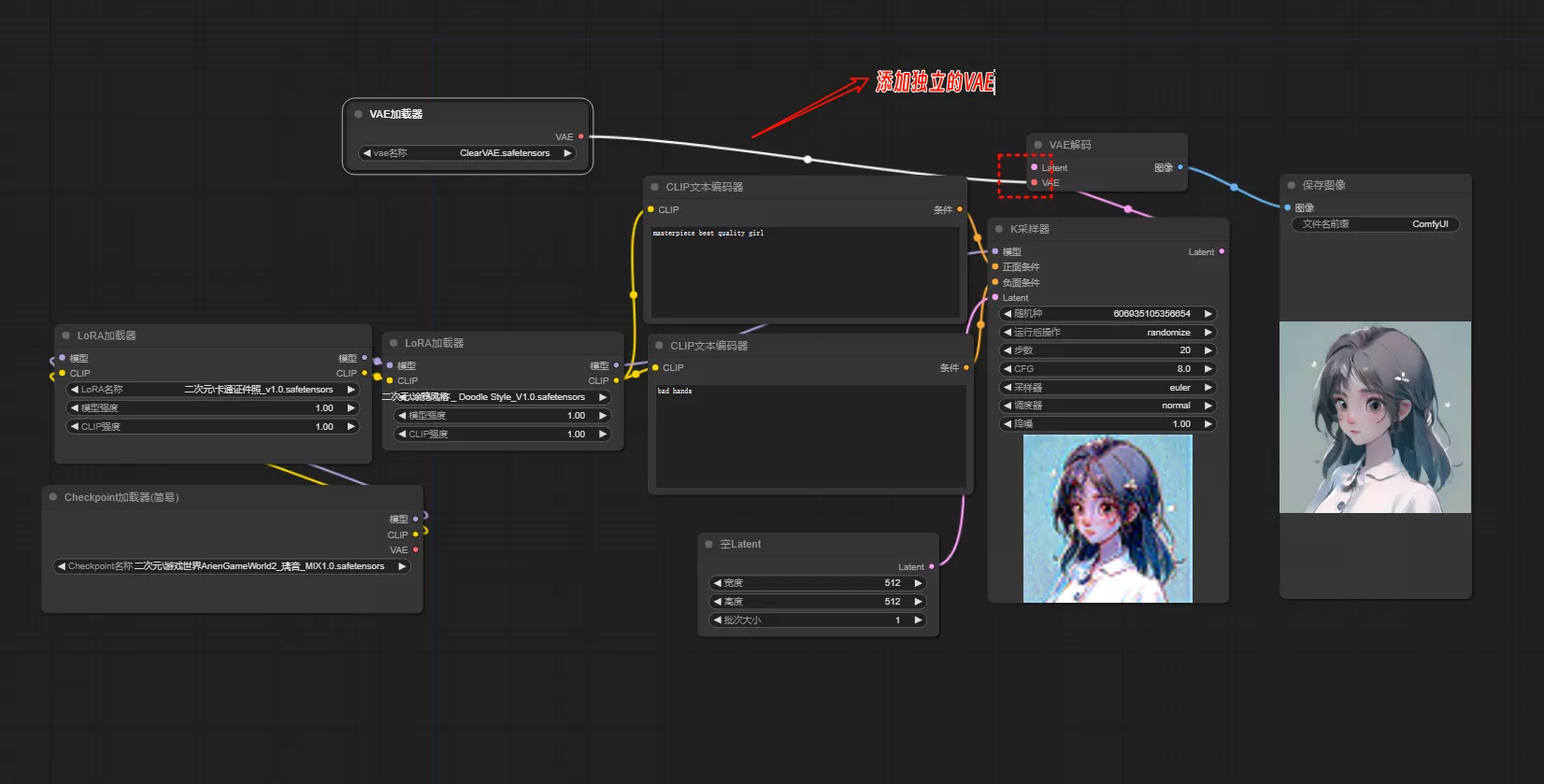
3、VAE
大家在下载LoRA模型的时候,请注意查看模型介绍,作者是否有推荐大家使用的大模型、LoRA和采样器,请根据作者的介绍来进行添加。
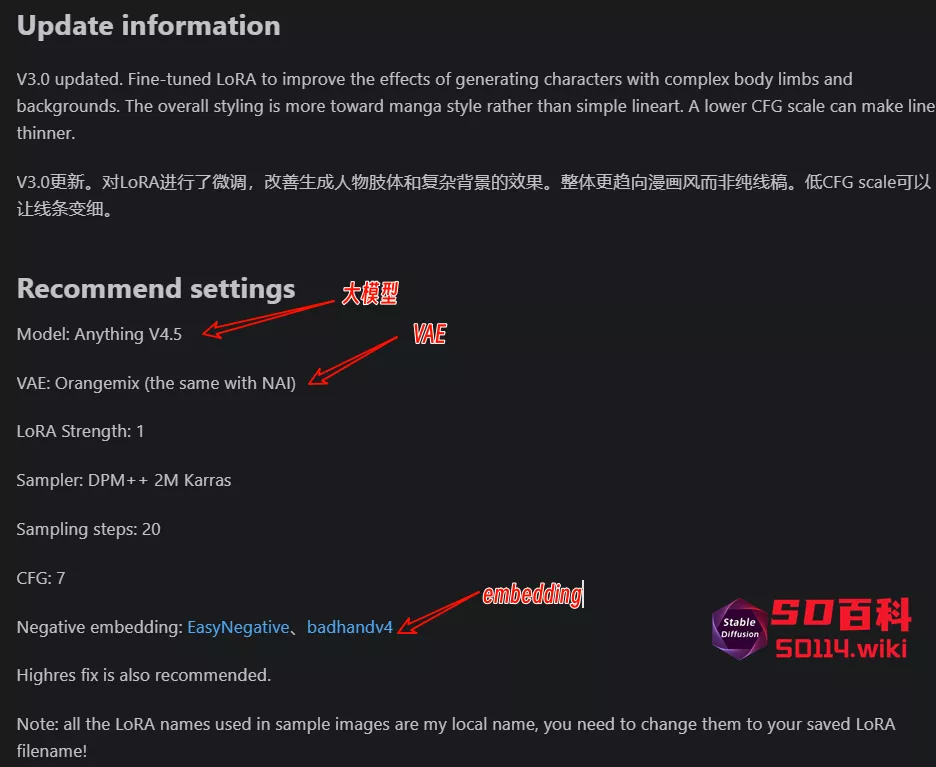
请根据LoRA作者的要求进行设置,如果有特殊VAE的要求,大家可以添加独立的VAE节点
