QWen-VL in ComfyUI:使用通义千问视觉理解模型进行图生图
此插件是将通义千问视觉理解模型 QWen-VL 双模型(Plus & Max)通过 API 调用引入到 ComfyUI 中,让大家可以在ComfyUI中使用QWen-VL来识图并应用于图生图。
目前 QWen-VL API 限免,你可以在这里申请一个自己的 API Key进行使用:
关于通义千问视觉理解模型 Qwen-VL具体可查看:通义千问视觉理解模型 Qwen-VL升级版:Qwen-VL-Plus、Qwen-VL-Max
插件安装
1、使用管理器 ComfyUI Manager 安装
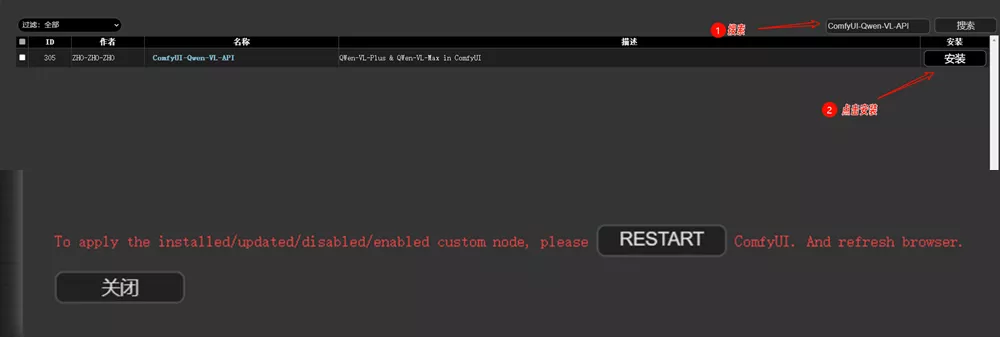
2、手动安装
在ComfyUI安装文件夹,使用以下命令进行安装:
cd custom_nodes
git clone https://github.com/ZHO-ZHO-ZHO/ComfyUI-Qwen-VL-API.git
cd custom_nodes/ComfyUI-Qwen-VL-API
pip install -r requirements.txt无论是管理器还是手动安装,插件安装完毕后,都需要重启 ComfyUI
工作流
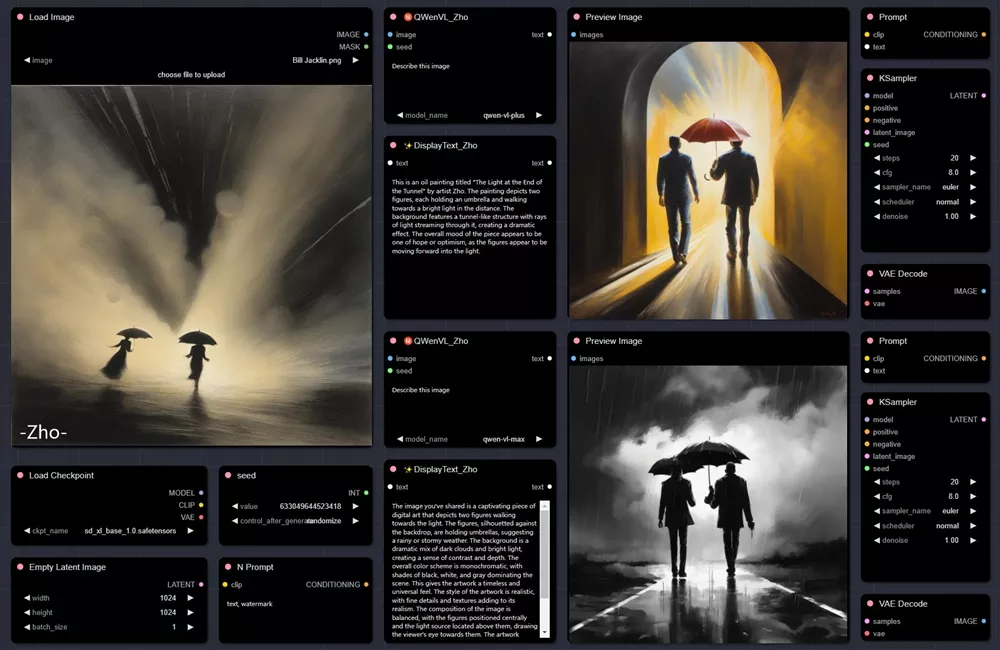
开发者已经内置了工作流,将此文件夹ComfyUI\custom_nodes\ComfyUI-Qwen-VL-API下的json文件拖入ComfyUI界面即可打开工作流。