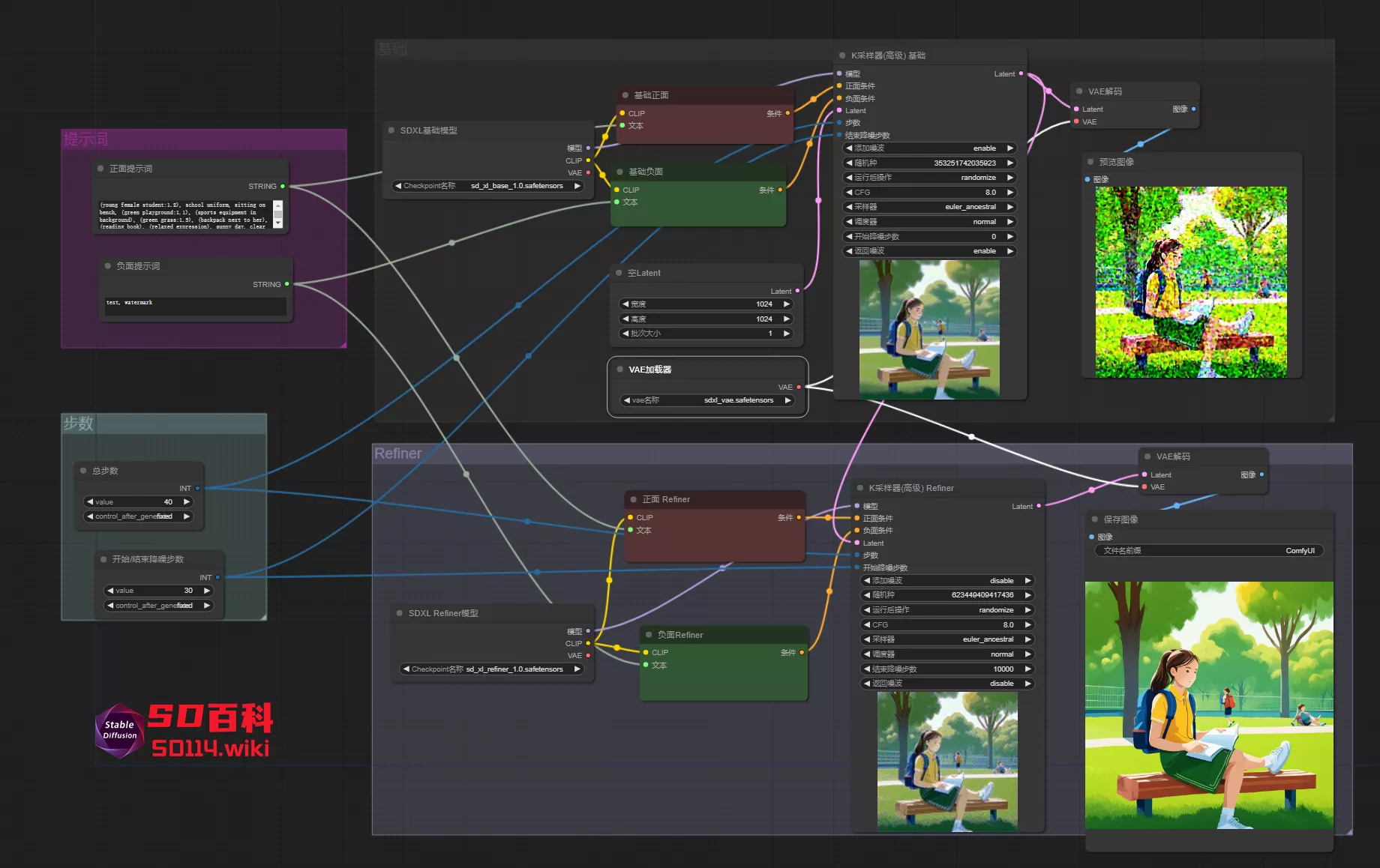
SDXL
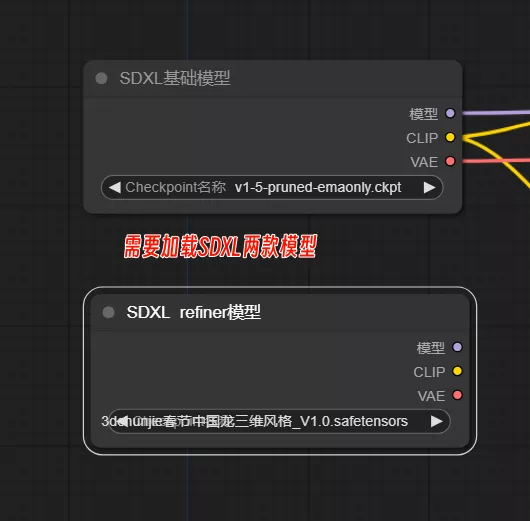
SDXL模型与SD1.5模型不同,他其实是由两个模型组成,具体可参考Stable Diffusion XL(SDXL),基础与细化(refiner)模型,不过目前很多第三方模型已经不需要refiner模型来进行细化,大家使用基础工作流就可以进行生图,不过还是要给大家细说一下怎么使用官方发布的SDXL如何在ComfyUI上使用。
一、加载 refiner 模型
加载基础工作流,在适当位置添加一个 Checkpoint 加载器,将节点标题更改为 refiner 模型
二、提示词输入
1、有了模型节点,接下来需要连接提示词。不仅基础模型需要连接提示词,refiner 细化也需要提示词作为基础,根据之前的连线规则,这时候就有问题了,总不能每次生图都要输入两次正反提示词吧?
2、因此我们需要输入一次提示词,就可以被两个模型使用,这时候我们就需要在“CLIP 文本编码器”上做一些改变
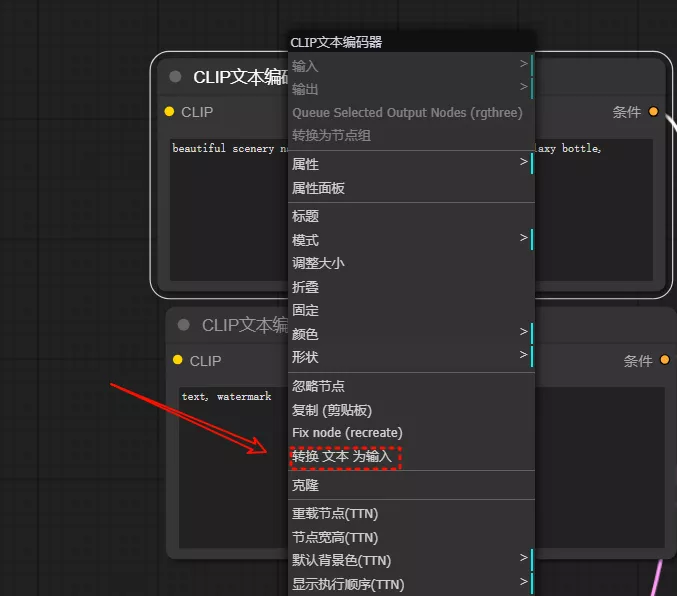
3、在“CLIP 文本编码器”上右键,选择“转换文本为输入”,这样我们就可以将文本输入框转换为文本节点,并传输内容到“CLIP 文本编码器”。
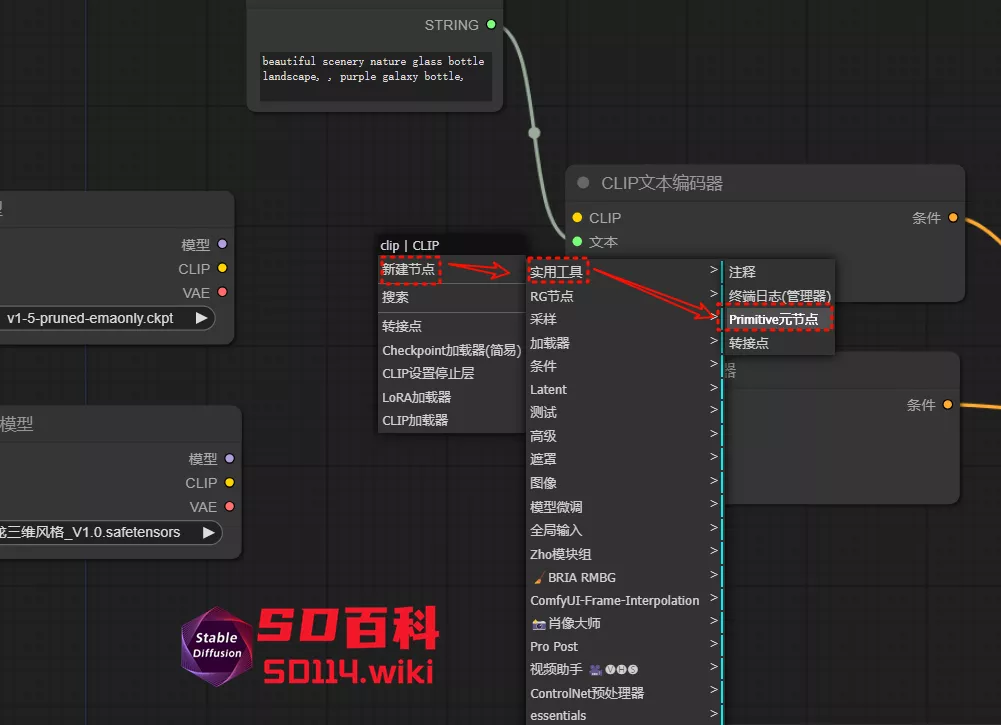
4、右键,选择“新建节点” -> “实用工具” -> “Primitive元节点”作为输入提示词的节点
5、连接“CLIP 文本编码器上的文本”和“Primitive 元节点”,这样之前输入的内容就会出现在“Primitive 元节点”上,并且还可以修改
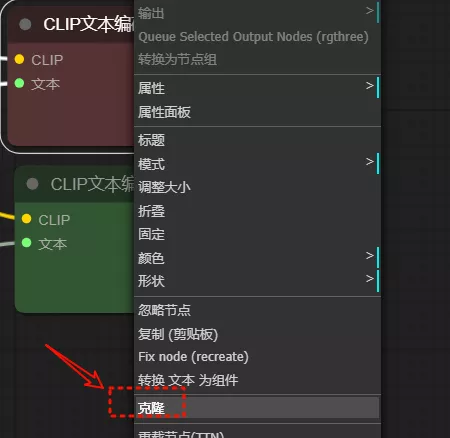
使用克隆,快速创建节点