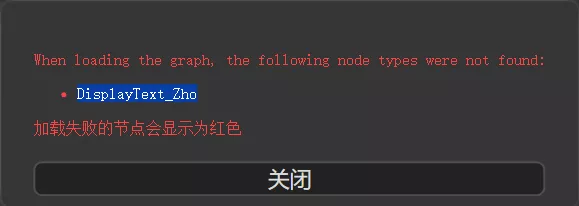
👇如果缺少节点,请使用ComfyUI管理器管理器的安装缺失节点来安装插件
使用方法
按照阿里云官方指引去申请API key,将申请到的API key添加到 config.json 文件中,运行时会自动加载

节点说明
此插件主要提供了两种节点(均采用隐式 API KEY):
- QWenVL_Zho:同时支持两种模型,接受本地图像作为输入(图像仅临时储存用完会自动清除)
- QWenVL_Chat_Zho:同时支持两种模型,支持上下文窗口,接受本地图像作为输入(图像储存在 /custom nodes/ComfyUI-Qwen-VL-API/qw 文件夹中,可手动清理)
参数说明
- image:接入本地图像
- prompt:提示词
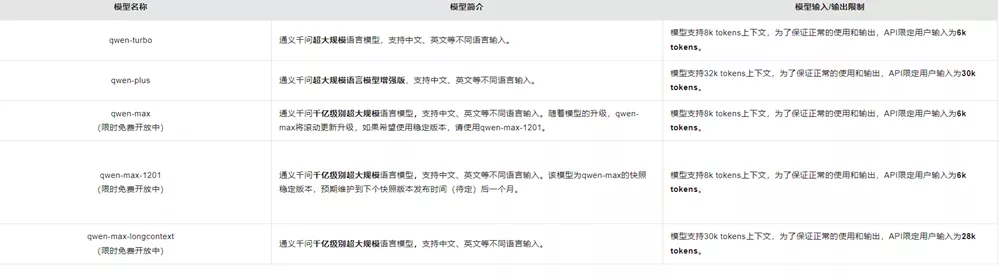
- model_name:模型选择,QWen-VL-Plus 或 QWen-VL-Max(需要注意,目前限免的是QWen-VL-Max)
- seed:随机种子
开发者给出的工作流使用的是QWenVL_Zho,加载工作流后,上传或者拖入图片,然后进行图生图相关设置,即可点击添加到提示词队列开始生图。
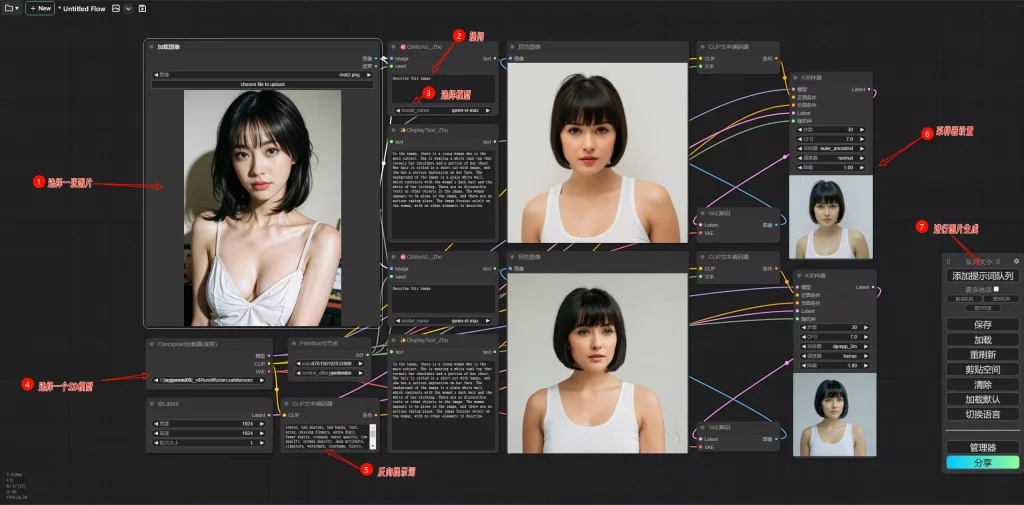
建议将生成图片的尺寸设置成与上传图片相同比例,大家也可以在开发者分享的工作流基础上进一步删减节点,进行更简单或复杂的生图设置。