6、将“Primitive 元节点”作为输出项,连接到另一组“CLIP 文本编码器”,然后克隆这两组“CLIP 文本编码器”连接到 refiner 模型。
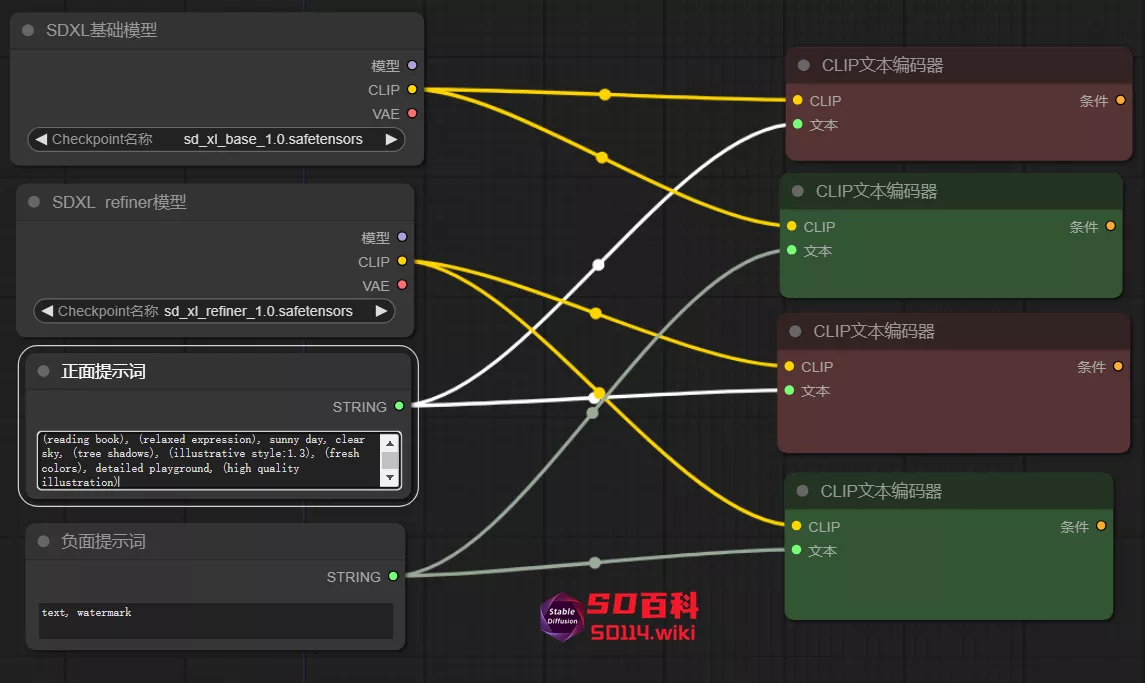
需要四个CLIP 文本编码器
三、K 采样器(高级)
1、在之前教程里已经提到,在采样器选择中,有两个选项:“K 采样器”和“K 采样器(高级)”。今天将讲解高级采样器的使用。
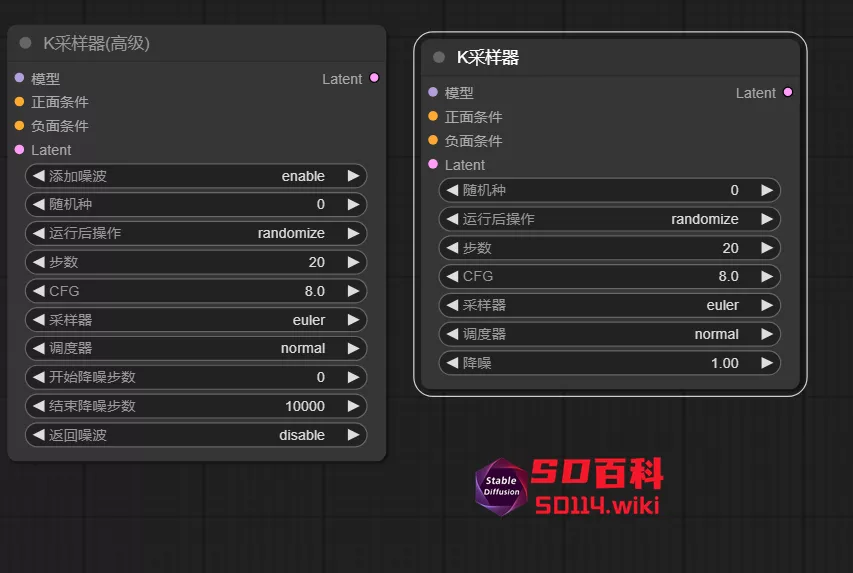
2、高级采样器具有“添加噪波、开始降噪步数、结束降噪步数、返回噪波”等选项,少了“降噪”选项。
- 添加噪波:控制是否生成随机种子。对于基础模型连接的采样器,启用此选项(enable);对于 refiner 模型连接的采样器,禁用此选项(disable)。(PS:refiner 模型是对生成的图片进行细化,因此种子应与 base 模型相同)
- 开始/结束降噪步数:定义从哪一步开始/结束降噪。对于 base 模型,通常从第 0 步开始;对于 refiner 模型,开始步数与 base 模型的结束步数相对应。(PS:总步数 40 步,base 模型的结束步数是30,那 refiner 模型的开始步数就是 30)
- 返回噪波:将随机种子返回给下一个采样器。对于 base 模型连接的采样器,启用此选项;对于 refiner 模型连接的采样器,禁用此选项。
3、连接采样器,并将 refiner 采样器的“Latent”与 base 采样器的输出“Latent”连接,创建一个设置图片尺寸的节点,连接到base 采样器
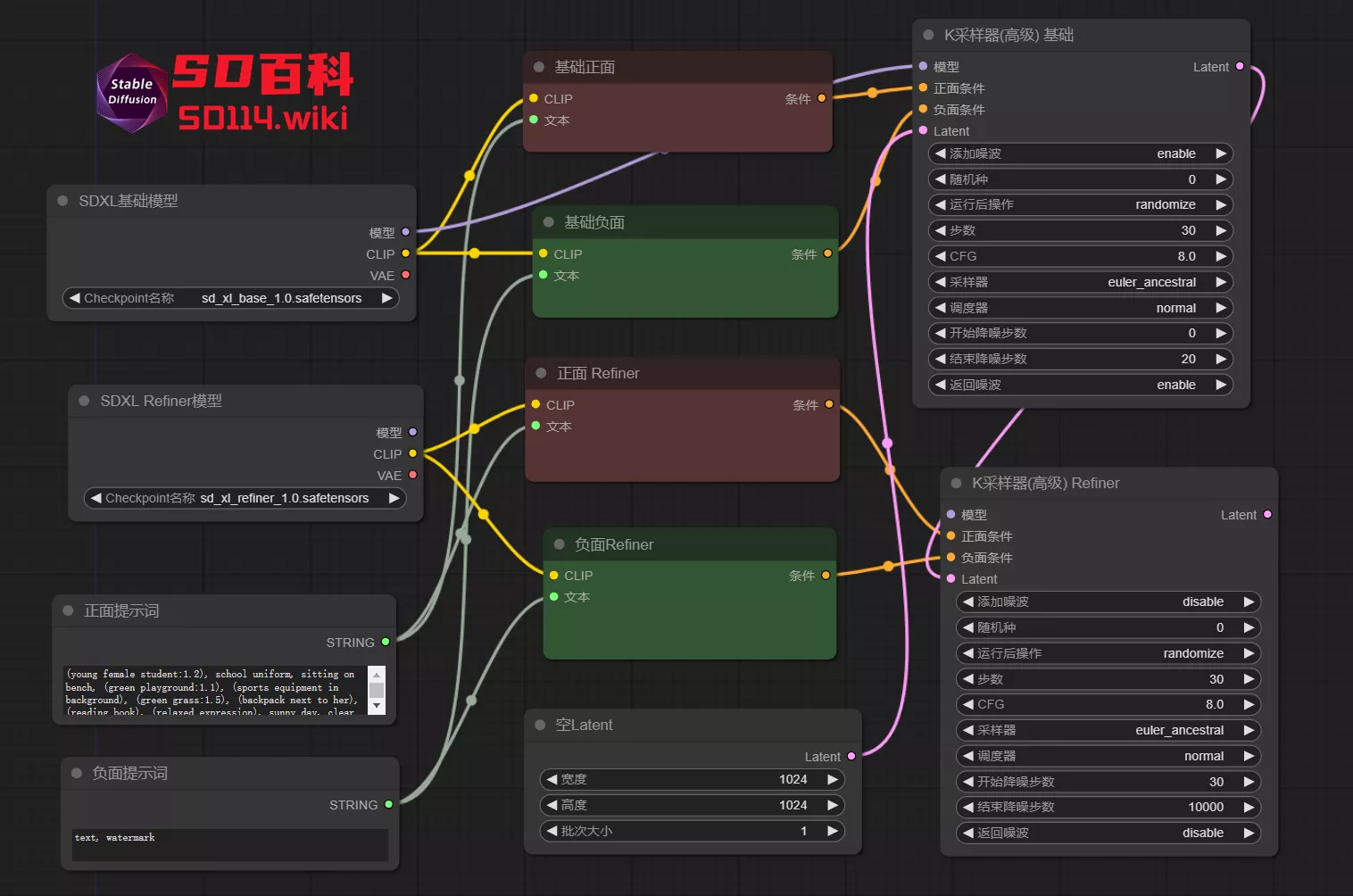
四、VAE 解码及保存图像
1、将 VAE 解码器与 refiner 采样器连接。可以选择连接任何大模型的 VAE端点,或使用“VAE 加载器”加载一个;连接完成后,运行流程以检查是否有错误。
 流程创建完毕后,检测是否有错误
流程创建完毕后,检测是否有错误
2、若要查看 base 模型连接的采样器生成的图像,可以在 base 采样器后连接一个“VAE 解码”和“预览图像”节点。使用“预览图像”是因为输出的图像可能带有噪点,直接保存会占用存储空间。
优化流程
1、提取共享参数
完成SDXL的流程创建后,您可能会发现在两个采样器上都需要输入总步数、开始降噪步数、结束降噪步数等参数,这显得很繁琐。为了简化此过程,我们可以将这些共享参数提取出来,以实现更高效的参数管理。
2、统一输入数值
观察上述六个数值,我们发现两个总步数应该是相同的,而 base 采样器的结束降噪步数与 refiner 采样器的开始降噪步数也应该保持一致。因此,我们可以将这两组数值统一进行输入。
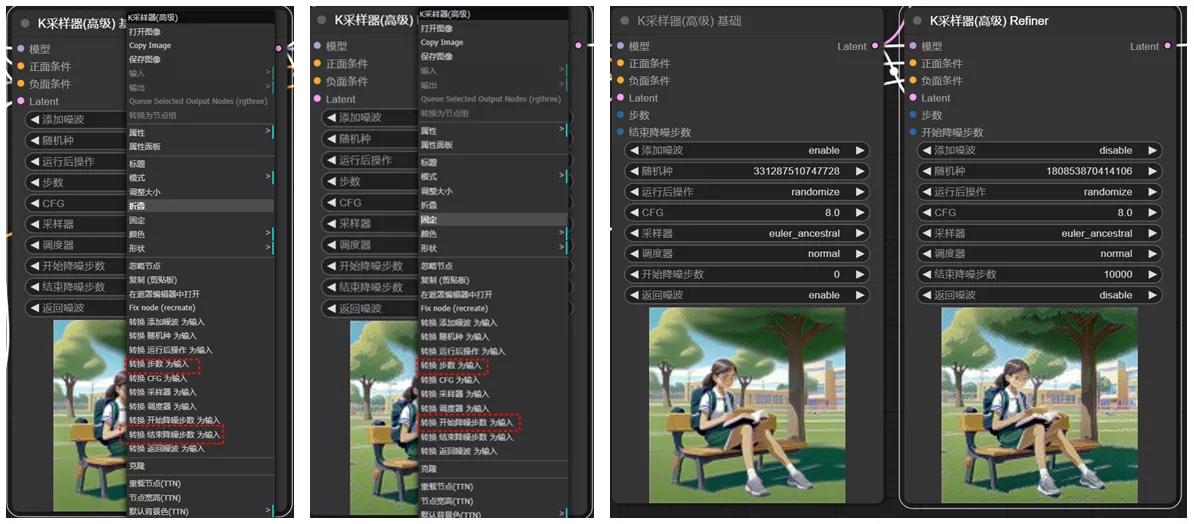
3、 转换参数为输入
- 在 base 采样器上,右键点击并选择“转换步数为输入”和“转换结束降噪步数为输入”。
- 在 refiner 采样器上,同样右键点击并选择“转换步数为输入”和“转换开始降噪步数为输入”。
这样,我们就将这些参数转换为了可输入的节点,使得参数的调整变得更加灵活和方便。
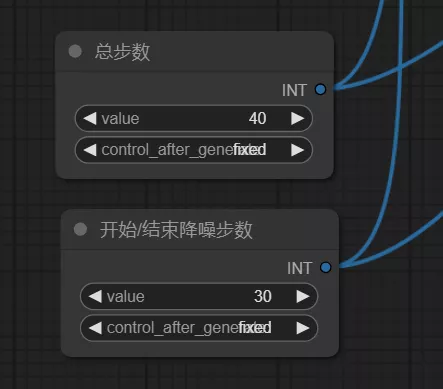
4、 创建输入节点
- 接下来,我们需要创建两个“Primitive元节点”作为输入节点。这可以通过右键点击并选择“新建节点” -> “实用工具” -> “Primitive元节点”来完成。
- 创建好两个输入节点后,一个用于连接步数,另一个用于连接结束/开始降噪步数。
5、完成与保存
- 如果你觉得线条和布局过于混乱,可以新建分组,对节点进行分组,让整个工作流更加清晰明了
- 最后,请记得保存您的工作流,以便下次使用时可以直接加载,无需重复上述步骤。